Stable Diffusion扩散模型
人像生成模型
1.模型理论基础
扩散模型(Diffusion Model):
1.1 Diffusion Model 原理

- 首先,Denoise Model 需要一个起始的噪声图像作为输入。这个噪声图像可以是完全随机的,也可以是一些特定的模式(如 高斯分布)或者形状。 - 接下来,随着 denoise 的不断进行,图像的细节信息会逐渐浮现出来。这个过程有点像冲洗照片,每次冲洗都会逐渐浮现出照片中的细节和色彩。denoise 的次数越多,生成的图像就越清晰、越细腻。 - 最后,Denoise Model 会根据用户的需求输出最终的图像。

Denoise 过程中,用的都是同一个 Denoise Model。为了让 Diffusion Model 知道当前是在哪个 Step 输入的图片,实际操作过程中会把 Step 数字作为输入传递给模型。这样,模型就能够根据当前的 Step 来判断图像的噪声程度,从而进行更加精细的去噪操作。
1.2 Denoise Model 的内部

实际上,Denoise Model 内部做了一些非常有趣的事情来生成高质量的图像。 首先,由于让模型直接预测出去噪后的图片是比较困难的事情,所以 Denoise Model 做了两件事情: - 首先,它会把噪音图片和当前的 Step 一起输入到一个叫做 Noise Predicter 的模块中,这个模块会预测出当前图片的噪音。 - 接下来,模型会对初步的去噪图片进行修正,以达到去噪效果。具体来说,模型会通过像素值减去噪音的方式来进一步去除噪音。
1.3 如何训练 Noise Predictor?

要训练 Noise Predictor,我们需要有 Ground truth 的噪音作为 label 进行有监督的学习。那么,各个 Step 的 Ground truth 从哪里来呢?
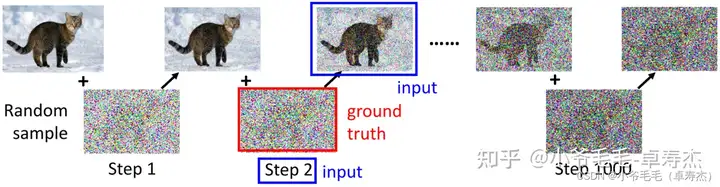
我们可以通过随机产生噪音的方式来模拟扩散过程(Diffusion Process)。具体来说,我们从原始图像开始,不断地加入随机噪音,得到一系列加噪后的图像。这些加噪后的图像和当前的 Step 就是 Denoise Model 的输入,而加入的噪音则是 Ground truth。我们可以用这些 Ground truth 数据来训练 Noise Predictor,以便它能够更好地预测出当前图像的噪音。
1.4 Text-to-Image
有些同学问了:我见到的 Diffusion Model是Text-to-image Generator,基于文本生成图片。为什么你这个没有文本的输入呢?

确实,有些 Diffusion Model 是基于文本生成图片的,这意味着我们可以将文本作为输入来生成图片。
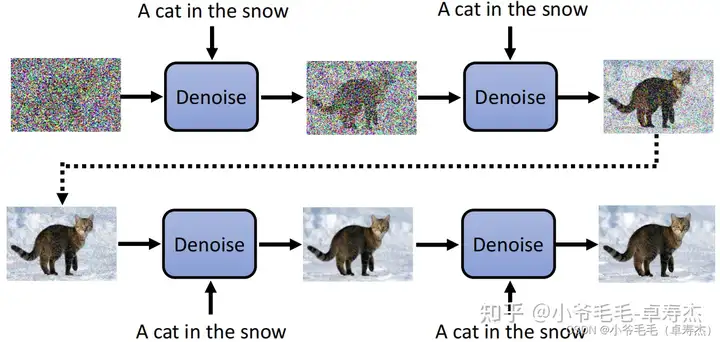
每一个 step,文本都可以作为 Denoise Model 的输入,这样可以让模型知道当前应该生成什么样的图片。


具体来说,我们可以将文本输入到 Noise Predictor 中,以便预测出噪音来去噪。
Stable Diffusion扩散模型的更多相关文章
- 一文详解扩散模型:DDPM
作者:京东零售 刘岩 扩散模型讲解 前沿 人工智能生成内容(AI Generated Content,AIGC)近年来成为了非常前沿的一个研究方向,生成模型目前有四个流派,分别是生成对抗网络(Gene ...
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题.目前超过数十亿以上参数的具有强能力的大 ...
- Hugging Face 每周速递: 扩散模型课程完成中文翻译,有个据说可以教 ChatGPT 看图的模型开源了
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之使用篇
目录 界面参数 采样器 文生图(txt2img) 图生图(img2img) 模型下载 界面参数 在使用 Stable Diffusion 开源 AI 绘画之前,需要了解一下绘画的界面和一些参数的意义 ...
- 在英特尔 CPU 上加速 Stable Diffusion 推理
前一段时间,我们向大家介绍了最新一代的 英特尔至强 CPU (代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的 ...
- AI绘画提示词创作指南:DALL·E 2、Midjourney和 Stable Diffusion最全大比拼 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 从 GPT2 到 Stable Diffusion:Elixir 社区迎来了 Hugging Face
上周,Elixir 社区向大家宣布,Elixir 语言社区新增从 GPT2 到 Stable Diffusion 的一系列神经网络模型.这些模型得以实现归功于刚刚发布的 Bumblebee 库.Bum ...
- Stable Diffusion魔法入门
写在前面 本文为资料整合,没有原创内容,方便自己查找和学习, 花费了一晚上把sd安装好,又花了大半天了解sd周边的知识,终于体会到为啥这些生成式AI被称为魔法了,魔法使用前要吟唱类比到AI上不就是那些 ...
- Diffusers中基于Stable Diffusion的哪些图像操作
目录 辅助函数 Text-To-Image Image-To-Image In-painting Upscale Instruct-Pix2Pix 基于Stable Diffusion的哪些图像操作们 ...
- Stable Diffusion 关键词tag语法教程
提示词 Prompt Prompt 是输入到文生图模型的文字,不同的 Prompt 对于生成的图像质量有较大的影响 支持的语言Stable Diffusion, NovelAI等模型支持的输入语言为英 ...
随机推荐
- 新一代开源流数据湖平台Apache Paimon入门实操-上
@ 目录 概述 定义 核心功能 适用场景 架构原理 总体架构 统一存储 基本概念 文件布局 部署 环境准备 环境部署 实战 Catalog 文件系统 Hive Catalog 创建表 创建Catalo ...
- Nginx 文件名逻辑漏洞(CVE-2013-4547)(Vulhub)
Nginx 文件名逻辑漏洞(CVE-2013-4547)(Vulhub) 漏洞简介 在Nginx 0.8.41 ~ 1.4.3 / 1.5.0 ~ 1.5.7版本中存在错误解析用户请求的url信息,从 ...
- 线程方法接收参数和返回参数,Java的两种线程实现方式对比
The difference beteen two way 总所周知,Java实现多线程有两种方式,分别是继承Thread类和实现Runable接口,那么它们的区别是什么? 继承 Thread 类: ...
- github.com/yuin/gopher-lua 踩坑日记
本文主要记录下在日常开发过程中, 使用 github.com/yuin/gopher-lua 过程中需要注意的地方. 后续遇到其他的需要注意的事项再补充. 1.加载LUA_PATH环境变量 在实际开发 ...
- 通过商品API接口获取到数据后的分析和应用
一.如果你想要分析商品API接口获取到的数据,可以按照如下的步骤进行: 了解API接口返回值的格式,如JSON格式.XML格式.CSV格式等,选择适合你的数据分析方式. 使用API请求工具(如Post ...
- Python 遍历字典的若干方法
哈喽大家好,我是咸鱼 我们知道字典是 Python 中最重要且最有用的内置数据结构之一,它们无处不在,是语言本身的基本组成部分 我们可以使用字典来解决许多编程问题,那么今天我们就来看看如何在 Pyth ...
- 【译】在 Visual Studio 2022 中安全地在 HTTP 请求中使用机密
在 Visual Studio 2022 的17.8 Preview 1版本中,我们更新了 HTTP 文件编辑器,使您能够外部化变量,从而使跨不同环境的 Web API 测试更容易.此更新还包括以安全 ...
- Unity 性能优化之Shader分析处理函数ShaderUtil.HasProceduralInstancing: 深入解析与实用案例
Unity 性能优化之Shader分析处理函数ShaderUtil.HasProceduralInstancing: 深入解析与实用案例 点击封面跳转到Unity国际版下载页面 简介 在Unity中, ...
- Python比较字符串格式类型时间大小
已知的格式是 06/24/2021 15:47:01.491 时间比较的思路是,把数据转换成时间戳比较: 第一步是把 06/24/2021 15:47:01.491 格式转换称 2021-06-24 ...
- Python网络编程——TCP套接字通信、通信循环、链接循环、UDP通信
文章目录 基于TCP的套接字通信 加上通信循环 加上链接循环 基于UDP协议的套接字通信 基于TCP的套接字通信 以买手机的过程为例 服务端代码 import socket # 1.买手机 phone ...