1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高。但正则化通常有助于避免过拟合或者减少网络误差,下面介绍正则化的作用原理。
我们用逻辑回归来实现这些设想。
逻辑回归的损失函数为
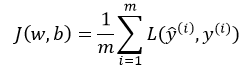
然后求损失函数J的最小值

其中, 分别表示预测值与真实值,w,b是逻辑回归的两个参数,
分别表示预测值与真实值,w,b是逻辑回归的两个参数,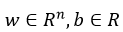 。
。
在逻辑回归中加入正则化,只需要添加参数λ,也就是正则化参数,式子如下:
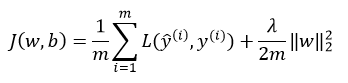
其中,向量参数w的欧几里得(L2)范数平方为:
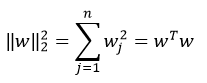
以上方法称为L2正则化。
为什么只有正则化参数w,而不加上参数b呢?其实,也可以加上,但是一般情况下可以省略不写,因为w通常是一个高维的参数矢量,已经可以表达高偏差问题,w可能含有很多参数,我们不可能拟合所以参数,而b只是单个数字,所以w几乎涵盖所有参数,而不是b。如果加了参数b,其实也没什么太大影响,因为b只是众多参数中的一个。
L2正则化是最常见的正则化类型,你们可能听说过L1正则化,L1正则项如下:

如果用的是L1正则化,w最终会是稀疏的,也就是说w向量中有很多0,有人时这样有利于压缩模型,因为集合中参数均为0,存储该模型所占的内存更少。实际上,虽然L1正则化使得模型变得稀疏,却没有降低太多存储内存,所以Angrew NG认为这并不是L1正则化的目的,至少不是为了压缩模型。人们在训练神经网络时,越来越倾向于使用L2正则化。
最后一个细节,λ是正则化参数,我们通常使用验证集或者交叉验证来配置这个参数,尝试寻找各种各样的数据,寻找最好的参数,我们要考虑训练集之间的权衡,把参数正常值设置为较小值,这样可以避免过拟合。因此λ是另外一个需要调整的超参数。顺便说一下,为了方便编写代码,在Python中,lambda是一个保留关键字。
以上就是在逻辑回归函数中实现L2正则化的过程。
-----------------------------------------------------------------
如何在神经网络中实现呢?
神经网络中损失函数如下:
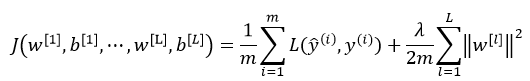
其中,L表示神经网络的层数,w是一个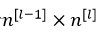 的多维矩阵,
的多维矩阵,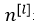 表示第l层神经元个数。
表示第l层神经元个数。
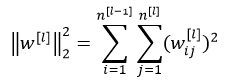
该矩阵范数被称为“弗罗贝尼乌斯范数(Frobenius norm)”,(矩阵中不称为L2范数),表示一个矩阵中所有元素的平方和。
如何使用该范数实现梯度下降呢?
用backprop计算出dw,backprop会给出j对w的偏导数,方法如下图:
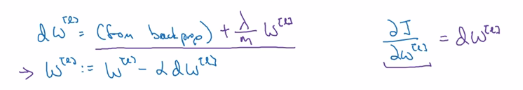
由上面可知,L2正则化有时被称为权重衰减(weight decay)
即,不加L2正则项时, 的更新方式为:
的更新方式为:
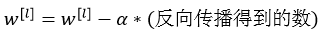
加上L2正则项之后,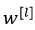 的更新方式变为:
的更新方式变为:


该正则项说明,不论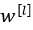 是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了
是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了 倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
以上就是神经网络中实现L2正则化的过程。
为什么正则化可以预防过拟合?请看下一节。
1.4 正则化 regularization的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- 框架开发之——AngularJS+MVC+Routing开发步骤总结——5.14
1.延续MVC的观念:包括路由映射的编写,Controller的内容,具体View页面js的分离. 2.结合AngularJS做前端,后端使用Node.Js的写法,引入MVC框架,进行快速的开发. 步 ...
- gif文件解析
详细资料:http://blog.csdn.net/wzy198852/article/details/17266507 MD5:98206F88B84CCC399C840C8EEC902CCF GI ...
- Mycat 分片规则详解--自然月分片
实现方式:按照月份列分片,每个自然月一个分片 优点:使数据按照每月来进行分时存储 缺点:由于数据是连续的,所以该方案不能有效的利用资源 配置示例: <tableRule name="s ...
- 【Android】你知道还可以通过 View.animate() 来实现动画么
这次想来讲讲 View.animate(),这是一种超好用的动画实现方式,用这种方式来实现常用的动画效果非常方便,但在某些场景下会有一个坑,所以这次就来梳理一下它的原理. 基础 首先,先来看一段代码: ...
- Spring Boot 2.0(五):Docker Compose + Spring Boot + Nginx + Mysql 实践
我知道大家这段时间看了我写关于 docker 相关的几篇文章,不疼不痒的,仍然没有感受 docker 的便利,是的,我也是这样认为的,I know your felling . 前期了解概念什么的确实 ...
- 如何在win10查看wifi密码
tep1 找到wifi图标 step 2 右键点击打开网络共享中心 没有啦!!
- machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2. 目录: 多元线性回归 Multivariates linear regression /MLR Gradient desc ...
- c语言第1次作业
一.PTA实验作业 题目1:7-3 温度转换 本题要求编写程序,计算华氏温度150°F对应的摄氏温度.计算公式:C=5×(F−32)/9,式中:C表示摄氏温度,F表示华氏温度,输出数据要求为整型. 1 ...
- 201621123060《JAVA程序设计》第八周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图或其他)归纳总结集合相关内容. 2. 书面作业 1. ArrayList代码分析 1.1 解释ArrayList的contains源代码 源代码: publ ...
- 201621123062《java程序设计》第二周学习总结
1.本周学习总结 本周学习重点: 1.java的基本数据类型(类似于C,特有boolean),java的引用类型(类似指针),其他常用类. 2.字符串类型String(比c简单),String的不变性 ...