Tesseract-OCR-03-图片文字识别
Tesseract-OCR-03-图片文字识别
本篇介绍使用 Tesseract-OCR 做图片文字识别,识别手写文字的时候,正确率能达到 90%,当训练后正确率是极高的。这里介绍的图片文字识别,可以识别英文,数字和中文等
Tesseract-OCR 图片文字识别
- Tesseract:一款由HP实验室开发由Google维护的开源OCR,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎
- 如果还没有安装 Tesseract-OCR 请参考:
- Windows下 Tesseract-OCR 的安装与 环境变量配置
https://blog.csdn.net/qq_40147863/article/details/82285920
- Windows下 Tesseract-OCR 的安装与 环境变量配置
- 当然配置环境也都下载上面那篇文章了,一步一图很详细
正题 图片文字识别
- 我搜集了几个素材,懒得找可以直接下载:
- https://pan.baidu.com/s/10XxYJa19KIa8-ENdQkhhHg
- 这里我是将图片放在了:D:\p
- 我们需要在 cmd 进入此目录
- 使用 cd 目录名 进入目录
- 使用 cd.. 返回上一级目录
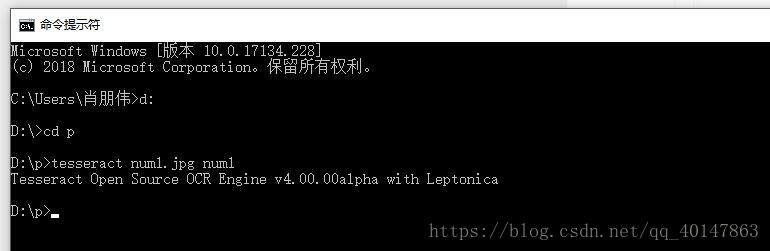
使用 Tesseract 命令:
tesseract 文件名 保存的txt文件名 -l eng 例:tesseract num1.jpg num1
- 这里 -l eng 是设置语言,不写的话,默认是 eng 也就是英语
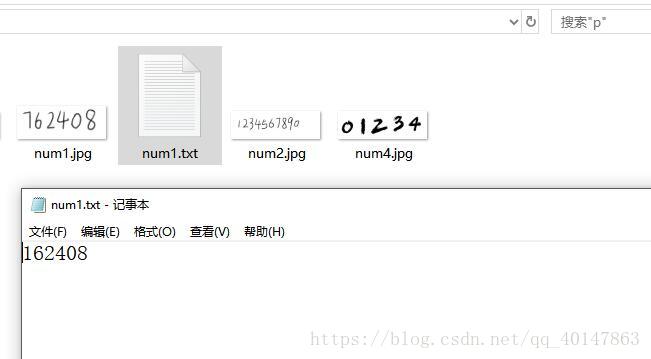
- 结果:
- 注意:
- 1.这里如果报错 Tesseract 不是内部或外部命令,就是环境变量没有配置好参照:
https://blog.csdn.net/qq_40147863/article/details/82285920 - 2.如果识别的图片文字是中文会提示,0个文字
- 1.这里如果报错 Tesseract 不是内部或外部命令,就是环境变量没有配置好参照:
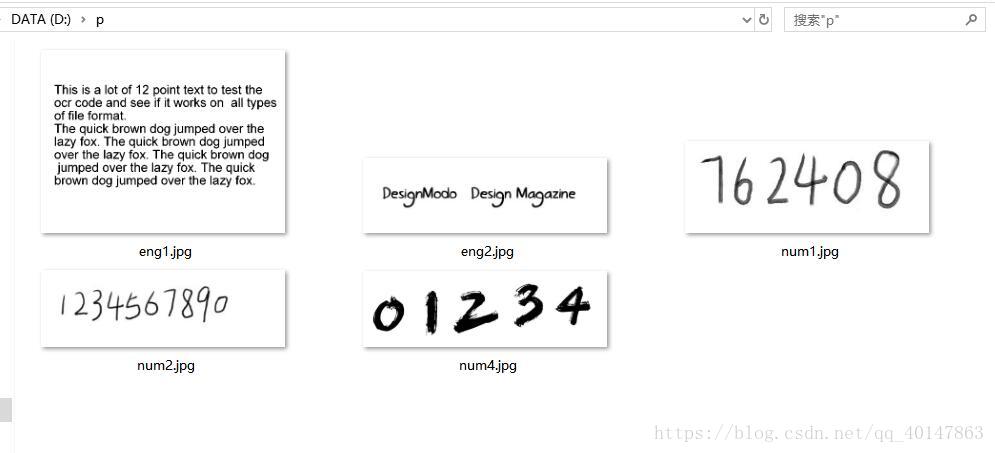
识别手写英文
- 识别图片 eng2.jpg
- 输入命令:保存为 eng2.txt
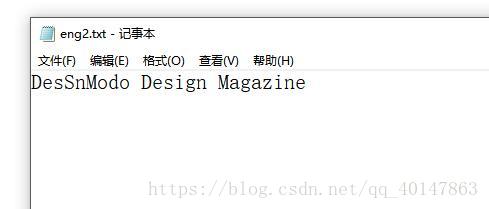
- 我们对比一下结果:
- 这里是识别错了一个字母,把 ig 错误的识别成 S,包括上面那张 数字也是错了一个
- 那也就是我们要努力的方向了


识别中文
- 这里识别中文只需要将 -l 参数改成 chi_sim 例如:
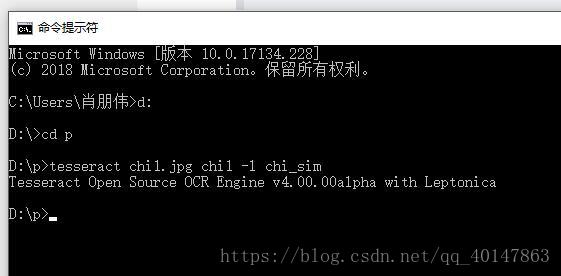
对 有中文文字的图片 chi1.jpg ,进入图片路径,使用一下命令:
tesseract chi1.jpg chi1 -l chi_sim
- 图片样式:
- 执行命令:
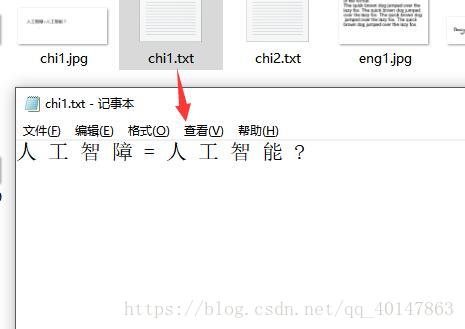
运行结果:

识别英文和数字夹杂验证码
- 例如:
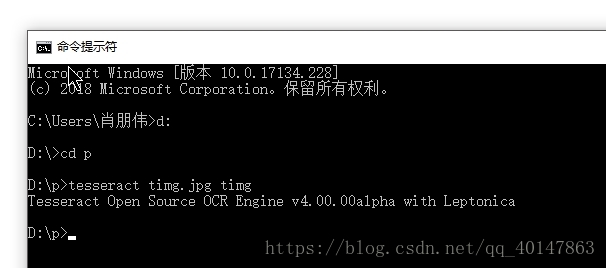
对 图片 timg.jpg ,进入图片路径,使用一下命令:
tesseract timg.jpg timg
- 图片样式:
- 执行命令:
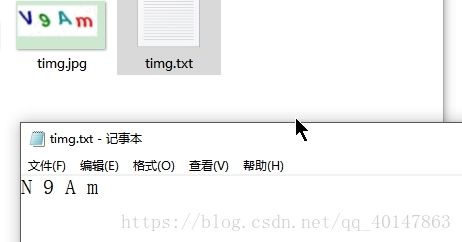
运行结果:

Tesseract 训练:
- 我们可以通过重复的训练,用更多的数据去训练,就可以达到更多高的识别正确率
- 我们使用 jTessBoxEditor 训练
- 由于 jTessBoxEditor 的安装和训练,内容比较多,我再整理一篇
更多文章链接:Tesseract 随笔
- 本笔记不允许任何个人和组织转载
Tesseract-OCR-03-图片文字识别的更多相关文章
- 基于百度OCR的图片文字识别
先上图,有图有真相 首先在百度开通ORC服务,目前是免费的,普通识别每天50000次免费,非常棒! 百度文档:http://ai.baidu.com/docs#/OCR-API/top 下载百度SDK ...
- Python图像处理之图片文字识别(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同 ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
- java 图片文字识别 ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的 ...
- 基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[l ...
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- 小试Office OneNote 2010的图片文字识别功能(OCR)
原文:小试Office OneNote 2010的图片文字识别功能(OCR) 自Office 2003以来,OneNote就成为了我电脑中必不可少的软件,它集各种创新功能于一身,可方便的记录下各种类型 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 18—Photo OCR 应用实例:图片文字识别
Lecture 18—Photo OCR 应用实例:图片文字识别 18.1 问题描述和流程图 Problem Description and Pipeline 图像文字识别需要如下步骤: 1.文字侦测 ...
- [C13] 应用实例:图片文字识别(Application Example: Photo OCR)
应用实例:图片文字识别(Application Example: Photo OCR) 问题描述和流程图(Problem Description and Pipeline) 图像文字识别应用所作的事是 ...
随机推荐
- 阿里云Centos下安装nginx之后外网无法访问
centos 7.4 nginx1-14.0编译安装 curl 127.0.0.1 可以请求到 index.html curl local 可以请求到 index.html http://ip/ 无法 ...
- redis的持久化相关操纵
一.redis数据持久化(数据保存在硬盘上) 1. 关系型数据库Mmysql持久化 任何增删改语句都是在硬盘上操作(安全) 断电,硬盘上数据还在 2.非关系型数据库 默认所有的增删改都是在内存中操作( ...
- find命令用法集锦
find命令用法: 01--过滤日志find -name "catelina.*.out"|xargs -f |grep '关键字' 02 -忽略一个目录或者多个目录find ./ ...
- .net core 的优点
[1]为什么使用.net core 首先.net core 是一个跨平台的高性能开源框架用具生成基于云连接的Internet的新的应用程序,可以建造web应用程序和服务,lot应用和移动后端,可以在W ...
- elasticsearch-7.0.0-windows 安装
一.安装 1.下载压缩包 elasticsearch-7.0.0-windows-x86_64.zip 2.解压到 E:\env\elasticsearch-7.0.0 3.启动:进入 ...
- activeMQ入门+spring boot整合activeMQ
最近想要学习MOM(消息中间件:Message Oriented Middleware),就从比较基础的activeMQ学起,rabbitMQ.zeroMQ.rocketMQ.Kafka等后续再去学习 ...
- php session的简单使用
创建session: session_start(); $_SESSION['name'] = $value; 获取session: session_start(); echo $_SESSION[' ...
- 解决C#中dynamic类型作为泛型参数的反射问题
C#中dynamic类型作为泛型参数传递过去后,反射出来的对象类型是object,我用老外的这篇博文中的代码跑起来,得出的结果是:Flying using a Object map (a map),将 ...
- 判断文本(text_to_be_present_in_element)
判断文本 在做结果判断的时候,经常想判断某个元素中是否存在指定的文本,如登录后判断页面中是账号是否是该用户的用户名.在前面的登录案例中,写了一个简单的方法,但不是公用的,在 EC 模块有个方法是可以专 ...
- DBCP连接池工具类模板
package ${enclosing_package}; import java.io.InputStream; import java.sql.Connection; import java.sq ...