[DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.4 正则化(regularization)
如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(regularization).另一个解决高方差的方法就是准备更多的数据,这也是非常可靠的方法.
正则化的原理
正则化公式简析
L1范数:向量各个元素绝对值之和
L2范数:向量各个元素的平方求和然后求平方根
Lp范数:向量各个元素绝对值的p次方求和然后求1/p次方
L∞范数:向量各个元素求绝对值,最大那个元素的绝对值
L2正则化:你需要做的就是在cost function 后面加上正则化参数.
\[J(W, b)=\frac{1}{m}\sum^{m}_{i=1}{L(\hat{y}^{(i)},y^{i})}+\frac{\lambda}{2m}(\parallel w\parallel _2)^{2} \]
w的欧几里得范数的平方等于\(W_{j}\) (j值从1到nx)平方的和.
\[\mit{L2} regulazation =(\parallel w \parallel_2)^{2}=\sum^{n_{x}}_{j=1}{W_j}^{2}=w^{T}w\]
这里后面也可以加上b的正则化参数,即\(\frac{\lambda}{2m}b^{2}\).但是Ng常常胜省略不写,因为W已经是一个高维参数矢量,已经可以表达高偏差问题.
L1正则化: L2正则化公式是最常见的正则化公式,你也许听说过L1正则化公式,正则化项 为\(\frac{\lambda}{2m}\sum^{n_{x}}_{j=1}|w|=\frac{\lambda}{2m}\parallel w \parallel_1\)如果你用L1正则化,最终得到的w会是稀疏的,这表明w向量中会有很多0.
现在人们越来越趋向于使用L2正则化来正则化数据.
正则化参数\(\lambda\):\(\lambda\)是另外一个需要调整的超参数.因为python中lambda是python语言的保留字段,所以我们使用lambd来命名和表示这个超参数而防止和保留字段重名.
使用L2正则化的关键原因是因为在BP算法中权值W的每次梯度下降会额外减去一个\((1-\frac{\alpha\lambda}{m})W\)的值称之为"权重衰减"即"Weight decay"
1.5 为什么正则化可以减少过拟合
L2正则化
\[J(W, b)=\frac{1}{m}\sum^{m}_{i=1}{L(\hat{y}^{(i)},y^{i})}+\frac{\lambda}{2m}(\parallel w\parallel _2)^{2} \]
- 直观上理解,当\(\lambda\)设置的很大时,足够大,权重矩阵w被设置为接近于0的值,因为正则项十分大,则前一项的影响被降低到很小.
- 直观上理解就是把多隐藏层单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响(如图中所表示的样子)
- 此时这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,但是深度却很大,它会使\(\lambda\)高方差的状态,如同最右边的图接近于左图的高偏差状态,但是\(\lambda\)会存在一个中间值,于是会有接近于"Just right"的状态.
- 我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经单元的所有隐藏单元依然存在,只是它们的影响变得更小.
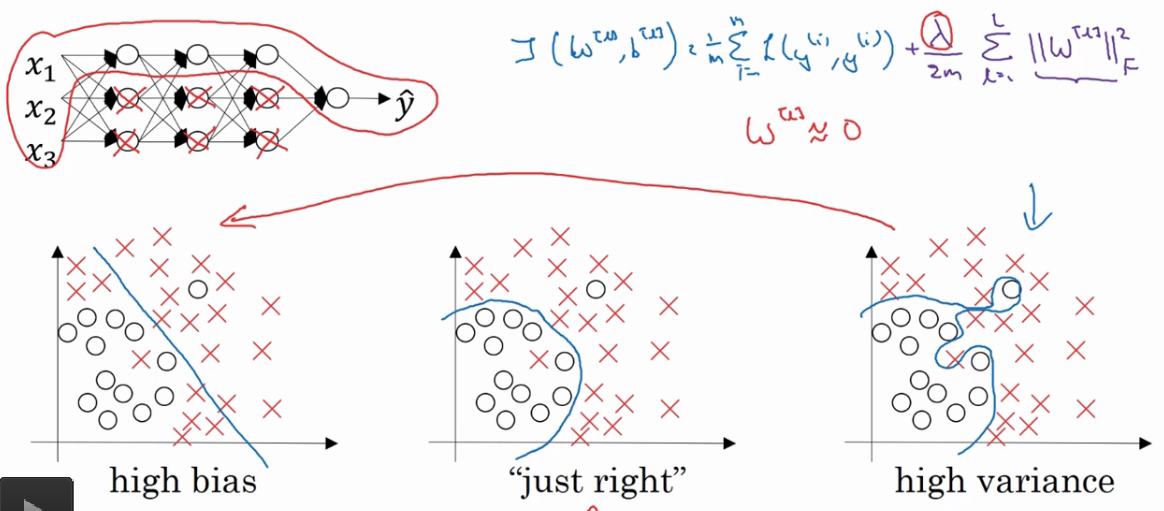
从权值改变和激活函数理解

如果正则化参数\(\lambda\)变大,激活函数的参数z会相对小,因为代价函数的参数变大了,如果w变的很小,z也会变的很小.实际上,z的取值范围很小,这个激活函数(此处为tanh)在此处相对呈线性,每层几乎都呈线性,整个网络趋向于一个线性网络,即使是一个非常深的网络,也会因具有线性激活函数的特征使得整个神经网络会计算离神经网络近的值.这个线性函数十分简单,并不是一个极复杂的高度非线性函数,所以不会发生过拟合.
1.6 Dropout正则化
假设你训练的网络如图所示
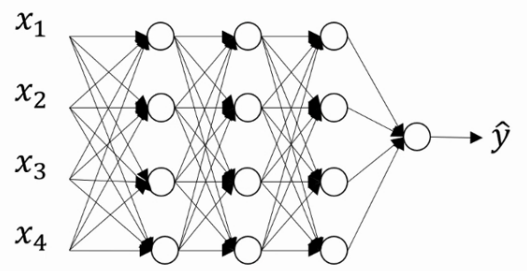
Dropout:假设你在训练如图的神经网络,如果它存在过拟合,Dropout会遍历网络的每一层,并设置消除神经网络中节点的概率.假设每一层的每个节点都以抛硬币的方式设置概率.每个节点得以保留和消除的概率都是0.5.设置完节点概率,我们会消除一些节点,然后删除从该节点进出的连线.最后得到一个节点更少,规模更小的网络.然后用backprop方法进行训练.
这是网络结构经过Dropout函数精简后的结果:
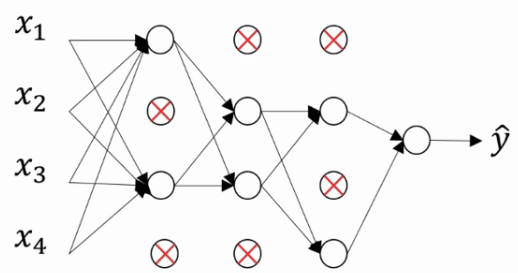
对于每个训练节点,我们都会采用一个精简后的神经网络训练它.
1.7 理解Dropout(随机失活)
- 直观理解Dropout1:
每次迭代后神经网络都会变得更小,看起来更小的神经网络和L2正则化的效果一样. - 直观理解Dropout2:

PS:每层的keep_prob值都可以设置为不同的值,对于神经元数极少的网络层我们可以将keep_prob设置为1即保存所有神经元节点不使用Dropout方法,对于神经元数较多,可能产生过拟合含有诸多参数的网络层我们可以将keep_prob设置为较小的数值表明保存较少的神经元节点.
应用
在计算机视觉中需要输入很多的图像像素数据,所以有些计算机视觉研究人员非常喜欢使用Dropout方法.几乎是一种默认的选择.但是请牢记一点Dropout是一种正则化方法,它有助于防止过拟合,因此除非算法过拟合,不然我是不会使用Dropout方法的,所以它在其他领域应用的比较少
主要存在于计算机视觉领域,因为我们通常没有足够多的数据,所以一直存在过拟合.这就是有些计算视觉研究人员如此钟情dropout函数的原因.
dropout正则化方法缺点
dropout函数一大缺点就是代价函数J不再被明确定义,每次迭代,都会移除一些节点,如果再三复查J函数,实际上我们是很难对其进行复查的.明确定义的代价函数J每次迭代后都会下降.因为使用dropout方法后我们所优化的代价函数J实际上并没有明确定义或者很难被计算,所以我们很难绘制出代价函数J的下降趋势图形.
1.8 其他正则化方法
方法1--扩增数据集
假设你正在设计一个图片分类器,产生了过拟合问题,但是如果想使用增加训练图片数量的方法来防止过拟合需要的代价太大了,我们可以使用添加水平翻转图片,放大后剪裁图片.这种方式正则化数据集,减少过拟合比较廉价.

对于光学字符识别,我们可以通多添加数字,随意旋转或扭曲数字来扩增数据.把这些数据添加到数据集他们仍然是数字.

方法2--early stopping
- 如图中所示

红色的线表示验证集上的分类误差或验证集上的代价函数/逻辑损失/对数损失等.会发现验证集还是哪国的误差会通常先呈下降趋势然后在某个节点开始上升.
early stopping作用是说"神经网络你到现在的迭代训练中表现已经非常好了,我们停止训练吧"
原理是:当你还未在神经网络中进行太多次迭代过程的时候,参数w接近0,因为随机初始化W值时,它的值可能都是较小的随机值.在迭代过程和训练过程中,w的值会越来越大,也许经过最终的迭代其值已经变得很大了.
所以early stopping 要做的就是在中间点停止迭代过程.得到一个w中等大小的弗罗贝尼乌斯范数.术语early stopping表示提前停止训练神经网络.
early stopping的缺点
- NG认为机器学习包含两个很重要的步骤
- 选择一个算法来优化代价函数J(梯度下降,Momentum,RMSprop,Adam)
优化函数后我也不想发生过拟合,也有一些工具可以解决该问题,比如正则化,扩增数据等等.
NG认为在训练时简化这两方面权衡的方法是首先只关注优化代价函数J,只需留意w和b,使得J代价函数更小即可,然后才是关注预防过拟合的问题.
然而early stopping这个方法没有独立的解决这两个问题,为了避免过拟合而提前结束了梯度下降的过程,这样就没有能使J代价函数降低到最低值,J的值可能不够小.这样做的结果是可能我考虑的东西比较复杂.
early stopping和L2正则化的权衡
对于L2正则化而言,我增加了一个超参数\(\lambda\),这样我要不停地寻找\(\lambda\)的值使能达到效果,训练神经网络的计算代价会变得更高.
early stopping 的优点是,只运行一次梯度下降,那你就可以找到w的较小值,中间值和较大值,而无需尝试L2正则化超级参数\(\lambda\)的很多值.
[DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 训练/开发/测试集 对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验 ...
- 改善深层神经网络(三)超参数调试、Batch正则化和程序框架
1.超参数调试: (1)超参数寻找策略: 对于所有超参数遍历求最优参数不可取,因为超参数的个数可能很多,可选的数据过于庞大. 由于最优参数周围的参数也可能比较好,所以可取的方法是:在一定的尺度范围内随 ...
- DLNg改善深层NN:第一周DL的实用层面
1.为什么正则化可以减少过拟合? //答:可以让模型参数变小,减小模型的方差. 在损失函数中加入正则项,在正则化时,如果参数lamda设置得足够大,那么就相当于权重系数W接近于0 ,就会减少很多隐藏单 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch正则化和程序框架 听课笔记
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
随机推荐
- RHM-M60型挖掘机力矩限制器/载荷指示器
RHM-M60挖掘机力矩限制器RHM-M60 excavator crane moment limiter RHM-M60型挖掘机力矩限制器是臂架型起重机机械的安全保护装置,本产品采用32位高 ...
- 关于python使用threadpool中的函数单个参数和多个参数用法举例
1.对单个元素的函数使用线程池: # encoding:utf-8 __author__='xijun.gong' import threadpool def func(name): print 'h ...
- 为什么会有OPTIONS请求
在做项目时,很多时候发送一个post请求,是先发送一个option请求,然后再发送post请求,一直这么用之前也没有仔细思考,今天有时间,好好了解一下为什么会多一次请求. 疑问1:什么是options ...
- JavaScript练习2
今天做了一些JS数组的练习题 一.往数组中插入一个数字 var attr = [1,2,3,4,5,6]; var c = 7; for(var i=0;i<attr.length;i++) { ...
- Javascrip随笔1
isNaN:指示某个值不是数字 文本字符串中使用反斜杠对代码行进行换行; 在计算机程序中,经常会声明无值的变量.未使用值来声明的变量,其值实际上是 undefined.在执行过以下语句后,变量 car ...
- HDU 2296:Ring
Problem Description For the hope of a forever love, Steven is planning to send a ring to Jane with a ...
- BZOJ 2463: [中山市选2009]谁能赢呢?(新生必做的水题)
2463: [中山市选2009]谁能赢呢? Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 2372 Solved: 1750[Submit][Sta ...
- [bzoj3955] [WF2013]Surely You Congest
首先最短路长度不同的人肯定不会冲突. 对于最短路长度相同的人,跑个最大流就行了..当然只有一个人就不用跑了 看起来会T得很惨..但dinic在单位网络里是O(m*n^0.5)的... #include ...
- cookie 和 session的区别
一.总结: 1.cookie数据存放在客户的浏览器上,session数据放在服务器上. 2.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗 考虑到安全应当使用ses ...
- TCP层的分段和IP层的分片之间的关系 & MTU和MSS之间的关系 (转载)
首先说明:数据报的分段和分片确实发生,分段发生在传输层,分片发生在网络层.但是对于分段来说,这是经常发生在UDP传输层协议上的情况,对于传输层使用TCP协议的通道来说,这种事情很少发生. 1,MTU( ...