使用flume将数据sink到kafka
flume采集过程:
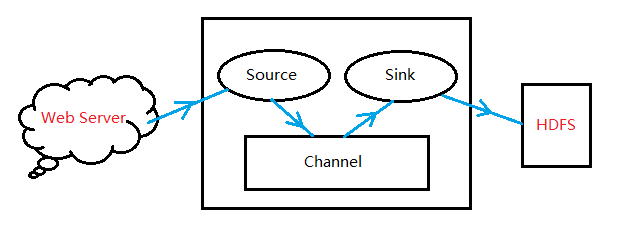
#说明:案例是flume监听目录/home/hadoop/flume_kafka采集到kafka;
启动集群
启动kafka,
启动agent,
flume-ng agent -c . -f /home/hadoop/flume-1.7.0/conf/myconf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
开启消费者
kafka-console-consumer.sh --zookeeper hdp-qm-01:2181 --from-beginning --topic mytopic
生产数据到kafka
数据目录:
vi /home/hadoop/flume_hbase/word.txt
12345623434
配置文件
vi flume-kafka.conf
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/home/hadoop/flume_kafka
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = hdp-qm-01:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
使用flume将数据sink到kafka的更多相关文章
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- flume将数据发送到kafka、hdfs、hive、http、netcat等模式的使用总结
1.source为http模式,sink为logger模式,将数据在控制台打印出来. conf配置文件如下: # Name the components on this agent a1.source ...
- flume接收http请求,并将数据写到kafka
flume接收http请求,并将数据写到kafka,spark消费kafka的数据.是数据采集的经典框架. 直接上flume的配置: source : http channel : file sink ...
- 大数据技术之Kafka
Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- flume将数据写入各个组件
一.flume集成hdfs,将数据写入到hdfs a1.sources = r1 a1.sinks = k1 a1.channels = c ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- [Spring cloud 一步步实现广告系统] 16. 增量索引实现以及投送数据到MQ(kafka)
实现增量数据索引 上一节中,我们为实现增量索引的加载做了充足的准备,使用到mysql-binlog-connector-java 开源组件来实现MySQL 的binlog监听,关于binlog的相关知 ...
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- 将CSV的数据发送到kafka(java版)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- Rails向数据库添加新字段和修改字段
目录 添加字段 控制台上执行下面的命令 会生成文件db/migrate/20210529131328_add_column_to_black_ips.rb 执行迁移 执行结果 修改字段 添加迁移文件 ...
- 使用beego/bee热启动gin框架
目录 1.需要关闭gomod 2.安装 bee 3.再开启gomod 4.启动服务 效果: 1.需要关闭gomod export GO111MODULE=off 2.安装 bee go get -u ...
- 详解GROUP BY 如何与 SELECT 语句进行交互?
SELECT 列表: 矢量聚合.如果 SELECT 列表中包含聚合函数,则 GROUP BY 将计算每组的汇总值.这些函数称为矢量聚合. Distinct 聚合.ROLLUP.CUBE 和 GROUP ...
- js中关于return和if条件处理
好玩的 // if (true) { // return // } // // 不会打印 // console.log('1') // if (false) { // return // } // / ...
- Unity Linear Gamma色彩空间矫正测试
Gamma和Linear修正的问题相信网上已经有很多文章了.简单来说显示器的颜色输出不是线性的,根据硬件参数和输出颜色 信息拟合曲线是x^2.2,因此会使用一个x^0.45曲线将其拟合回线性. 因为0 ...
- C数据结构线性表:最全链表实战剖析—单 双 循环链表&增删改查
文章目录 前言 说明1 说明2 A:关于为什么传链表要用二级指针 B:单链表 1:定义结构体 2:初始化链表 3:销毁链表内容 (释放整个链表空间,把L指针赋值为NULL ) 4:增加某一个位置上的元 ...
- docker 修改运行容器环境变量,如何修改容器中的环境变量env使长期有效
@ 目录 前言 第一步:查看Docker Root目录 第二步:查到容器的长id(container id) 第三步:停止容器 第四步:编辑修改环境变量env 第五步:重载服务的配置文件 第六步:重启 ...
- swagger文档枚举类型描述
背景: 问题:使用swagger作为api文档,但文档中的枚举类型仅显示枚举name,对于使用文档的人员来讲不容易理解 解决思路:枚举类型加上自定义的描述 解决方案 maven配置 <depen ...
- .NET8 Identity Register
分享给需要帮助的人:记一次 IdentityAPI 中注册的源码解读:设置用户账户为未验证状态,以及除此之外更安全的做法: 延迟用户创建.包含了对优缺点的说明,以及适用场景. 在ASP.NET 8 I ...
- Ciphey在windows下的安装问题('gbk' codec can't decode byte 0xbf in position 695)
---- 这玩意儿安装查了别人的博客,没搞明白他们怎么安装的- -,我太菜了,看不懂.还是去github搜了下,才解决. ---- 首先是ciphey这个包的安装(一定要的):python3 -m p ...