使用flume将数据sink到kafka
flume采集过程:
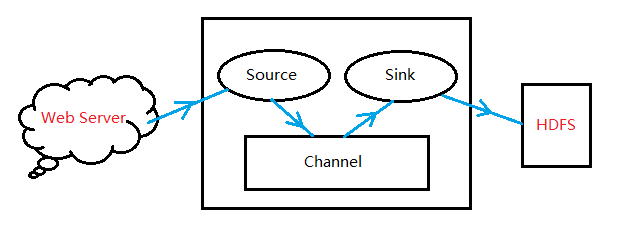
#说明:案例是flume监听目录/home/hadoop/flume_kafka采集到kafka;
启动集群
启动kafka,
启动agent,
flume-ng agent -c . -f /home/hadoop/flume-1.7.0/conf/myconf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
开启消费者
kafka-console-consumer.sh --zookeeper hdp-qm-01:2181 --from-beginning --topic mytopic
生产数据到kafka
数据目录:
vi /home/hadoop/flume_hbase/word.txt
12345623434
配置文件
vi flume-kafka.conf
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/home/hadoop/flume_kafka
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = hdp-qm-01:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
使用flume将数据sink到kafka的更多相关文章
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- flume将数据发送到kafka、hdfs、hive、http、netcat等模式的使用总结
1.source为http模式,sink为logger模式,将数据在控制台打印出来. conf配置文件如下: # Name the components on this agent a1.source ...
- flume接收http请求,并将数据写到kafka
flume接收http请求,并将数据写到kafka,spark消费kafka的数据.是数据采集的经典框架. 直接上flume的配置: source : http channel : file sink ...
- 大数据技术之Kafka
Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- flume将数据写入各个组件
一.flume集成hdfs,将数据写入到hdfs a1.sources = r1 a1.sinks = k1 a1.channels = c ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- [Spring cloud 一步步实现广告系统] 16. 增量索引实现以及投送数据到MQ(kafka)
实现增量数据索引 上一节中,我们为实现增量索引的加载做了充足的准备,使用到mysql-binlog-connector-java 开源组件来实现MySQL 的binlog监听,关于binlog的相关知 ...
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- 将CSV的数据发送到kafka(java版)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- sql计算列中并非零值的平均值
avg不考虑空值 AVG (NULLIF(Value, 0)) NULLIF(expression, expression) 如果两个 expression 相等,则返回 NULL,该 NULL 为第 ...
- Python的国内安装源(也称为镜像源)
Python的国内安装源(也称为镜像源)数量会随着时间而增加或减少,因为新的镜像源可能会建立,而一些旧的镜像源可能会停止服务或不再更新.以下是一些常用的Python国内安装源(也称为PyPI镜像源): ...
- BIN文件格式
BIN文件里面包含的只有代码生成的机器码,不像ELF文件或者obj文件一样还包含其他东西.MS-DOS.设备驱动文件以及操作系统的bootloader文件都是BIN文件. 在NASM中,BIN文件默认 ...
- postgresql 开启审计日志
1.审计清单说明 logging_collector --是否开启日志收集开关,默认off,推荐on log_destination --日志记录类型,默认是stderr,只记录错 ...
- inno Setup 打包Java exe可执行文件和MySQL数据库,无需额外配置实现一键傻瓜式安装
前言 出现有需要打包 Java 应用和 Mysql数据库成一个安装包给出去的需求,这里我把整个打包的流程整理一下. 环境 JDK17; MySQL 5.7; 流程 Jpackage打包EXE Jpac ...
- java学习之旅(day.10)
重写 前提:需要有继承关系,是子类重写父类的方法,不是属性 重写特点: 方法名必须相同, 参数列表必须相同,否则就变成重载了 修饰符:范围可以扩大,不能缩小(即父类的private的,可以扩大为pub ...
- synchronized锁升级过程
更过博文请关注:https://blog.bigcoder.cn JDK 1.6后锁的状态总共有四种,级别由低到高依次为:无锁.偏向锁.轻量级锁.重量级锁,这四种锁状态分别代表什么,为什么会有锁升级? ...
- itest(爱测试) 开源接口测试,敏捷测试管理平台10.0.1
一:itest work 简介 itest work 开源敏捷测试管理,包含极简的任务管理,测试管理,缺陷管理,测试环境管理,接口测试,接口Mock,还有压测 ,又有丰富的统计分析,8合1工作站.可按 ...
- ssh 端口转发实验
为什么会使用端口转发 端口转发的优点: 安全性:通过隐藏实际服务(在这种情况下是监听在22端口的SSH服务)的真实端口号,增加了一层安全性.攻击者可能不知道真正的服务端口号,因此更难进行有针对性的攻击 ...
- web游览器的标签页仿 ios mac 苹果的墓碑机制 (js代码)
背景: 本来项目开发系统防挂机功能,在其余游览器中均可以使用.但是呢在苹果的safair游览器中会出现几率失效,最后经过排查发现是苹果的墓碑机制导致.即:此标签页活跃,其他标签页假死.然后就导致防挂机 ...