Hive 体系学习
Hive简介
Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并使用HQL作为查询接口、HDFS作为存储底层、MapReduce作为执行层,将HQL语句转换成MapReduce任务进行运行,从而达到数据统计、数据分析的功能。
Hive有自身的元数据结构描述,可以使用MySQL等关系型数据库来进行存储,但请注意Hive中的所有数据都存储在HDFS中。
优点:与传统的SQL语法非常相近,学习成本低,可以通过HQL语法(类SQL语法)快速实现简单的MapReduce统计,而不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
缺点:执行速度慢,无法做到实时查询和基于行级的数据更新操作。Hive构建在基于静态批处理的Hadoop之上,Hadoop通常由较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive不适合在大规模数据集上实现低延迟快速的查询,而更适合为海量数据做数据挖掘、离线数据分析。
常见的应用场景:
- 数据分析,比如财务阶段性报表等。
- 用户标签计算:每天查询订单表,计算低频用户,然后推送营销活动。
Hive与关系型数据库的对比
| Hive | 关系型数据库 | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | 服务器本地文件系统 |
| 执行 | MapReduce | 关系型数据库自己设计的计算模型 |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 扩展性 | 扩展性强。可以方便的扩展存储能力和计算能力 | 差 |
网文关于Hive与关系型数据的深入分析
- 关系数据库里,表的加载模式是在数据加载时候强制确定的(表的加载模式是指数据库存储数据的文件格式),如果加载数据时候发现加载的数据不符合模式,关系数据库则会拒绝加载数据,这个就叫“写时模式”,写时模式会在数据加载时候对数据模式进行检查校验的操作。Hive在加载数据时候和关系数据库不同,hive在加载数据时候不会对数据进行检查,也不会更改被加载的数据文件,而检查数据格式的操作是在查询操作时候执行,这种模式叫“读时模式”。在实际应用中,写时模式在加载数据时候会对列进行索引,对数据进行压缩,因此加载数据的速度很慢,但是当数据加载好了,我们去查询数据的时候,速度很快。但是当我们的数据是非结构化,存储模式也是未知时候,关系数据操作这种场景就麻烦多了,这时候hive就会发挥它的优势。
- 关系数据库一个重要的特点是可以对某一行或某些行的数据进行更新、删除操作,hive不支持对某个具体行的操作,hive对数据的操作只支持覆盖原数据和追加数据。Hive也不支持事务和索引。更新、事务和索引都是关系数据库的特征,这些hive都不支持,也不打算支持,原因是hive的设计是海量数据进行处理,全数据的扫描时常态,针对某些具体数据进行操作的效率是很差的,对于更新操作,hive是通过查询将原表的数据进行转化最后存储在新表里,这和传统数据库的更新操作有很大不同。
- Hive也可以在hadoop做实时查询上做一份自己的贡献,那就是和hbase集成,hbase可以进行快速查询,但是hbase不支持类SQL的语句,那么此时hive可以给hbase提供sql语法解析的外壳,可以用类sql语句操作hbase数据库。
Hive架构图
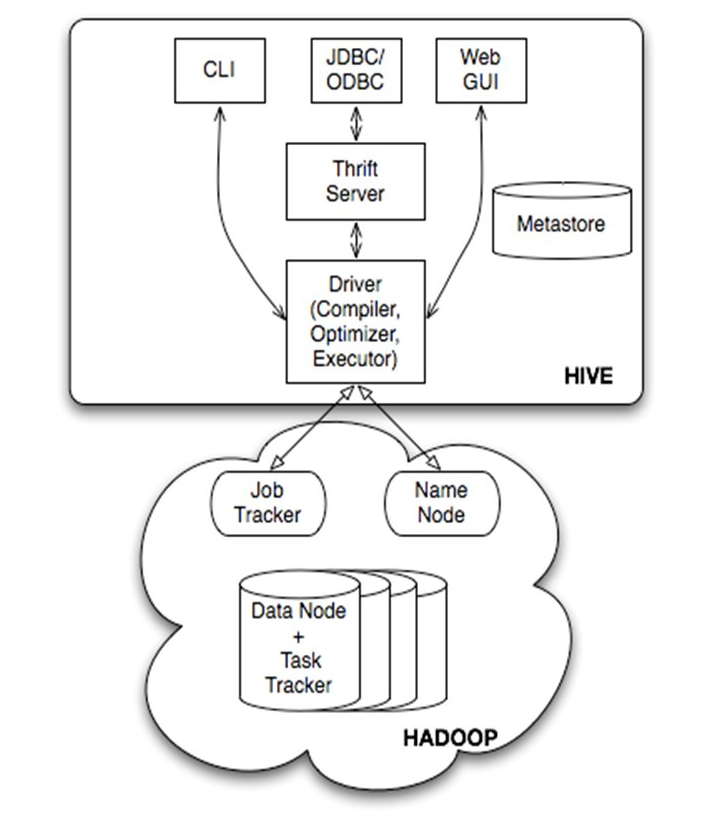
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver( Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性,这个方面的知识,我会在后面的metastore小节里做详细的讲解。
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
客户端组件:
CLI:command line interface,命令行接口。
Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
下面着重讲讲metastore组件,具体如下:
Hive的metastore组件是hive元数据集中存放地。Metastore组件包括两个部分:metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和hive服务进行交互的服务组件,默认情况下,metastore服务和hive服务是安装在一起的,运行在同一个进程当中。我也可以把metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率
Hive 脚本执行流程
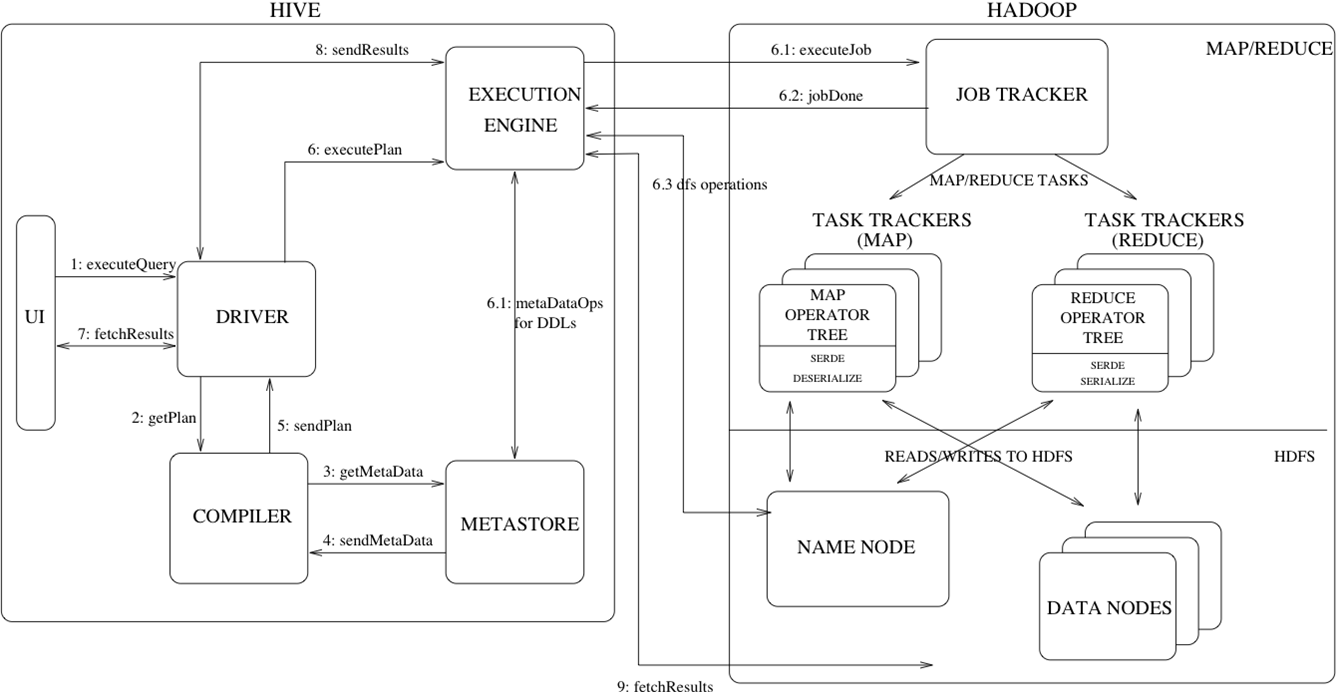
我自己画的简化版:
Hive 知识体系
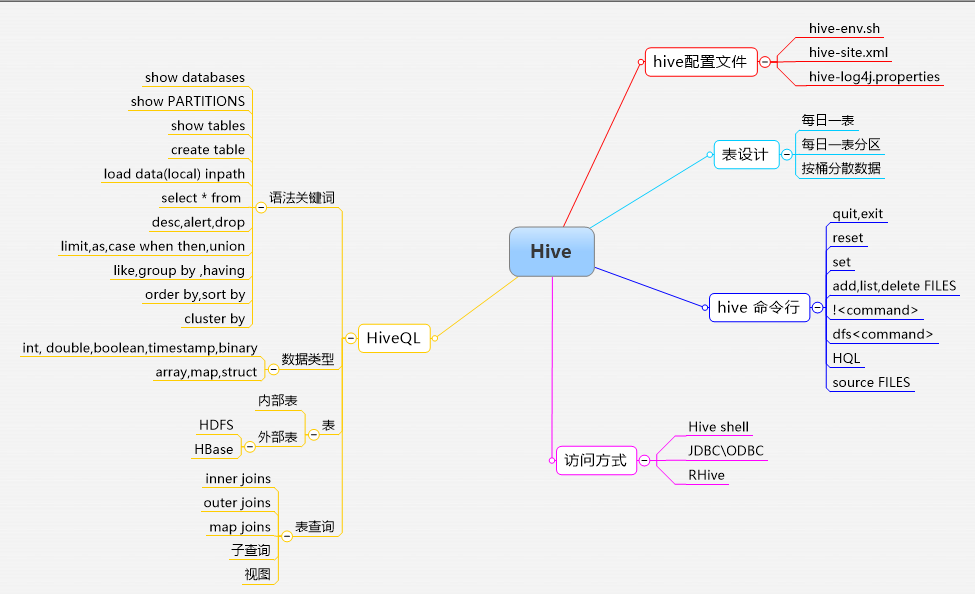
Hive 支持的数据类型
举例
1.首先,我们创建一个普通的文本文件,里面只有一行数据,该行也只存储一个字符串,命令如下:
echo 'zhangsan' > /opt/test/test.txt
2.创建一张Hive表:
hive -e 'create test(value string)'
3.加载数据
hive ;
load data local inpath '/opt/test/test.txtt' overwrite into table test ;
4.最后我们查询下表:
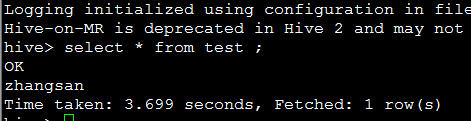
select * from test ;
原文地址
Hive 体系学习的更多相关文章
- JAVA体系学习-导向
一:当前学习内容 数值类型处理总结,字符类型处理总结,日期类型处理总结 spring 事务源码分析 spring源码系列 二:当前学习 主攻:并发编程->RPC原理->MQ原理->- ...
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- ARM架构与体系学习(二)——3级流水线
ARM架构与体系学习(二)——3级流水线 标签: 存储嵌入式汇编c 2012-04-18 00:44 5414人阅读 评论(4) 收藏 举报 分类: ARM7(16) 版权声明:本文为博主原创文章 ...
- 深入理解hive基础学习
Hive 是什么? 1.Hive 是基于 Hadoop处理结构化数据的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能. 2.Hive 利用 HDFS 存储数据 ...
- hive的学习入门(飞进数据仓库的小蜜蜂)
前言 hive是构建在Hadoop上的数据仓库平台,其设计目标是:使Hadoop上的数据操作与传统的SQL结合,让熟悉sql的开发人员能够轻松的像Hadoop平台迁移. Hive是Facebook的信 ...
- Hive基础学习
Hive 学习记录Hive介绍:Hive 是起源于Facebook,使得Hadoop进行SQL查询成为可能,进而使得非程序员也可以进进行对其使用:它是一种数据仓库工具,将结构化的数据文件 映射为一张数 ...
- Hive HQL学习
HQL学习 1.hive的数据类型 2.hive_DDL 2.1创建.删除.修改.使用数据库 Default数据库,默认的,优先级相对于其他数据库是最高的 2.2重点:创建表_内部表_ ...
- Hive入门学习--HIve简介
现在想要应聘大数据分析或者数据挖掘岗位,很多都需要会使用Hive,Mapreduce,Hadoop等这些大数据分析技术.为了充实自己就先从简单的Hive开始吧.接下来的几篇文章是记录我如何入门学习Hi ...
- Hive入门学习
Hive学习之路 (一)Hive初识 目录 Hive 简介 什么是Hive 为什么使用 Hive Hive 特点 Hive 和 RDBMS 的对比 Hive的架构 1.用户接口: shell/CLI, ...
随机推荐
- HDU4757:Tree——题解
http://acm.hdu.edu.cn/showproblem.php?pid=4757 给一棵有点值的树,每次询问u~v的最短路当中的一个点的点权异或z最大值. 前置技能:HDU4825 前置技 ...
- 洛谷 P3242 [HNOI2015]接水果 解题报告
P3242 [HNOI2015]接水果 题目描述 风见幽香非常喜欢玩一个叫做 \(osu!\) 的游戏,其中她最喜欢玩的模式就是接水果.由于她已经\(DT\) \(FC\) 了\(\tt{The\ b ...
- Qt ------- QMap和QHash的区别
基本概念: QMap提供了一个从类项为key的键到类项为T的直的映射,通常所存储的数据类型是一个键对应一个值,并且按照Key的次序存储数据.同时这个类也支持一键多值的情况,用类QMultiMap可以实 ...
- 关于深度学习(deep learning)的常见疑问 --- 谷歌大脑科学家 Caffe缔造者 贾扬清
问答环节 问:在finetuning的时候,新问题的图像大小不同于pretraining的图像大小,只能缩放到同样的大小吗?" 答:对的:) 问:目前dl在时序序列分析中的进展如何?研究思路 ...
- 使用tcpdump监控网络消息发送
tcpdump是一个用于截取网络分组,并输出分组内容的工具,简单说就是数据包抓包工具.tcpdump凭借强大的功能和灵活的截取策略,使其成为Linux系统下用于网络分析和问题排查的首选工具. tcpd ...
- npm 淘宝镜像安装以及安装报错window_nt 6.1.7601 解决
http://www.cnblogs.com/ycxhandsome/p/6562980.html npm config set proxy null npm config set https-pro ...
- 51nod 1873 高精度计算
JAVA BigDecimal import java.util.*; import java.math.*; public class Main { public static void main( ...
- LightOJ 1226 - One Unit Machine Lucas/组合数取模
题意:按要求完成n个任务,每个任务必须进行a[i]次才算完成,且按要求,第i个任务必须在大于i任务完成之前完成,问有多少种完成顺序的组合.(n<=1000 a[i] <= 1e6 mod ...
- 「模板」 线段树——区间乘 && 区间加 && 区间求和
「模板」 线段树--区间乘 && 区间加 && 区间求和 原来的代码太恶心了,重贴一遍. #include <cstdio> int n,m; long l ...
- linux 下 /bin /sbin 的区别 -- (转)
/bin,/sbin,/usr/bin,/usr/sbin区别 / : this is root directory root 用户根目录 /bin : command ...