应用数仓ODBC前,这些问题你需要先了解一下
摘要:ODBC为解决异构数据库间的数据共享而产生的,现已成为WOSA的主要部分和一种数据库访问接口标准。
本文分享自华为云社区《GaussDB(DWS) ODBC 问题定位指南》,作者: power_gouge 。
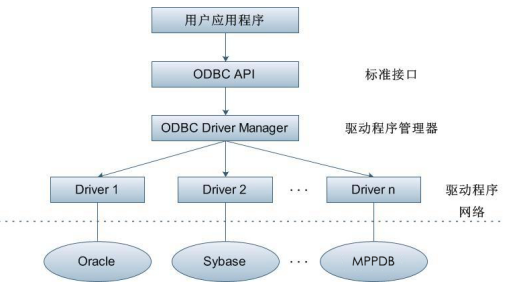
用户的应用程序,调用的ODBC的API,其实是由驱动管理器提供的,这个驱动管理器在微软上就是odbcad32(.exe/.dll),在Linux上就是UnixODBC。再由它们来调用ODBC的具体驱动(Gauss、Oracle、TD……)。
所以一般问题基本会出在以下几个方面:
- 应用加载驱动管理器
- 驱动管理器加载驱动
- 驱动连接数据库
一个典型的用户应用程序如下:
问题处理
应用程序加载驱动管理器失败
Windows
Windows由于操作系统实现机制的问题,ODBC属于操作系统组件的一部分,除非操作系统损坏,一般不会出现应用程序加载驱动管理器失败;只会出现驱动管理器加载驱动失败。所以这里不再赘述。
Linux
Linux上应用程序加载驱动管理器,是指的应用程序依赖于UnixODBC的相关动态库,启动时要将其加载到自己的进程空间中。加载出现问题多表现为在启动时找不到libodbc.so.x/libodbcinst.so.x等库。
解决此问题:
首先确认环境中是否安装了UnixODBC。如果安装了,那么至少会有isql/odbcinst等工具可用。例如可使用which isql这样的命令来确定安装路径。相关的lib库一般会在which isql指定的bin目录的同级目录下,将其添加到LD_LIBRARY_PATH中重启应用程序便可。
export LD_LIBRARY_PATH=/where/unixodbc/installed/lib:$LD_LIBRARY_PATH
特别注意,此语句只影响当前shell会话中的后续命令,其他会话不受影响,特别是后台启动的进程。如果是后台进程,请与应用程序的开发人员确认其运行环境如果修正。
如果确认LD_LIBRARY_PATH已经生效(可以打开/proc/应用程序pid/environ文件确认),依然无法加载libodbc.so.x/libodbcinst.so.x,那么可能是.1或者.2的库的问题。
历史原因,一般的开发环境中,UnixODBC提供的库既可能叫libodbc.so.1也可能叫libodbc.so.2。用户程序可能依赖了.2,但是环境中只有.1;也有可能是存在.2,但是依赖了.1。
解决此问题,只需要在UnixODBC的lib目录下,将不存在的版本建立成软链接,保证.1与.2都存在,这样出问题的机率便会小很多。特别注意,这里强烈建议是建立软链接,而不要拷贝物理文件,不然可能出现一个应用程序进程中,加载了两个导出函数完全相同的.so,这样可能会引起一些比较难定位的启动错误,后文中会讲到。
驱动管理器加载驱动失败
Windows
最常见x86与x64架构不同导致的加载失败;此问题的典型报错为:
在指定的 DSN 中,驱动程序和应用程序之间的体系结构不匹配
此问题可能的原因:在64位程序中使用了32位驱动,或者相反。
在64位系统上:
C:\Windows\SysWOW64\odbcad32.exe:这是32位ODBC驱动管理器。
C:\Windows\System32\odbcad32.exe:这是64位ODBC驱动管理器。
使用不同架构的应用程序时,请使用不同的驱动管理器;同时安装不同的驱动类型。
32位系统上只能跑32位程序,也无法安装64位驱动,所以基本不用区分。
如果是64位系统,那么它既支持32位程序,也支持64位程序;如果不能确定应用程序是32还是64,可以使用以下办法:
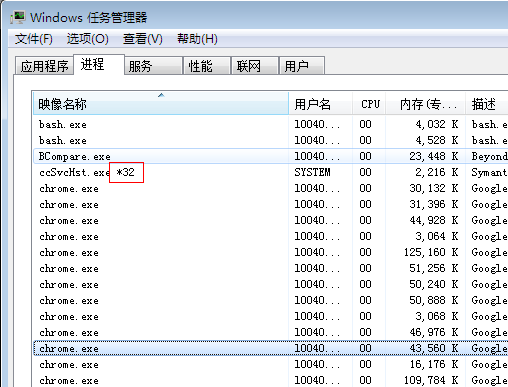
ctrl + shift + esc 打开任务管理器
查看进程列表中某进程后边有没有*32的字样(有就是32位,没有就是64位),如下图:\
Linux
环境中缺少psqlodbcw.so的库
一般这个问题的报错是
[UnixODBC][Driver Manager]Can't open lib 'xxx/xxx/psqlodbcw.so' : file not found.
可能的原因有:
odbcinst.ini中配置的路径不正确,最简单的办法是 ls -l 一下这个报错的文件,看看这个是不是真的存在,同时具有执行权限。
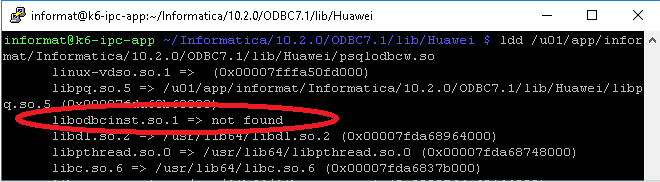
依赖的库不存在,此时最简单的办法是ldd 一下这个报错的文件,看看是不是真的缺少库,如果缺少库会出现如下问题:
要处理这个问题,需要将unixodbc的安装目录下的lib,添加到LD_LIBRARY_PATH里,例如:
export LD_LIBRARY_PATH=/where/unixodbc/installed/lib:$LD_LIBRARY_PATH
同时,在UnixODBC的安装的lib目录下,看看libodbcinst.so.x后边的后缀是.1还是.2。如果是.2,那么请建立一个软链接,链接到.1,便可以解决此问题。
如果该目录下只有.1的库,没有.2的库,也建议建立一个.2的软链接,防止应用程序依赖于.2,我们依赖于.1,引起冲突。
特别注意,当前会话的LD_LIBRARY_PATH不代表应用程序运行时也是同样的LD_LIBRARY_PATH,必要的时候,与应用程序开发人员对齐。
如果是常驻进程,可以通过如下方法获取到当前进程的环境变量:
cd /proc/应用程序PID
cat environ
打印出来的结果可能比较乱,耐心看一下;如果内容有误,与应用程序开发人员对齐修改方法。
既有.2又有.1的库,导致重复加载
这种勤快的用户比较少见,但是一旦出现,很难定位,典型的报错信息是:
Driver's SQLAllocHandle on SQL_HANDLE_DBC failed
这种情况这时应用与驱动加载的是不同的物理文件,便会导致两套完全同名的函数列表,同时出现在同一个可见域里(UnixODBC的libodbc.so.*的函数导出列表完全一致),产生冲突,无法加载数据库驱动。
解决此问题的办法也比较简单,查看LD_LIBRARY_PATH中的第一个unixodbc的lib目录。在其目录下,缺少.2或.1,建立对应的.2或.1的软链接便可。
连接问题
服务器不可达
典型报错:
connect to server failed: no such file or directory
此问题可能的原因:
配置了错误的/不可达的数据库地址,或者端口
请检查数据源配置中的Servername及Port配置项,确认网络是通达的。
服务器监听不正确
如果确认Servername及Port配置正确,请根据资料中listen_addresses参数的配置方法,确保数据库监听了合适的网卡及端口,特别是Servername中指定的网卡地址及LVS的虚拟IP地址。
修改完记得重启数据库,使监听生效。
防火墙及网闸、流控设备
请确认防火墙设置,将数据库的通信端口添加到可信端口中。
如果有网闸、流控设备,请确认一下相关的设置。
此问题一般都是第三方商业产品导致,需要咨询服务/产品提供商相关的策略。
SSL配置不正确
典型报错1:
The password-stored method is not supported.
解决办法1:
请将数据源配置中的的sslmode调整至allow及以上级别,允许使用SSL连接。
典型报错2:
Server common name "xxxx" does not match host name "xxxxx"
此问题是由于sslmode中使用了全校验(verify-full),它不仅会校验证书,还会校验证书所在的域名/机器名是否与证书符合,不符合时将报出此问题。
解决办法2:
重新让CA机构以新的域名/机器名签发证书;或者将SSLMODE调整至verify-ca选项或其以下级别(具体级别见产品资料中的说明)。
使用开源驱动连接问题
我们的数据库是支持低版本及开源驱动的(V1R7C10及以后),所以可以放心使用。
但是偶尔一些从V1R6C10升级上来的数据库,接受开源驱动连接时,会碰到用户认证算法不支持的问题,典型报错如下:
authentication method 10 not supported.
此问题机理比较复杂,下面详细展开,先说解决办法:
请使用管理新账号新建一个数据库的用户,并给予其相关的访问权限,使用新用户连接数据库。
更改当前业务用户的密码,使用新密码连接数据库。
解释一下此问题发生的机理:
我们的数据库在连接时,是会让客户端将认证信息发过来的。但是发过来的信息不会是明文密码,这是不安全的;客户端发到数据库的认证信息一般是经过加盐后的密码哈希(md5/sha256算法),迭代次数也非常多。
数据库本身也并不存储用户的明文密码,存储的是一个哈希值(所以密码要是丢了,就真的丢了,只能重置不能找回)。数据库在校验这个密码的时候,是比较哈希的,这就涉及到数据库中存储的哈希是使用的什么算法得到的哈希值,常见的是sha256(高斯自研)及MD5(开源)。
V1R7C00及以前,数据库中只存储了SHA256的哈希,升级时我们也无法推导用户原有密码,所以升级后仍然只有SHA256的哈希;但是开源客户端只识别MD5的哈希,这就导致数据库无法认证;数据库也只会让客户端以SHA256的哈希来做认证,这时开源就不识别该认证请求,导致报出如上的错误。
在创建用户和修改用户密码时,我们的新版本会同时记录两份哈希,所以后续将会同时支持开源及自研的各个版本。
因数据源配置不正确,导致的连接错误
典型报错:
Data source name not found, and no default driver specified
可能原因:
数据源名称书写错误(或含有特殊符号)
不同的操作系统用户下,数据源可见性不一样;
Linux上的数据源配置文件(odbc.ini)位置不正确
解决办法:
修正数据源名称.
Windows下,请在当前用户下打开驱动管理器,查看数据源配置是否正确。
请注意在64位系统上使用正确的数据源管理器:
C:\Windows\SysWOW64\odbcad32.exe:这是32位ODBC驱动管理器。
C:\Windows\System32\odbcad32.exe:这是64位ODBC驱动管理器。
Linux下使用odbcinst -j 命令,查看当前环境中配置文件的正确路径,输出一般如下:
unixODBC 2.3.0
DRIVERS............: /usr/local/etc/odbcinst.ini/odbcinst.ini
SYSTEM DATA SOURCES: /usr/local/etc/odbcinst.ini/odbc.ini
FILE DATA SOURCES..: /usr/local/etc/odbcinst.ini/ODBCDataSources
USER DATA SOURCES..: /usr/local/etc/odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8
其中USER DATA SOURCES就是用户数据源,优先生效;SYSTEM DATA SOURCES是系统数据源,整个系统可用。请针对这些文件路径,
注意:有时用户数据源的配置文件可能是$(HOME)/.odbc.ini
通信协议不匹配问题
典型报错:
unsupported frontend protocol 3.51: server supports 1.0 to 3.0
可能原因:
使用了新版本的数据库驱动连接老版本的数据库(V1R6C10);
或者使用了我们的驱动,连接到了开源的数据库上。
解决办法:
请使用老版本的数据库驱动连接该数据库。
我们的数据库中,默认低版本客户端可以连接高版本数据库;使用高版本驱动连接低版本客户端,不在规格约束范围内。
这个规格也比较好理解:因为用户一般是对数据库集中管理,升级也是有计划的。但是客户端驱动可能嵌入到业务中的每一个角落,有时甚至是已经发布的装备中,升级相对比较困难。
如果是开源服务器:我们的数据库驱动不支持开源数据库,无法连接;请使用开源客户端连接。
其他常见疑问
与开源的区别?
增加了安全性,使用了SHA256算法做认证加密;同时调整密钥哈希加密次数
提升了批量性能(V1R7C10 2019-4-30及以后版本)
是否可以增加新API?
不可以。
还是基础知识里那张图,用户引用的API是由驱动管理器提供的,我们提供的API只可供驱动管理器使用;新增API无法穿过中间层为用户提供服务。
是否支持COPY接口?
Copy是PG的特有语法及通信协议;而ODBC是微软提出的通用调用接口,所以无此特殊接口。
Linux上的驱动管理器有哪些?
驱动管理器在Linux上并不是操作系统的一部分,它也是由其他开源组织开发的。所以并不是只有UnixODBC一种。但是目前使用最广泛的,其实只有UnixODBC,多数据操作系统安装时基本都已经自带了UnixODBC的某个特定版本;除此之外,还有iODBC等,现在已经慢慢退出市场了。
UnixODBC的版本有限制么?
有。我们支持2.3.0及以上版本。
UnixODBC的.1与.2的库有什么区别?
没有什么区别。
这个与UnixODBC的历史有关,历史上有一段时间提供.1,后来做了一次大升级,动态库版本也跟着升级了,变成了.2。但是一大批存量业务受制无法运行,就又添加了.1的支持。
.1与.2其实只是UnixODBC的configure配置的一部分,其函数导出,功能完全一致,不必纠结于此。
可以打印日志么?
可以。
一般建议打印驱动管理器的日志,此日志比较清晰,定位问题比较快。操作办法:
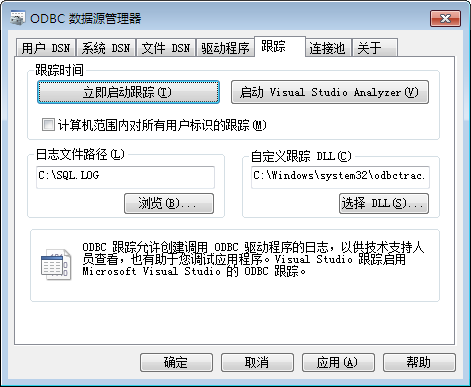
Windows上:
打开驱动管理器,调整到跟踪页面,确定日志文件路径后,点击开始跟踪便可,如图:
Linux上:
打开odbcinst.ini文件(可使用odbcinst -j 来确定文件路径),添加以下章节:
[ODBC]
Trace=Yes
TraceFIle=/tmp/odbc.log
重启业务便可。
注意:非必要时,请关闭日志,因为每个API都存在写盘,将会引起性能损失。
查询结果集过大,内存吃不消怎么办?
打开UseDclareFetch开关,它将会把查询包装成游标操作。对于不支持Cursor with hold的版本慎用。同时由于使用了服务器端的游标,游标的前后滚操作也会反馈给数据库,通信会有所增加,所以性能会有部分下降;可以通过调整Fetch参数来确定每次数据库向客户端反馈的数据量大小,来降低该性能影响。
Linux下打开UseDeclareFetch的方法:
在数据源配置项中添加:
UseDeclareFetch=1
Fetch=1000
Windows下打开UseDeclareFetch的方法:
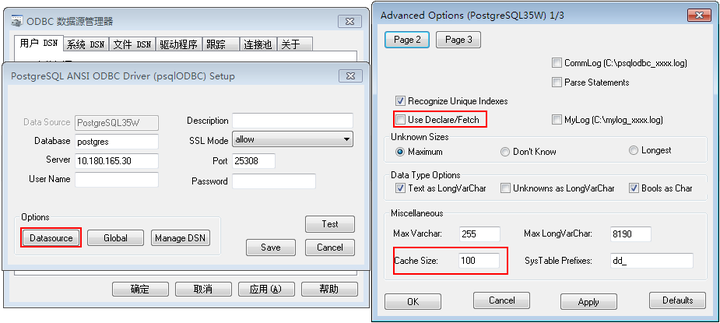
其中的Cache Size选项,就是Fetch的大小。
有性能基线数据么?
创建连接的性能大体为0.5s内都算正常(一般0.3s左右)
数据插入的话
非批量版本(R7C10以及前)大约为400tps(SSD的测试结果)
批量版本(R8C10及以后)大约为4000tps(SSD服务器),由于数据库对象差异、网络、物理硬件等,基本2000tps以上都可以认为是正常
语句出错怎么排查?
运行过程中出错,ODBC是不会打屏的。错误信息需要业务里获取错误信息(API为:SQLGetDiagField/SQLGetDiagRec)。
如果用户的业务里有打印具体的错误信息,或者业务的错误信息不足以定位,请根据3.7中的描述,将ODBC的日志打印出来,在其中找SQL_ERROR相关信息。这里最好能和业务开发人员一起定位,因为API的调用序列是乱序的,由业务决定。
如果ODBC的日志仍然不足以定位支撑,请登录到连接的目标CN所在的机器,通过以下方法进入CN日志文件目录:
source ${BIGDATA_HOME}/mppdb/.mppdbgs_profile
cd $GAUSSLOG/pg_log/cn_50xx #这里的cn_50xx表示CN编号,根据实际情况修改
找到对应时间点的日志,观察其中是否有错误信息。
我们与Oracle/MYSQL的ODBC有什么关系
ODBC是一套标准,每家数据库提供自己的驱动文件。就像大家都叫显卡,每个厂商也都提供自己的驱动,自己的驱动只能驱动自己的显卡;而显卡的接口标准是微软(ODBC也是微软)制定的,只是大家不接触,不知道有这样一套标准而已。
我们的驱动文件叫psqlodbcw.so/psqlodbcw.dll。
支持GBK么?
支持。
但是我们ODBC驱动默认使用utf-8编码。如果要调整,需要自行在会话开始时设置client_encoding。
但是请注意,请不要在宽字节模式下使用GBK,因为宽字节编码本身就是UNICODE的一部分(一般为UCS2),此时使用GBK可能导致数据无法显示,SQL查询结果不正确等问题。
如果出现此问题,请将VS中的解决方案字符集调整为“多字节”。
文章由博主@归云原创
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料哦~
应用数仓ODBC前,这些问题你需要先了解一下的更多相关文章
- Hive 数仓中常见的日期转换操作
(1)Hive 数仓中一些常用的dt与日期的转换操作 下面总结了自己工作中经常用到的一些日期转换,这类日期转换经常用于报表的时间粒度和统计周期的控制中 日期变换: (1)dt转日期 to_date(f ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- ETL数仓测试
前言 datalake架构 离线数据 ODS -> DW -> DM https://www.jianshu.com/p/72e395d8cb33 https://www.cnblogs. ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- 技术专家说 | 如何基于 Spark 和 Z-Order 实现企业级离线数仓降本提效?
[点击了解更多大数据知识] 市场的变幻,政策的完善,技术的革新--种种因素让我们面对太多的挑战,这仍需我们不断探索.克服. 今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等, ...
- 【实时数仓】Day01-数据采集层:数仓分层、实时需求、架构分析、日志数据采集(采集到指定topic和落盘)、业务数据采集(MySQL-kafka)、Nginx反向代理、Maxwell、Canel
一.数仓分层介绍 1.实时计算与实时数仓 实时计算实时性高,但无中间结果,导致复用性差 实时数仓基于数据仓库,对数据处理规划.分层,目的是提高数据的复用性 2.电商数仓的分层 ODS:原始日志数据和业 ...
- 【离线数仓】Day02-用户行为数据仓库:分层介绍、环境搭建(hive、tez)、LZO压缩、建表查询导入加索引、编写脚本
一.数仓分层概念 1.为什么要分层 ODS:原始数据层 DWD层:明细数据层 DWS:服务数据层 ADS:数据应用层 2.数仓分层 3.数据集市与数据仓库概念 4.数仓命名规范 ODS层命名为odsD ...
随机推荐
- K8s - 安装部署Kafka、Zookeeper集群教程(支持从K8s外部访问)
本文演示如何在K8s集群下部署Kafka集群,并且搭建后除了可以K8s内部访问Kafka服务,也支持从K8s集群外部访问Kafka服务.服务的集群部署通常有两种方式:一种是 StatefulSet,另 ...
- Python 批量合并图片到word文档
这段代码是一个用Python编写的功能,它将指定文件夹中的所有图片插入到Word文档中并保存.以下是代码的主要步骤和功能: 导入必要的库 Python中的docx库用于操作Word文档,glob库用于 ...
- @ApiImplicitParam dataType属性失效
最近在弄swagger,老是碰到注解属性失效问题.百度看了一大推,都是说什么版本问题.但是都不是我遇到的情况,下面直接上我遇到的问题及答案 可以看到,我直接用Integer,或者int,去到swa ...
- easyEZbaby_app
for循环,这里给它化简255-i+2-98-未知数x需要等于'0'对应的ASCII值48,那么求x的值,x=111-i,而i的值就是从0到14,这样便可以计算出15位的密码 所以写出来的脚本
- clickHouse-golang
目录 clickHouse优势与劣势 golang操作clickHouse clickHouse优势与劣势 ClickHouse和传统的MySQL在设计和使用场景上有一些显著的区别,因此它们各自具有不 ...
- 【Android】实现连接SQLite并尝试进行增删改查
- 基于uQRCode封装的Vue3二维码生成插件
标题:基于uQRCode封装的Vue3二维码生成插件 摘要:本文介绍了一种基于uQRCode封装的Vue3二维码生成插件,可以在Javascript运行环境下生成二维码并返回图片地址.该插件适用于所有 ...
- JSR223取样器详解
相比于BeanShell 取样器,JSR223取样器具有可大大提高性能的功能(编译)如果需要,一定要使用JSR223取样器编写脚本是更好的选择!!! 属性描述名称:显示的此取样器的描述性名称,可自定义 ...
- 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT points at com.qbb:qiu_code instead of org.springframework.boot:spring-boot-starter-parent
完整的错误: 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT (F:\QbbCode\qiu_code\log ...
- 在IDEA启动多个Spring Boot工程实例
在IDEA上点击Application右边的下三角 ,弹出选项后,点击Edit Configuration 选中需要多实例启动的应用,将默认的Single instance only(单实例)的钩去掉 ...