神经网络优化篇:如何理解 dropout(Understanding Dropout)
理解 dropout
Dropout可以随机删除网络中的神经单元,为什么可以通过正则化发挥如此大的作用呢?
直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的\(L2\)正则化类似;实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;\(L2\)对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
总结一下,dropout的功能类似于\(L2\)正则化,与\(L2\)正则化不同的是应用方式不同会带来一点点小变化,甚至更适用于不同的输入范围。

第二个直观认识是,从单个神经元入手,如图,这个单元的工作就是输入并生成一些有意义的输出。通过dropout,该单元的输入几乎被消除,有时这两个单元会被删除,有时会删除其它单元,就是说,用紫色圈起来的这个单元,它不能依靠任何特征,因为特征都有可能被随机清除,或者说该单元的输入也都可能被随机清除。不愿意把所有赌注都放在一个节点上,不愿意给任何一个输入加上太多权重,因为它可能会被删除,因此该单元将通过这种方式积极地传播开,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲过的\(L2\)正则化类似,实施dropout的结果是它会压缩权重,并完成一些预防过拟合的外层正则化。
事实证明,dropout被正式地作为一种正则化的替代形式,\(L2\)对不同权重的衰减是不同的,它取决于倍增的激活函数的大小。
总结一下,dropout的功能类似于\(L2\)正则化,与\(L2\)正则化不同的是,被应用的方式不同,dropout也会有所不同,甚至更适用于不同的输入范围。
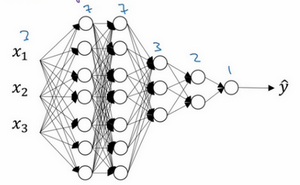
实施dropout的另一个细节是,这是一个拥有三个输入特征的网络,其中一个要选择的参数是keep-prob,它代表每一层上保留单元的概率。所以不同层的keep-prob也可以变化。第一层,矩阵\(W^{[1]}\)是7×3,第二个权重矩阵\(W^{[2]}\)是7×7,第三个权重矩阵\(W^{[3]}\)是3×7,以此类推,\(W^{[2]}\)是最大的权重矩阵,因为\(W^{[2]}\)拥有最大参数集,即7×7,为了预防矩阵的过拟合,对于这一层,认为这是第二层,它的keep-prob值应该相对较低,假设是0.5。对于其它层,过拟合的程度可能没那么严重,它们的keep-prob值可能高一些,可能是0.7,这里是0.7。如果在某一层,不必担心其过拟合的问题,那么keep-prob可以为1,为了表达清除,用紫色线笔把它们圈出来,每层keep-prob的值可能不同。
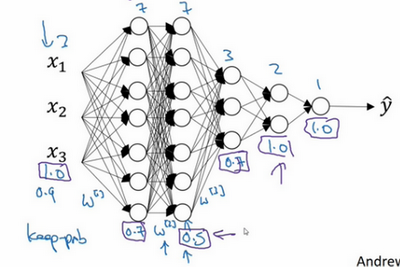
注意keep-prob的值是1,意味着保留所有单元,并且不在这一层使用dropout,对于有可能出现过拟合,且含有诸多参数的层,可以把keep-prob设置成比较小的值,以便应用更强大的dropout,有点像在处理\(L2\)正则化的正则化参数\(\lambda\),尝试对某些层施行更多正则化,从技术上讲,也可以对输入层应用dropout,有机会删除一个或多个输入特征,虽然现实中通常不这么做,keep-prob的值为1,是非常常用的输入值,也可以用更大的值,或许是0.9。但是消除一半的输入特征是不太可能的,如果遵守这个准则,keep-prob会接近于1,即使对输入层应用dropout。
总结一下,如果担心某些层比其它层更容易发生过拟合,可以把某些层的keep-prob值设置得比其它层更低,缺点是为了使用交叉验证,要搜索更多的超级参数,另一种方案是在一些层上应用dropout,而有些层不用dropout,应用dropout的层只含有一个超级参数,就是keep-prob。
结束前分享两个实施过程中的技巧,实施dropout,在计算机视觉领域有很多成功的第一次。计算视觉中的输入量非常大,输入太多像素,以至于没有足够的数据,所以dropout在计算机视觉中应用得比较频繁,有些计算机视觉研究人员非常喜欢用它,几乎成了默认的选择,但要牢记一点,dropout是一种正则化方法,它有助于预防过拟合,因此除非算法过拟合,不然是不会使用dropout的,所以它在其它领域应用得比较少,主要存在于计算机视觉领域,因为通常没有足够的数据,所以一直存在过拟合,这就是有些计算机视觉研究人员如此钟情于dropout函数的原因。直观上认为不能概括其它学科。
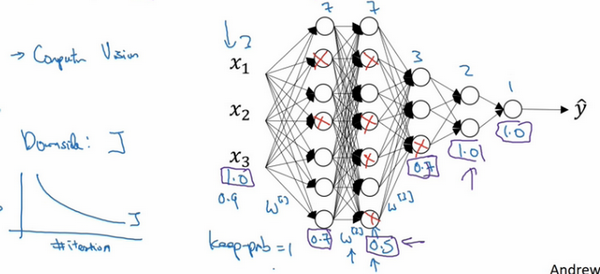
dropout一大缺点就是代价函数\(J\)不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数\(J\)每次迭代后都会下降,因为所优化的代价函数\(J\)实际上并没有明确定义,或者说在某种程度上很难计算,所以失去了调试工具来绘制这样的图片。通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。觉得也可以尝试其它方法,虽然并没有关于这些方法性能的数据统计,但可以把它们与dropout方法一起使用。
神经网络优化篇:如何理解 dropout(Understanding Dropout)的更多相关文章
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- Java提高篇之理解java的三大特性——继承
在<Think in java>中有这样一句话:复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对加以改变是不够的,它还必须能够做更多的事情.在这句 ...
- 【转】java提高篇(二)-----理解java的三大特性之继承
[转]java提高篇(二)-----理解java的三大特性之继承 原文地址:http://www.cnblogs.com/chenssy/p/3354884.html 在<Think in ja ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- 【零基础】神经网络优化之dropout和梯度校验
一.序言 dropout和L1.L2一样是一种解决过拟合的方法,梯度检验则是一种检验“反向传播”计算是否准确的方法,这里合并简单讲述,并在文末提供完整示例代码,代码中还包含了之前L2的示例,全都是在“ ...
- Task6.PyTorch理解更多神经网络优化方法
1.了解不同优化器 2.书写优化器代码3.Momentum4.二维优化,随机梯度下降法进行优化实现5.Ada自适应梯度调节法6.RMSProp7.Adam8.PyTorch种优化器选择 梯度下降法: ...
随机推荐
- 第3章 Git最最常用命令大全
相信来查命令的同学,根本不是来学具体某个命令的作用的,只是想来查看命令的语法,博主深知这一点(因为博主也是这样过来的),相信这篇文章,将会带给你在工作中最常用的命令,让你一打开就是命令大全!! 喜欢这 ...
- Solution -「HNOI 2010」城市建设
Description Link. 修改边权的动态 MST. Solution 讲清楚点. 修改边权的 MST,考虑对时间分治.设我们当前操作的操作区间是 \([l,r]\),直接暴力找 MST 是不 ...
- linux内核离线升级步骤详解【亲测可用】
由于种种原因,linux的内核版本需要升级,但由于生产原因往往不能在线升级,在此记录笔者本人昨晚的的离线升级步骤,亲测可用. 我们知道,红帽和CentOS同源同宗,内核升级步骤也是一样的. 目录 ■ ...
- 浅谈关于LCA
prologue 本身只会 tarjan 和 倍增法求LCA 的,但在发现有一种神奇的\(O(1)\) 查询 lca 的方法,时间优化很明显. main body 倍增法 先讨论倍增法,倍增法求 lc ...
- Treap树学习笔记
等我写完. 普通fhq treap: enum { Maxn = 1000005 }; struct FHQTreap { int lson[Maxn], rson[Maxn], data[Maxn] ...
- CF1878 A-G 题解
前言 赛时代码可能比较难看. 为什么 Div3 会出 4 道数据结构. A 判定 \(a\) 中是否有 \(k\) 即可. 赛时代码 B 奇怪的构造题. 令 \(a_1=1,a_2=3\),其他项由上 ...
- DRTREE - Dynamically-Rooted Tree 题解
DRTREE - Dynamically-Rooted Tree 本题建议评蓝. 思路: 题目就是要对一颗不定根树求子树权值和. 这题不带修,如果带修难度会增加一点,就跟 遥远的国度 差不多. 首先分 ...
- 2023-10-21:用go语言,一共有三个服务A、B、C,网络延时分别为a、b、c 并且一定有:1 <= a <= b <= c <= 10^9 但是具体的延时数字丢失了,只有单次调用的时间 一次调
2023-10-21:用go语言,一共有三个服务A.B.C,网络延时分别为a.b.c 并且一定有:1 <= a <= b <= c <= 10^9 但是具体的延时数字丢失了,只 ...
- 【Azure Logic App】在Azure Logic App中使用SMTP发送邮件示例
问题描述 在Azure Logic App的官网介绍中,使用SMTP组件发送邮件非常简单(https://docs.azure.cn/zh-cn/connectors/connectors-creat ...
- LCT(link cut tree) 详细图解与应用
樱雪喵用时 3days 做了 ybtoj 的 3 道例题,真是太有效率了!!1 写死自己系列. 为了避免自己没学明白就瞎写东西误人子弟,这篇 Blog 拖到了现在. 图片基本沿用 OIwiki,原文跳 ...