爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#
1.1 安装BeautifulSoup模块和解析器
1) 安装BeautifulSoup
pip install beautifulsoup4
2) 安装解析器
pip install lxml
pip install html5lib
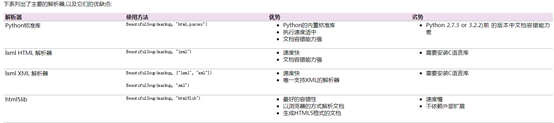
1.2 对象种类
- Tag : 标签对象,如:<p class="title"><b>yoyoketang</b></p>,这就是一个标签
- NavigableString :字符对象,如:这里是我的微信公众号:yoyoketang
- BeautifulSoup :就是整个html对象
- Comment :注释对象,如:!-- for HTML5 --,它其实就是一个特殊NavigableString
1.3 常用方法
# coding:utf-8
__author__ = 'Helen'
'''
description:爬虫模块BeautifulSoup学习
'''
import requests
from bs4 import BeautifulSoup r = requests.get("https://www.baidu.com/")
soup = BeautifulSoup(r.content,'html5lib')
print soup.a # 根据tab名输出,只输出第一个
print soup.find('a') # 同上
print soup.find_all('a') # 输出所有a元素
# 找出对应的tag,再根据元素属性找内容
print soup.find_all('a',{'href':'https://www.hao123.com','name':'tj_trhao123'})
# .contents(tag对象contents可以获取所有的子节点,返回的是list,获取该元素的直接子节点)
print soup.find('a').contents[0] # 输出第一个节点
print soup.find('div',id='u1').contents[1] # 输出第二个节点
# .children(点children这个生成的是list对象,跟上面的点contents功能一样,但是不能通过下标读,只能for循环读)
for i in soup.find('div',id='u1').children:
print i
# .descendants(获取所有的子孙节点)
for i in soup.find(class_='head_wrapper').descendants:
print i
爬虫模块BeautifulSoup的更多相关文章
- python-网络安全编程第五天(爬虫模块BeautifulSoup)
前言 昨晚学的有点晚 睡得很晚了,今天早上10点多起来吃完饭看了会电视剧就瞌睡了一直睡到12.50多起来洗漱给我弟去开家长会 开到快4点多才回家.耽搁了不少学习时间,现在就把今天所学的内容总结下吧. ...
- Python 爬虫三 beautifulsoup模块
beautifulsoup模块 BeautifulSoup模块 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查 ...
- 爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议 基础爬虫需要使用到的三个模块 requests 模块 # 模拟发请求的模块 PS:python原来有两个模块urllib和urllib的升级urlli ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用
python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用 一丶单线程+多任务的异步协程 特殊函数 # 如果一个函数的定义被async修饰后,则该函数就是一个特殊的函数 async ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- 爬虫利器BeautifulSoup模块使用
一.简介 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,同时应用场景也是非常丰富,你可以使用 ...
- 爬虫模块介绍--Beautifulsoup (解析库模块,正则)
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
随机推荐
- 小程序input输入框获取焦点时,文字会出现闪动
最近在开发小程序时,发现一个有趣的现象.input里面设置了placeholder,随后当输入框获取焦点时,文字会出现一瞬间的抖动,随后正常. 猜想可能是设置的font-family不同引起的抖动,但 ...
- SDP(12): MongoDB-Engine - Streaming
在akka-alpakka工具包里也提供了对MongoDB的stream-connector,能针对MongoDB数据库进行streaming操作.这个MongoDB-connector里包含了Mon ...
- k60模块
lptmr_time_start_ms(); //开始计时 DELAY_MS(); //延时一段时间(由于语句执行需要时间,因而实际的延时时间会更长一些) timevar = lptmr_time_g ...
- tensorflow 学习日志
Windows安装anaconda 和 TensorFlow anaconda : https://zhuanlan.zhihu.com/p/25198543 anaconda 使用与说 ...
- css样式加载顺序
css样式加载顺序: A: id选择器指定的样式 > 类选择器指定的样式 > 元素类型选择器指定的样式 B: 如果要让某个样式的优先级变高,可以使用!important来指定: .clas ...
- Online Judge(OJ)搭建——3、MVC架构
Model Model 层主要包含数据的类,这些数据一般是现实中的实体,所以,Model 层中类的定义常常和数据库 DDL 中的 create 语句类似. 通常数据库的表和类是一对一的关系,但是有的时 ...
- 关于IPFS的热门问题
最近小编在公众号收到了一些提及比较高的问题,今天总结一下统一回答 目前网络上有一些对ipfs的解读五花八门,各式各样,有看好的,也有打击的,总之一项新技术诞生之初遇到的问题IPFS都遇到了. 问题 ...
- Java中instanceof关键字的用法
Java 中的instanceof 运算符是用来在运行时指出对象是否是特定类的一个实例.instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例. instanc ...
- 学习java第一章
本人是一名5年工作的人了,出来社会也比较早,工作经验比起刚刚出社会的大学生要和很多了,知道社会的现实与无奈,我为什么选择想学java昵,肯定受到了朋友的影响的,接下来就讲讲我学习java的过程. 1. ...
- 源码实现 --> atoi函数实现
atoi函数实现 atoi()函数的功能是将一个字符串转换为一个整型数值. 例如“12345”,转换之后的数值为12345,“-0123”转换之后为-123. #include <stdio.h ...