爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#
1.1 安装BeautifulSoup模块和解析器
1) 安装BeautifulSoup
pip install beautifulsoup4
2) 安装解析器
pip install lxml
pip install html5lib
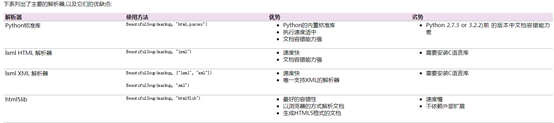
1.2 对象种类
- Tag : 标签对象,如:<p class="title"><b>yoyoketang</b></p>,这就是一个标签
- NavigableString :字符对象,如:这里是我的微信公众号:yoyoketang
- BeautifulSoup :就是整个html对象
- Comment :注释对象,如:!-- for HTML5 --,它其实就是一个特殊NavigableString
1.3 常用方法
# coding:utf-8
__author__ = 'Helen'
'''
description:爬虫模块BeautifulSoup学习
'''
import requests
from bs4 import BeautifulSoup r = requests.get("https://www.baidu.com/")
soup = BeautifulSoup(r.content,'html5lib')
print soup.a # 根据tab名输出,只输出第一个
print soup.find('a') # 同上
print soup.find_all('a') # 输出所有a元素
# 找出对应的tag,再根据元素属性找内容
print soup.find_all('a',{'href':'https://www.hao123.com','name':'tj_trhao123'})
# .contents(tag对象contents可以获取所有的子节点,返回的是list,获取该元素的直接子节点)
print soup.find('a').contents[0] # 输出第一个节点
print soup.find('div',id='u1').contents[1] # 输出第二个节点
# .children(点children这个生成的是list对象,跟上面的点contents功能一样,但是不能通过下标读,只能for循环读)
for i in soup.find('div',id='u1').children:
print i
# .descendants(获取所有的子孙节点)
for i in soup.find(class_='head_wrapper').descendants:
print i
爬虫模块BeautifulSoup的更多相关文章
- python-网络安全编程第五天(爬虫模块BeautifulSoup)
前言 昨晚学的有点晚 睡得很晚了,今天早上10点多起来吃完饭看了会电视剧就瞌睡了一直睡到12.50多起来洗漱给我弟去开家长会 开到快4点多才回家.耽搁了不少学习时间,现在就把今天所学的内容总结下吧. ...
- Python 爬虫三 beautifulsoup模块
beautifulsoup模块 BeautifulSoup模块 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查 ...
- 爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议 基础爬虫需要使用到的三个模块 requests 模块 # 模拟发请求的模块 PS:python原来有两个模块urllib和urllib的升级urlli ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用
python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用 一丶单线程+多任务的异步协程 特殊函数 # 如果一个函数的定义被async修饰后,则该函数就是一个特殊的函数 async ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python网络爬虫之BeautifulSoup模块
一.介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮 ...
- 爬虫利器BeautifulSoup模块使用
一.简介 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,同时应用场景也是非常丰富,你可以使用 ...
- 爬虫模块介绍--Beautifulsoup (解析库模块,正则)
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
随机推荐
- Dapper一个和petapoco差不多的轻量级ORM框架
我们都知道ORM全称叫做Object Relationship Mapper,也就是可以用object来map我们的db,而且市面上的orm框架有很多,其中有一个框架 叫做dapper,而且被称为th ...
- 一年iOS工作经验,如何一举拿下百度、美团、快手等Offer面经(附面试题)
前言: 先简单说说我最近的面试经历吧.面试的公司很多,大部分最后都能得到令人满意的结果,我将这些体会记录下来,面了这么多公司,如果不留下什么,那岂不是太浪费了.对于我来说,这也是一次自我检查,在这次面 ...
- redis缓存的应用详解
在现在的很多项目,基本上都需要引入缓存机制,那么缓存到底是什么呢? 缓存 也就是数据交互的缓冲区 Cache 在java-web项目中实现缓存,也就是需要首先把数据库需要用到的数据备份一份作为副本 ...
- 【Demo Project】AjaxSubmit+Servlet表单文件上传和下载
一.背景 前段时间公司要求我做一个上传和下载固件的页面,以备硬件产品在线升级,现在我把这部分功能抽取出来作为一个Demo Project给大家分享. 话不多说,先看项目演示 --> 演示 源码 ...
- VMware Workstation 学习笔记
1. 什么是虚拟机:虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的.可以运行在一个完全隔离环境中的完整计算机系统. 2. 虚拟机的用途:测试软件.搭建某种特定需求的环境 ...
- JSON基础(Java)
1.json maven 依赖(以下都以第一个包为例) <dependency> <groupId>org.json</groupId> <artifactI ...
- TCP和UDP协议的区别
TCP和UDP都是传输层的协议 UDP协议的特点: UDP协议是一种无连接的.不可靠的传输层协议(尽力而为的协议) 为什么说UDP是一种无连接.不可靠的协议呢?UDP协议在传输报文之前不需要在双方之间 ...
- 在 Rolling Update 中使用 Health Check - 每天5分钟玩转 Docker 容器技术(146)
上一节讨论了 Health Check 在 Scale Up 中的应用,Health Check 另一个重要的应用场景是 Rolling Update.试想一下下面的情况: 现有一个正常运行的多副本应 ...
- Java 后端微信支付demo
Java 后端微信支付demo 一.导入微信SDK 二.在微信商户平台下载证书放在项目的resources目录下的cert文件夹下(cert文件夹需要自己建) 三.实现微信的WXPayConfig接口 ...
- 设计模式 --> (9)代理模式
代理模式 为其他对象提供一种代理以控制对这个对象的访问. 主要解决的问题是:在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上.在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大 ...