用python抓取求职网站信息
本次抓取的是智联招聘网站搜索“数据分析师”之后的信息。
python版本: python3.5。
我用的主要package是 Beautifulsoup + Requests+csv
另外,我将招聘内容的简单描述也抓取下来了。
文件输出到csv文件后,发现用excel打开时有些乱码,但用文件软件打开(如notepad++)是没有问题的。
为了能用Excel打开时正确显示,我用pandas转换了以下,并添加上列名。转化完后,就可以正确显示了。关于用pandas转化,可以参考我的博客:
由于招聘内容的描述较多,最后将csv文件另存为excel文件,并调整下格式,以便于查看。
最后效果如下: 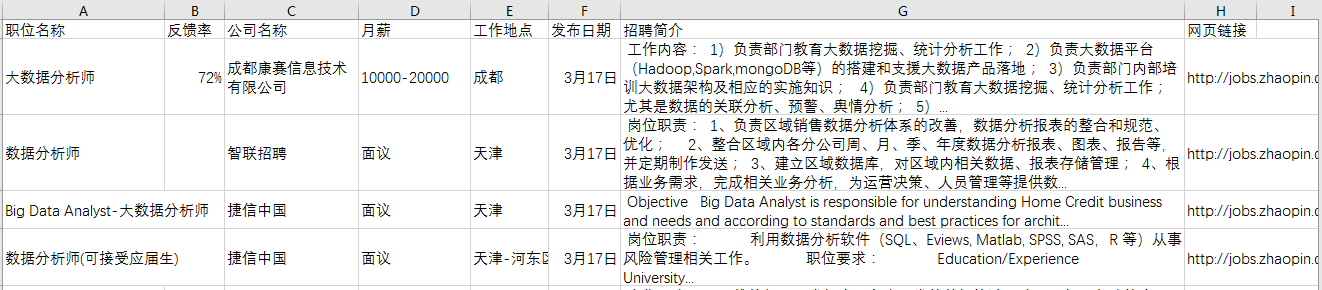
实现代码如下:信息爬取的代码如下:
# Code based on Python 3.x
# _*_ coding: utf-8 _*_
# __Author: "LEMON" from bs4 import BeautifulSoup
import requests
import csv def download(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
req = requests.get(url, headers=headers)
return req.text def get_content(html):
soup = BeautifulSoup(html, 'lxml')
body = soup.body
data_main = body.find('div', {'class': 'newlist_list_content'})
tables = data_main.find_all('table') zw_list = []
for i,table in enumerate(tables):
if i == 0:
continue
temp = []
tds = table.find('tr').find_all('td')
zwmc = tds[0].find('a').get_text()
zw_link = tds[0].find('a').get('href')
fkl = tds[1].find('span').get_text()
gsmc = tds[2].find('a').get_text()
zwyx = tds[3].get_text()
gzdd = tds[4].get_text()
gbsj = tds[5].find('span').get_text() tr_brief = table.find('tr', {'class': 'newlist_tr_detail'})
brief = tr_brief.find('li', {'class': 'newlist_deatil_last'}).get_text() temp.append(zwmc)
temp.append(fkl)
temp.append(gsmc)
temp.append(zwyx)
temp.append(gzdd)
temp.append(gbsj)
temp.append(brief)
temp.append(zw_link) zw_list.append(temp)
return zw_list def write_data(data, name):
filename = name
with open(filename, 'a', newline='', encoding='utf-8') as f:
f_csv = csv.writer(f)
f_csv.writerows(data) if __name__ == '__main__': basic_url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%85%A8%E5%9B%BD&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&sm=0&p=' number_list = list(range(90)) # total number of page is 90
for number in number_list:
num = number + 1
url = basic_url + str(num)
filename = 'zhilian_DA.csv'
html = download(url)
# print(html)
data = get_content(html)
# print(data)
print('start saving page:', num)
write_data(data, filename)
用pandas转化的代码如下:
# Code based on Python 3.x
# _*_ coding: utf-8 _*_
# __Author: "LEMON" import pandas as pd df = pd.read_csv('zhilian_DA.csv', header=None) df.columns = ['职位名称', '反馈率', '公司名称', '月薪', '工作地点',
'发布日期', '招聘简介', '网页链接'] # 将调整后的dataframe文件输出到新的csv文件
df.to_csv('zhilian_DA_update.csv', index=False)
用python抓取求职网站信息的更多相关文章
- 使用python抓取美团商家信息
抓取美团商家信息 import requests from bs4 import BeautifulSoup import json url = 'http://bj.meituan.com/' ur ...
- Python抓取成都房价信息
Python里scrapy爬虫 scrapy爬虫,正好最近成都房价涨的厉害,于是想着去网上抓抓成都最近的房价情况,顺便了解一下,毕竟咱是成都人,得看看这成都的房子我以后买的起不~ 话不多说,进入正题: ...
- 无比强大!Python抓取cssmoban网站的模版并下载
Python实现抓取http://www.cssmoban.com/cssthemes网站的模版并下载 实现代码 # -*- coding: utf-8 -*- import urlparse imp ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
- python抓取贝壳房源信息
分析了贝壳的房源信息数据,发现地址链接的参数传递是有规律的 https://tj.ke.com/chengjiao/a3l4/ a3 实际表示的 l4 表示的是 然后 将复合条件拼成一个字符串,带过去 ...
- 抓取某网站信息时遇到的问题及解决 The character set provided in ContentType is invalid. Cannot read content as string using an invalid character set
var response = httpClient.SendAsync(requestMessage).Result; content = response.Content.ReadAsStringA ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
随机推荐
- LPC4370使用学习:GPIO的引脚功能使用,和12864OLED模拟I2C驱动
一: 手中有块LPC4370的开发板,因为便宜,所以引脚引出的不多,而且只有基本的底板资源驱动代码和例程. 看着手册和例程看了老半天,写程序写了半天,结果GPIO老是驱动不起来,因为引脚配置寄存器中有 ...
- linux驱动的多种init函数及其调用顺序
在驱动设计时可以选用多种驱动初始化函数达到控制驱动初始化顺序控制,其中level(__define_initcall的第一个参数即优先级)越小优先级越高, #define pure_initcall( ...
- ASP.NET Core MVC 中设置全局异常处理方式
在asp.net core mvc中,如果有未处理的异常发生后,会返回http500错误,对于最终用户来说,显然不是特别友好.那如何对于这些未处理的异常显示统一的错误提示页面呢? 在asp.net c ...
- Top命名的一些简单用法
1. Top命令的显示 top 2. 按(Shift + O)是为了选择列进行排序.例如:按a是为了通过PID进行排序.然后按任意键返回主窗口. 3. 显示特定用户的进程. top -u hadoop ...
- HTML5发展史
2007年W3C(万维网联盟)立项HTML5,直至2014年10月底,这个长达八年的规范终于正式封稿. 在互联网的早期,对用户而言,能打开浏览器接入到互联网世界就是一个神奇的事情,但互联网发展到200 ...
- Javascript几种跨域方式总结
在客户端编程语言中如javascript,同源策略规定跨域之间的脚本是隔离的,一个域的脚本不能访问和操作另外一个域的绝大部分属性和方法.只有当两个域具有相同的协议,相同的主机,相同的端口时,我们就认定 ...
- C# 的四舍五入
c#的四舍五入有两种情况: 1.常规四舍五入 (decimal).ToString("f2") 2.四舍六入五取偶 除1里面的其他方式四舍五入都是四舍六入五取偶.
- android性能优化的一些东西
说到android性能优化,总觉得是一个很模糊的东西,因为app的性能始终适合手机本身的性能挂钩的,也许一些消耗内容的操作,在一些移动设备可以运行,但是在另外一些上面就会出现内存溢出的问题,但是不管怎 ...
- 启动genymotion后eclipse不能正常启动adb的处理办法
很多时候在使用genymotion启动后,再在eclipse调试程序会在Console中提示 The connection to adb is down,and a server error has ...
- 监听器如何获取Spring配置文件(加载生成Spring容器)
Spring容器是生成Bean的工厂,我们在做项目的时候,会用到监听器去获取spring的配置文件,然后从中拿出我们需要的bean出来,比如做网站首页,假设商品的后台业务逻辑都做好了,我们需要创建一个 ...