Stable Diffusion扩散模型
人像生成模型
1.模型理论基础
扩散模型(Diffusion Model):
1.1 Diffusion Model 原理

- 首先,Denoise Model 需要一个起始的噪声图像作为输入。这个噪声图像可以是完全随机的,也可以是一些特定的模式(如 高斯分布)或者形状。 - 接下来,随着 denoise 的不断进行,图像的细节信息会逐渐浮现出来。这个过程有点像冲洗照片,每次冲洗都会逐渐浮现出照片中的细节和色彩。denoise 的次数越多,生成的图像就越清晰、越细腻。 - 最后,Denoise Model 会根据用户的需求输出最终的图像。

Denoise 过程中,用的都是同一个 Denoise Model。为了让 Diffusion Model 知道当前是在哪个 Step 输入的图片,实际操作过程中会把 Step 数字作为输入传递给模型。这样,模型就能够根据当前的 Step 来判断图像的噪声程度,从而进行更加精细的去噪操作。
1.2 Denoise Model 的内部

实际上,Denoise Model 内部做了一些非常有趣的事情来生成高质量的图像。 首先,由于让模型直接预测出去噪后的图片是比较困难的事情,所以 Denoise Model 做了两件事情: - 首先,它会把噪音图片和当前的 Step 一起输入到一个叫做 Noise Predicter 的模块中,这个模块会预测出当前图片的噪音。 - 接下来,模型会对初步的去噪图片进行修正,以达到去噪效果。具体来说,模型会通过像素值减去噪音的方式来进一步去除噪音。
1.3 如何训练 Noise Predictor?

要训练 Noise Predictor,我们需要有 Ground truth 的噪音作为 label 进行有监督的学习。那么,各个 Step 的 Ground truth 从哪里来呢?
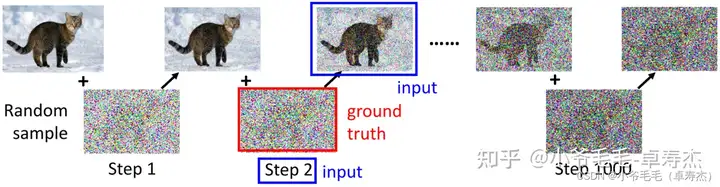
我们可以通过随机产生噪音的方式来模拟扩散过程(Diffusion Process)。具体来说,我们从原始图像开始,不断地加入随机噪音,得到一系列加噪后的图像。这些加噪后的图像和当前的 Step 就是 Denoise Model 的输入,而加入的噪音则是 Ground truth。我们可以用这些 Ground truth 数据来训练 Noise Predictor,以便它能够更好地预测出当前图像的噪音。
1.4 Text-to-Image
有些同学问了:我见到的 Diffusion Model是Text-to-image Generator,基于文本生成图片。为什么你这个没有文本的输入呢?

确实,有些 Diffusion Model 是基于文本生成图片的,这意味着我们可以将文本作为输入来生成图片。
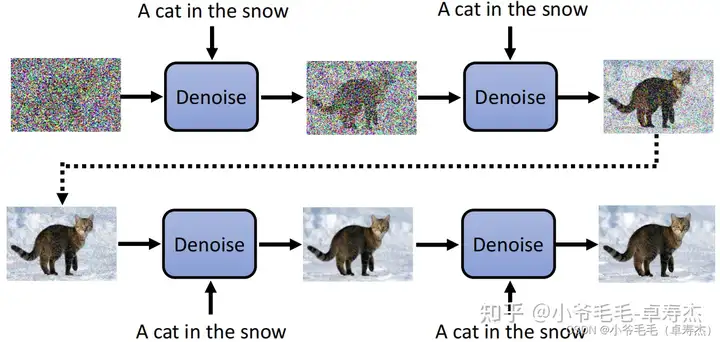
每一个 step,文本都可以作为 Denoise Model 的输入,这样可以让模型知道当前应该生成什么样的图片。


具体来说,我们可以将文本输入到 Noise Predictor 中,以便预测出噪音来去噪。
Stable Diffusion扩散模型的更多相关文章
- 一文详解扩散模型:DDPM
作者:京东零售 刘岩 扩散模型讲解 前沿 人工智能生成内容(AI Generated Content,AIGC)近年来成为了非常前沿的一个研究方向,生成模型目前有四个流派,分别是生成对抗网络(Gene ...
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题.目前超过数十亿以上参数的具有强能力的大 ...
- Hugging Face 每周速递: 扩散模型课程完成中文翻译,有个据说可以教 ChatGPT 看图的模型开源了
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之使用篇
目录 界面参数 采样器 文生图(txt2img) 图生图(img2img) 模型下载 界面参数 在使用 Stable Diffusion 开源 AI 绘画之前,需要了解一下绘画的界面和一些参数的意义 ...
- 在英特尔 CPU 上加速 Stable Diffusion 推理
前一段时间,我们向大家介绍了最新一代的 英特尔至强 CPU (代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的 ...
- AI绘画提示词创作指南:DALL·E 2、Midjourney和 Stable Diffusion最全大比拼 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 从 GPT2 到 Stable Diffusion:Elixir 社区迎来了 Hugging Face
上周,Elixir 社区向大家宣布,Elixir 语言社区新增从 GPT2 到 Stable Diffusion 的一系列神经网络模型.这些模型得以实现归功于刚刚发布的 Bumblebee 库.Bum ...
- Stable Diffusion魔法入门
写在前面 本文为资料整合,没有原创内容,方便自己查找和学习, 花费了一晚上把sd安装好,又花了大半天了解sd周边的知识,终于体会到为啥这些生成式AI被称为魔法了,魔法使用前要吟唱类比到AI上不就是那些 ...
- Diffusers中基于Stable Diffusion的哪些图像操作
目录 辅助函数 Text-To-Image Image-To-Image In-painting Upscale Instruct-Pix2Pix 基于Stable Diffusion的哪些图像操作们 ...
- Stable Diffusion 关键词tag语法教程
提示词 Prompt Prompt 是输入到文生图模型的文字,不同的 Prompt 对于生成的图像质量有较大的影响 支持的语言Stable Diffusion, NovelAI等模型支持的输入语言为英 ...
随机推荐
- Maven资源导出问题所需配置
<!--在build中配置resources,来防止我们资源导出失败的问题--> <build> <resources> <resource> < ...
- linux测试ipv6
前言 操作系统版本:centos 7.6 curl版本:7.87(centos 7自带的curl版本是7.29,测ipv6会有问题) 系统开启ipv6 centos 7默认开启 ipv6,可检查net ...
- [kvm]cpu内存硬盘配置
修改CPU配置 如果配置了最大CPU # 临时 virsh setvcpus test 2 # 永久 virsh setvcpus test 2 --config 热增加虚拟机的CPU数后,使用lsc ...
- Jenkins用户管理(二):不同用户分配不同的任务访问权限
需求:不同用户访问到不同的Jenkins任务. 依赖插件:Role-based Authorization Strategy 1. 插件安装 进入[系统管理]-[插件管理]-[可用插件],搜索Role ...
- CF-1860C Game on Permutation题解
题意:在一条数轴上,Alice可以跳到在你所在点前面且值比当前所在点小的点.每回合可以向任意符合要求的点跳一次.当轮到Alice的回合同时不存在符合要求的点,Alice就赢了.Alice可以选择一个点 ...
- vue3+vite2动态绑定图片优雅解决方案
优雅解决方案在最下面,小伙伴们儿可以直接前往 背景 在vue3+vite2项目中,我们有时候想要动态绑定资源,比如像下面的代码这样: <template> <div> < ...
- Unity UGUI的Toggle(复选框)组件的介绍及使用
Unity UGUI的Toggle(复选框)组件的介绍及使用 1. 什么是Toggle组件? Toggle(复选框)是Unity UGUI中的一个常用组件,用于实现复选框的功能.它可以被选中或取消选中 ...
- OptiX8入门(一)optixHello
本人初学者,如有错误和更好的表述,请指出 环境:CLion+VS2022+CUDA Toolkit 12.0.1+OptiX8 下载好后打开SDK就可以看到OptiX官方提供的许多例子,CMake配置 ...
- python入门基础(13)--类、对象
面向过程的编程语言,如C语言,所使用的数据和函数之间是没有任何直接联系的,它们之间是通过函数调用提供参数的形式将数据传入函数进行处理. 但可能因为错误的传递参数.错误地修改了数据而导致程序出错,甚至是 ...
- 【matplotlib基础】--几何图形
除了绘制各类分析图形(比如柱状图,折线图,饼图等等)以外,matplotlib 也可以在画布上任意绘制各类几何图形.这对于计算机图形学.几何算法和计算机辅助设计等领域非常重要. matplitlib ...