1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高。但正则化通常有助于避免过拟合或者减少网络误差,下面介绍正则化的作用原理。
我们用逻辑回归来实现这些设想。
逻辑回归的损失函数为
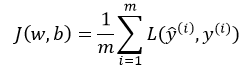
然后求损失函数J的最小值

其中, 分别表示预测值与真实值,w,b是逻辑回归的两个参数,
分别表示预测值与真实值,w,b是逻辑回归的两个参数,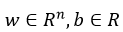 。
。
在逻辑回归中加入正则化,只需要添加参数λ,也就是正则化参数,式子如下:
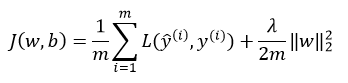
其中,向量参数w的欧几里得(L2)范数平方为:
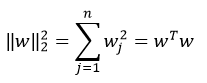
以上方法称为L2正则化。
为什么只有正则化参数w,而不加上参数b呢?其实,也可以加上,但是一般情况下可以省略不写,因为w通常是一个高维的参数矢量,已经可以表达高偏差问题,w可能含有很多参数,我们不可能拟合所以参数,而b只是单个数字,所以w几乎涵盖所有参数,而不是b。如果加了参数b,其实也没什么太大影响,因为b只是众多参数中的一个。
L2正则化是最常见的正则化类型,你们可能听说过L1正则化,L1正则项如下:

如果用的是L1正则化,w最终会是稀疏的,也就是说w向量中有很多0,有人时这样有利于压缩模型,因为集合中参数均为0,存储该模型所占的内存更少。实际上,虽然L1正则化使得模型变得稀疏,却没有降低太多存储内存,所以Angrew NG认为这并不是L1正则化的目的,至少不是为了压缩模型。人们在训练神经网络时,越来越倾向于使用L2正则化。
最后一个细节,λ是正则化参数,我们通常使用验证集或者交叉验证来配置这个参数,尝试寻找各种各样的数据,寻找最好的参数,我们要考虑训练集之间的权衡,把参数正常值设置为较小值,这样可以避免过拟合。因此λ是另外一个需要调整的超参数。顺便说一下,为了方便编写代码,在Python中,lambda是一个保留关键字。
以上就是在逻辑回归函数中实现L2正则化的过程。
-----------------------------------------------------------------
如何在神经网络中实现呢?
神经网络中损失函数如下:
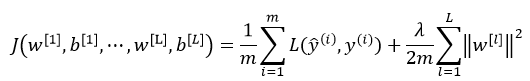
其中,L表示神经网络的层数,w是一个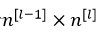 的多维矩阵,
的多维矩阵,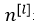 表示第l层神经元个数。
表示第l层神经元个数。
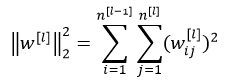
该矩阵范数被称为“弗罗贝尼乌斯范数(Frobenius norm)”,(矩阵中不称为L2范数),表示一个矩阵中所有元素的平方和。
如何使用该范数实现梯度下降呢?
用backprop计算出dw,backprop会给出j对w的偏导数,方法如下图:
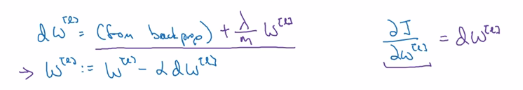
由上面可知,L2正则化有时被称为权重衰减(weight decay)
即,不加L2正则项时, 的更新方式为:
的更新方式为:
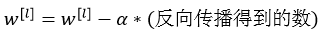
加上L2正则项之后,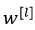 的更新方式变为:
的更新方式变为:


该正则项说明,不论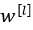 是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了
是什么,我们都试图让它变得更小,实际上,相当于我们给矩阵W乘以了 倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
倍的权重,该倍数小于1,因此L2正则化也被称为权重衰减(weight decay)。
以上就是神经网络中实现L2正则化的过程。
为什么正则化可以预防过拟合?请看下一节。
1.4 正则化 regularization的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- Find The Multiply
Find The Multiply poj-1426 题目大意:给你一个正整数n,求任意一个正整数m,使得n|m且m在十进制下的每一位都是0或1. 注释:n<=200. 想法:看网上的题解全是b ...
- sql的优化30条
1. 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2. 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使 ...
- IO流回顾与总结第一篇之字节流与字符流的操作。。。。。
一.引言 趁着年后的这点时间,抓紧点时间回顾下javase中的IO流,以往都是用到那些常用的IO类,这次来个全点的,有不对的地方还请大神指正一下,做到坚持写博的习惯来...... 回归正题,IO流顾名 ...
- 启动django应用报错 “Error: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。”
启动django应用时报如下错误 "Error: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试." 网上查了一下,是8000端口被其他程序占 ...
- Java作业-集合
1. 本周学习总结 2. 书面作业 1. ArrayList代码分析 1.1 解释ArrayList的contains源代码 public boolean contains(Object o) { r ...
- Beta版本敏捷冲刺每日报告——Day2
1.情况简述 Beta阶段第二次Scrum Meeting 敏捷开发起止时间 2017.11.3 08:00 -- 2017.11.3 22:00 讨论时间地点 2017.11.3晚9:00,软工所实 ...
- HASH方法课下补分博客
课堂要求:利用除留余数法为下列关键字集合的存储设计hash函数,并画出分别用开放寻址法和拉链法解决冲突得到的空间存储状态(散列因子取0.75)关键字集合:85,75,57,60,65,(你的8位学号相 ...
- Tornado websocket应用
应用场景 WebSocket 的特点如下 适合服务器主动推送的场景(好友上线,即时聊天信息,火灾警告,股票涨停等) 相对于Ajax和Long poll等轮询技术,它更高效,不耗费网络带宽和计算资源 它 ...
- appcompat v21: 让 Android 5.0 前的设备支持 Material Design
1. 十大Material Design开源项目 2. appcompat v21: 让 Android 5.0 前的设备支持 Material Design 主题 AppCompat已经支持最新的调 ...
- JFinal项目发送邮件——jfinal-mail-plugin
JFianl框架: JFinal 是基于 Java 语言的极速 WEB + ORM 框架,其核心设计目标是开发迅速.代码量少.学习简单.功能强大.轻量级.易扩展.Restful.在拥有Java语言所有 ...