Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation。
1,概述
当前在闲聊机器人中的主要技术框架都是seq2seq模型。但传统的seq2seq存在很多问题。本文就提出了两个问题:
1)传统的seq2seq模型倾向于生成安全,普适的回答,例如“I don’t know what you are talking about”。为了解决这个问题,作者在更早的一篇文章中提出了用互信息作为模型的目标函数。具体见A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读。
2)传统的seq2seq模型的目标函数都是MLE函数,用MLE作为目标函数容易引起对话的死循环。具体的看下表:

面对这种挑战,我们的模型框架需要具备下面两种能力:
1)整合开发者自定义的回报函数,更好地模仿聊天机器人开发的真正目标。
2)生成一个reply之后,可以定量地描述这个reply对后续阶段的影响。
所以,本文提出用基于互信息目标函数的seq2seq + 强化学习的思路来解决这个问题。
2,强化学习在开放域对话系统中的应用
学习系统由两个agent组成,将第一个agent生成的句子定义为$p$,第二个agent生成的句子定义为$q$。两个agent互相对话来进行模型学习。在这里agent生成的句子会作为下一轮的输入,因此可以得到一个生成的对话序列:
$p_1, q_1, p_2, q_2, ......, p_n, q_n$
我们可以将生成的句子看作动作,因此这里的动作空间是连续且无限的。可以将seq2seq模型看作是策略函数。通过最大化期望奖励来优化模型的参数(注:在强化学习中的目标函数通常都是和奖励相关的,一般都是最大化长期奖励)。
我们接下来介绍强化学习中四个重要元素:动作,状态,策略和奖励。
1)动作
在这里动作是生成的句子,因此动作空间是无限的(一般对于无限的动作空间,采用策略梯度会比Q网络更合适),可以生成任意长度的序列
2)状态
在这里的状态是上一轮对话中的句子对$[p_i, q_i]$,$p_i$和$q_i$会转换成向量表示,然后拼接输入到LSTM的encoder中。
3)策略
在策略梯度算法中,通常是用一个函数表示策略的,在这里就是使用seq2seq模型(LSTM的encoder-decoder模型)来作为策略函数的,在这里采用随机性的策略(也即是给定状态的动作的概率分布,相应的确定性策略就是每个状态对应一个动作,知道状态,则动作就是确定的)。
4)奖励
在这里奖励可以说是本文的亮点,作者定义了三种奖励,并最终对这三种奖励进行加权平均。
1、Ease of Answering
这个奖励指标主要是说生成的回复一定是容易被回答的。本文用下面的公式来计算容易的程度:
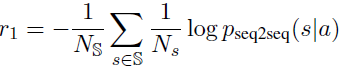
其实就是给定这个回复之后,生成的下一个回复是dull的回复的概率大小。(这里的dull的回复是指比如“I don’t know what you are talking about”这一类的回复。作者手动给出了这样的一个dull列表。)在上面式子中最左边的$N_S$是指dull列表的大小,也就是自定义的dull回复的个数,中间的$N_s$是指dull回复$s$的序列长度。
2、Information Flow
这个奖励主要是控制生成的回复尽量和之前的不要重复,增加回复的多样性。
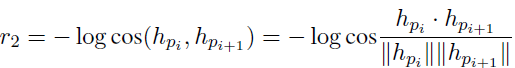
这里的$h$是bot的回复的encoder编码后的向量表示,$i$和$i+1$表示该bot的前后两轮。用cos来表示两个句子的语义相似度,两个句子越相似,则奖励越小。
3、Semantic Coherence
这个指标是用来衡量生成的回复是否grammatical和coherent。如果只有前两个指标,很有可能会得到更高的奖励,但是生成的句子并不连贯或者说不成一个自然句子。

这里采用互信息来确保生成的回复有语法连贯性。
最终的奖励是上面三个奖励的加权平均,具体的表达式如下:

在这里的加权系数是固定的,${\lambda}_1 = 0.25, {\lambda}_2 = 0.25, {\lambda}_3 = 0.5$。
3,仿真
我们的方法背后的核心思想是模拟两个虚拟的agent轮流相互交谈的过程,这样我们就可以去探索状态空间,并学习策略$p_{RL } (p_{i+1}|p_i, q_i)$以得到最大奖励。
1)监督学习
采用监督学习的方法在含8000万条数据的OpenSubtitles数据集上训练一个seq2seq + Attention的网络,将这个网络的参数作为之后的初始化参数。模型具体的输入上一轮的句子对,拼接在一起输入,输出是下一轮的回复。
2)互信息
之前的文章中提到过,直接用传统的seq2seq(即目标函数没MLE)会生成dull的回复,采用互信息可以有效的改善这种现象,在本文中作者将生成最大互信息回复的问题当作一个强化学习的问题来解决,并使用策略梯度来优化。当一条序列完全生成后就可以获得该序列的互信息。
首先使用与训练的seq2seq模型来初始化策略模型$p_{RL}$,给定一个输入$[p_i, q_i]$,我们可以得到一序列的回复$A = {a' | a' ~ p_{RL}}$,对于生成的每个$a'$,我们都可以获得其对应的互信息$m(a', [p_i, q_i])$,这个互信息值将会作为奖励,并反向传播到模型中,将互信息看作奖励,则可以得到:
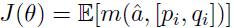
上面的函数可以看作是目标函数,则梯度可以表示为:

而实际的计算中,设定一个$L$值,小于$L$的序列中的tokens(即通过$L$值将一个生成的序列分成左右两半),其损失计算时按照MLE来计算,大于$L$的tokens按照强化学习的方法,也就是互信息来计算,$L$值会在训练的过程中衰减至0。
3)两个agent之间的对话建模
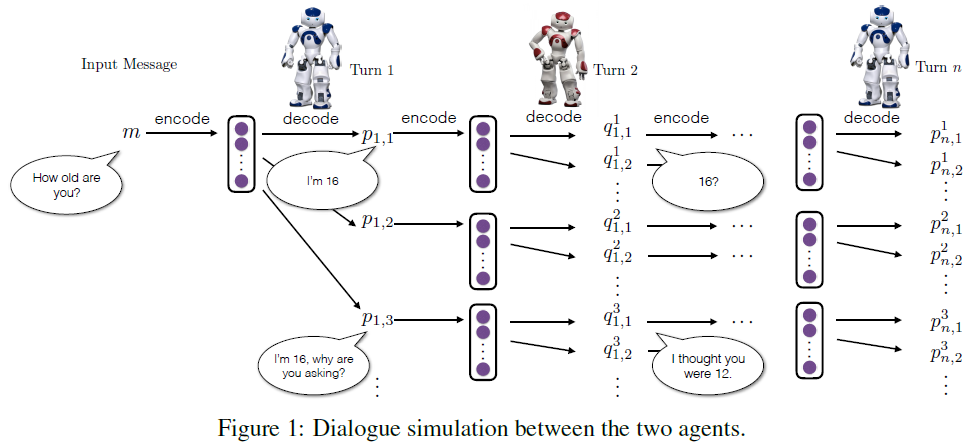
我们模拟两个虚拟的agent之间的对话,让他们互相交谈。模拟过程如下:
1,首先从训练集中选择一条句子给第一个agent,agent会对该句子编码成一个向量,并且基于该编码的向量生成一个新的句子。
2,第二个agent会将第一个agent生成的句子和从训练集中选择的句子组成一个句子对来更新当前的状态,将该状态编码成向量,然后基于该编码的向量进行解码生成一个新的句子。
3,将第二个agent生成的句子反馈给第一个agent,依次重复该过程。
具体的如下图所示:
优化过程:
首先用互信息模型来初始化$p_{RL}$,然后使用策略梯度去找到获得最大奖励期望的参数,最大话未来的奖励,其目标函数如下:
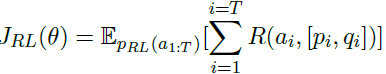
上面式子中的$R(a_i, [p_i, q_i])$表示的时动作$a_i$对应的奖励,梯度计算如下:

用上面的梯度去进行梯度上升,来更新模型的参数。
Deep Reinforcement Learning for Dialogue Generation 论文阅读的更多相关文章
- 论文阅读之: Hierarchical Object Detection with Deep Reinforcement Learning
Hierarchical Object Detection with Deep Reinforcement Learning NIPS 2016 WorkShop Paper : https://a ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
- 论文笔记之:Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning <Computer Science>, 2013 Abstract: 本文提出了一种深度学习方 ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- 论文选读一: Towards end-to-end reinforcement learning of dialogue agents for information access
Towards end-to-end reinforcement learning of dialogue agents for information access KB-InfoBot 与知识库交 ...
随机推荐
- java8 日期时间之间的关系
Class or Enum Year Month Day Hours Minutes Seconds* Zone Offset Zone ID toString Output Where Discu ...
- Spring Cloud Eureka 你还在让它裸奔吗??
前些天栈长在微信公众号Java技术栈分享了 Spring Cloud Eureka 最新版 实现注册中心的实战教程:Spring Cloud Eureka 注册中心集群搭建,Greenwich 最新版 ...
- Ubuntu 安装php+mysql+nginx
0x01 安装PHP https://blog.csdn.net/Msmile_my/article/details/73647809 1.添加php的仓库 sudo apt-get instal ...
- 使用 Moq 测试.NET Core 应用 -- Mock 方法
第一篇文章, 关于Mock的概念介绍: https://www.cnblogs.com/cgzl/p/9294431.html 本文介绍使用Moq来Mock方法. 使用的代码: https://git ...
- 网络协议 16 - DNS 协议:网络世界的地址簿
[前五篇]系列文章传送门: 网络协议 11 - Socket 编程(下):眼见为实耳听为虚 网络协议 12 - HTTP 协议:常用而不简单 网络协议 13 - HTTPS 协议:加密路上无尽头 网络 ...
- Xcode 10 iOS12 "A valid provisioning profile for this executable was not found
问题:Xcode10 build 没问题,跑虚拟机也没问题,数据线连上run到真机上出现 Xcode 10 iOS12 "A valid provisioning profile for t ...
- Linux配置成网关
之前按照诸葛建伟的metasploit魔鬼训练营搭了个简单的内网环境,其中就是一台linux作为内网网关.但是虚拟机开启的时候经常出现包不能转发的情况,也就是网关没有配置好. 在网上找了好几个才找到适 ...
- GlideNewDemo【Glide4.7.1版本的简单使用以及圆角功能】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 简单记录下Glide4.7.1版本的使用和实现圆角方案. 注意:关于详细使用请仔细阅读<官方指南>. 效果图 使用步骤 ...
- Python:strip 函数踩坑
S.strip(chars=None) strip 函数用于去除字符串首尾的空格,当 chars 不为 None 时,则删除字符串首尾的 chars 中的字符. 当 chars=None 时,去除首尾 ...
- 【网摘】EasyUI常用控件禁用启用方法
1.validatebox可以用的用法:前两种适用于单个的validatebox; 第三种应用于整个form里面的输入框; <1>.$("#id").attr(&quo ...