web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章。
web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据。例如知乎回答列表、微博热门、微博评论、淘宝、天猫、亚马逊等电商网站商品信息、博客文章列表等等。
如果你已经用过这个工具,想必已经用它抓取过一些数据了,是不是很好用呢。也有一些同学在看完文章后,发现有一些需求是文章中没有说到的,比如分页抓取、二级页面的抓取、以及有些页面元素选择总是不能按照预期的进行等等问题。
本篇就对前一篇文章做一个补充,解决上面所提到的问题。
分页抓取
上一篇文章提到了像知乎这种下拉加载更多的网站,只要使用 Element scroll down 类型就可以了,但是没有提到那些传统分页式的网站。
其实分页式的网站更加简单,不用什么过多的设置,只需要在 Start URL 上做设置就可以了,拿这个豆瓣小组举例,链接地址为 https://www.douban.com/group/135641/discussion。我们进去后点一点页面下方的页码,就可以看到地址栏上的变化,点击第 2 页的时候,在后面的地址栏多了参数 start=25 ,再点击第 1 页的时候,参数变为了 start=0 ,这是比较特殊的一种情况,它的分页是按照 25 递增的,向后递增依次为 [0,25,50,75...]。大多数的网站的递增还是1,即[0,1,2,3...]。
而 web scraper 中提供了一种写法,可以设置页码范围及递增步长。写法是这样的: [开始值-结束值:步长],举几个例子来说明一下:
1、获取前10页,步长为1的页面 :[1-10] 或者 [1-10:1]
2、获取前10页,步长为10的页面:[1-100:10]
3、获取前10页,步长为25的页面:[1-250:25]
现在我们要抓取的豆瓣小组的规则就是第三中情况,所以设置 sitemap 的 Start URL 为:https://www.douban.com/group/135641/discussion?start=[0-100:25] 。
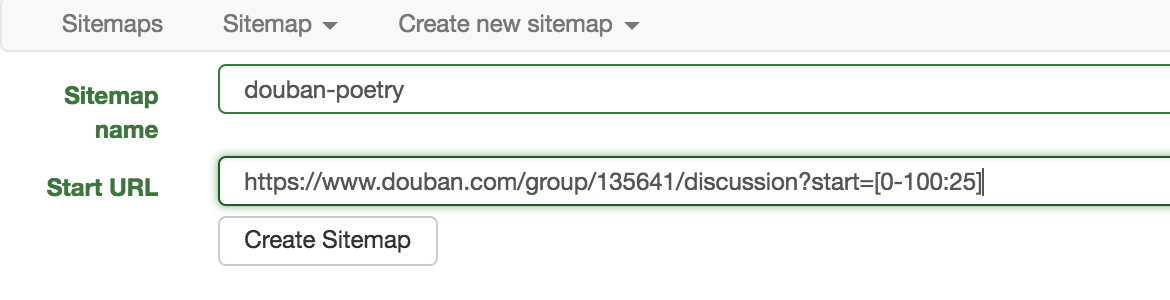
还有一些网站的页面,比如淘宝店铺的商品列表页,它的 url 里有好多参数,有点参数会随机变化,有些同学这时候就蒙了,这怎么设置啊。其实有些参数并不会影响显示内容,任意设置甚至去掉都没有关系,只要找对了表示页码的参数并按照上面的做法设置就可以了。
二级页面抓取
这种情况也是比较多的,好多网站的一级页面都是列表页,只会显示一些比较常用和必要的字段,但是我们做数据抓取的时候,这些字段往往不够用,还想获取二级详情页的一些内容。下面我用虎嗅网来演示一下这种情况下的抓取方式。
目标页面:https://www.huxiu.com/channel/104.html
只做简单演示,这个页面本身是下拉下载更多的页面,这里只获取默认加载的内容以及二级页面的一些属性。下面的两张图中标红的部分分别为列表页的标题、作者以及详情页的发布时间,点击列表页的标题链接会跳转到详情页面。
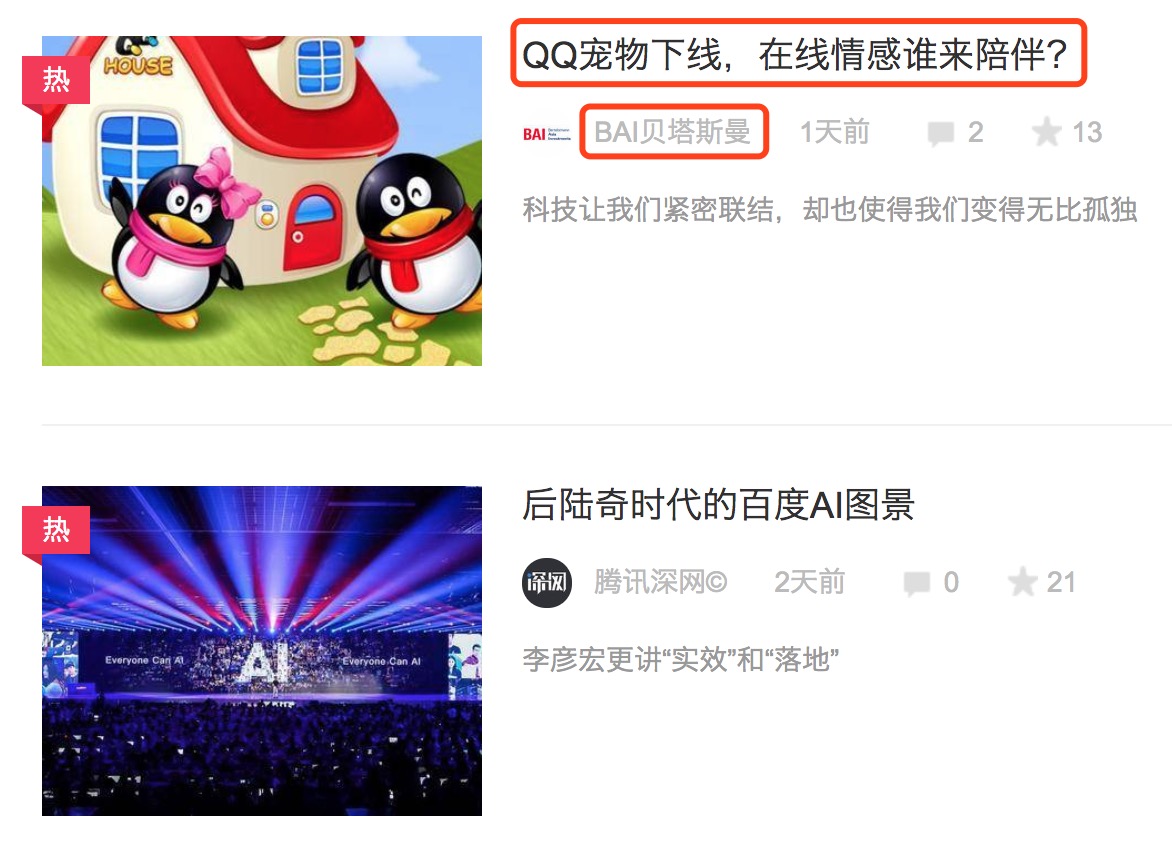

现在开始从头到尾介绍一下整个步骤,其实很简单:
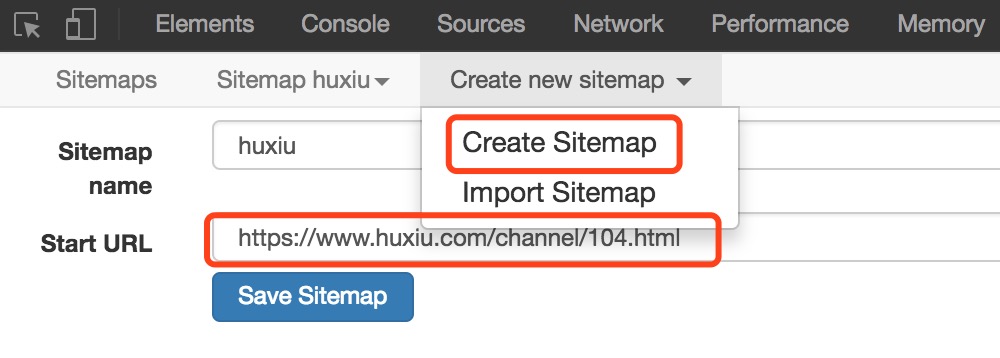
1、在浏览器访问上面说的这个地址,然后调出 Web Scraper ,Create Sitemap ,输入一个名称和 Start URL,然后保存。
2、之后打开这个 sitemap ,点击 Add new selector。
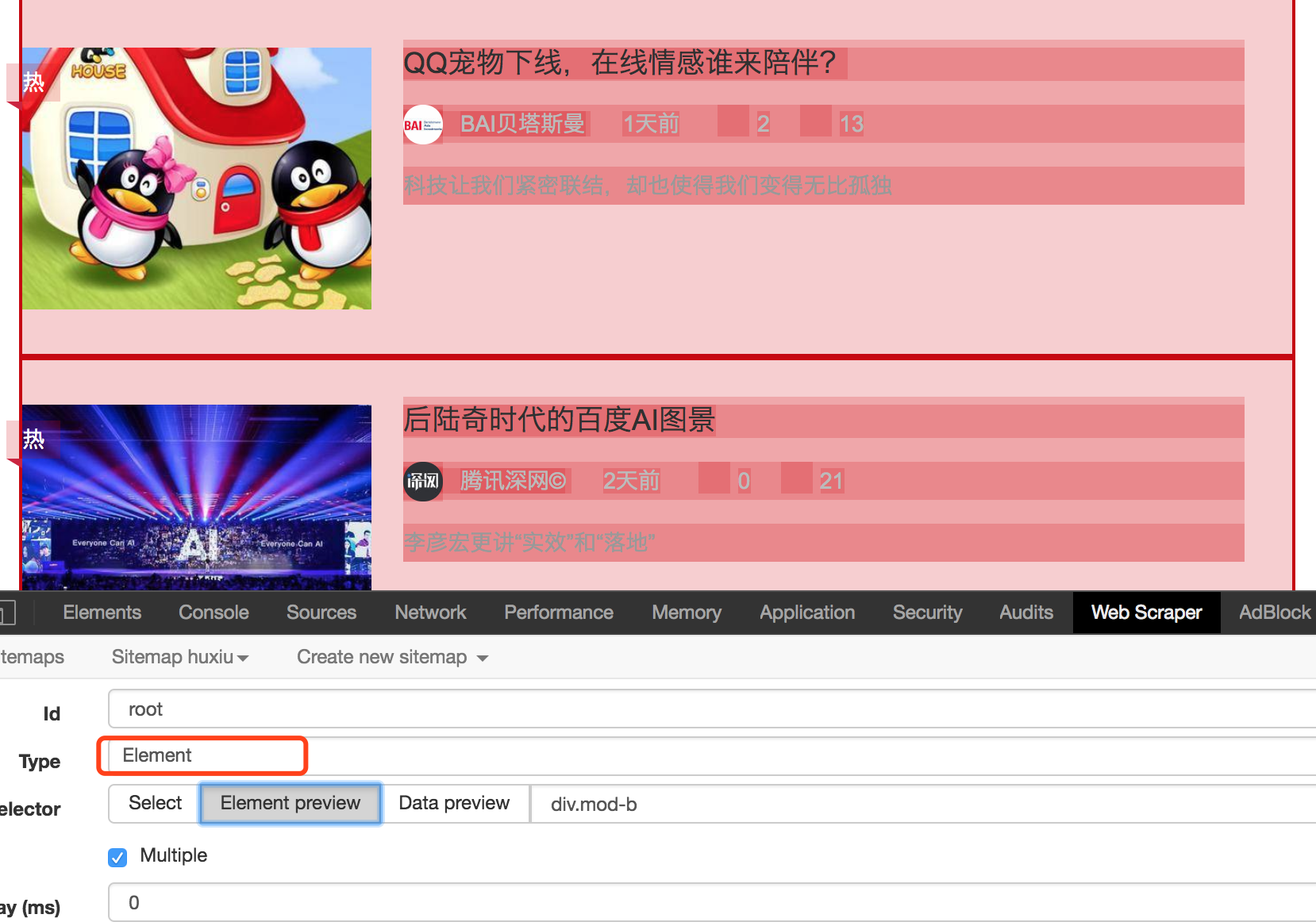
3、输入 Id,Type 选择为 Element,点击 Select 在页面中选择列表区域,并勾选 Multiple ,保存。最后预览效果如下:
4、回到刚刚创建的 root selector,点击进入子 selector 页面,添加子 selector。
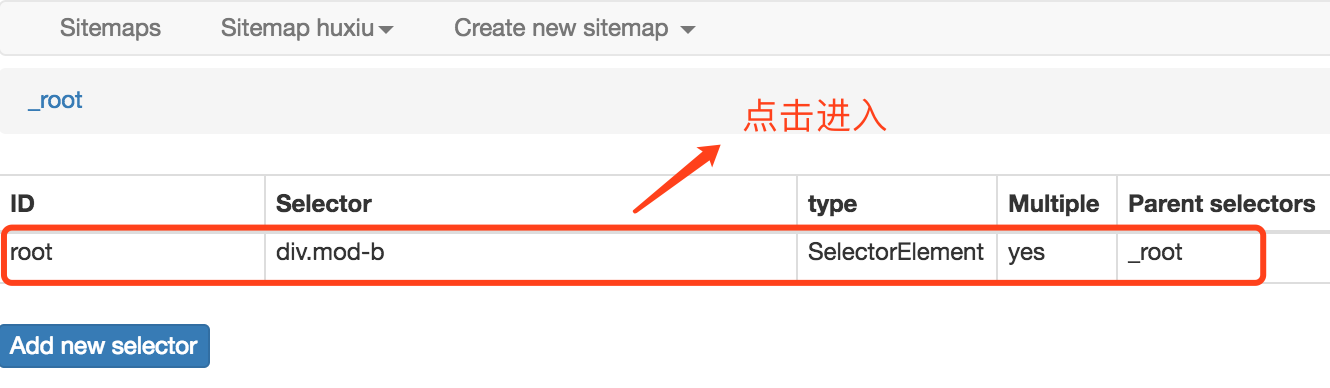
5、进入子 selector 页面后,点击 Add new selector,这一步是为了加一个跳转 selector ,为之后到详情页面搭个桥。依然是填写 Id,Type 选择为 Link 类型,点击 selector ,选择点击跳转的链接,这里就是标题,之后预览效果如下:
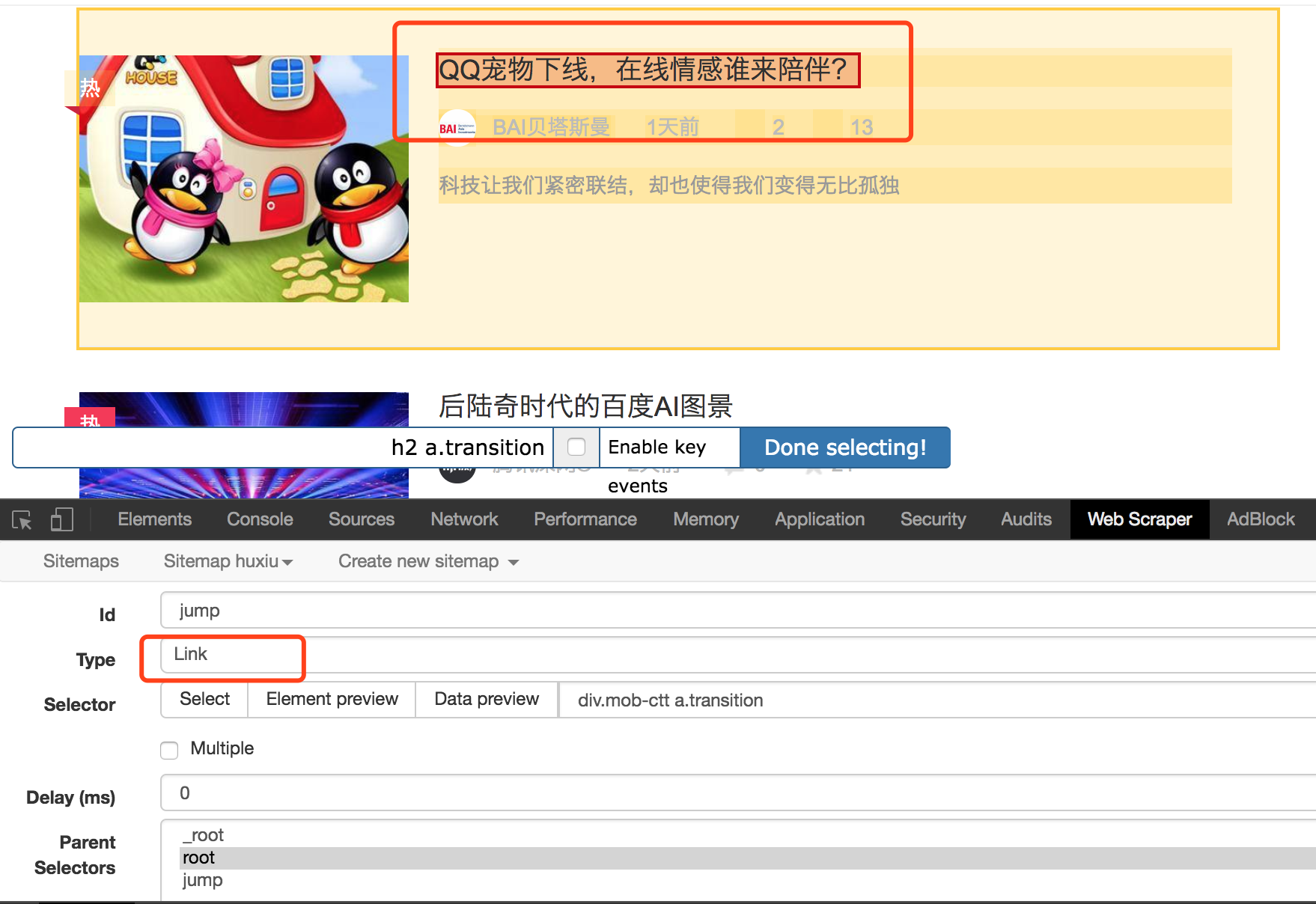
6、这一步完成后,下面就要到详情页选择我们需要的内容了。点击刚刚创建的 jump 跳转 selector,点击进入它的下一级 selector 界面。这一步好多同学不知道怎么操作了,好多同学也就卡在了这一步,其实很简单。就在当前页面,把地址栏的地址变为任意一个详情页的地址。
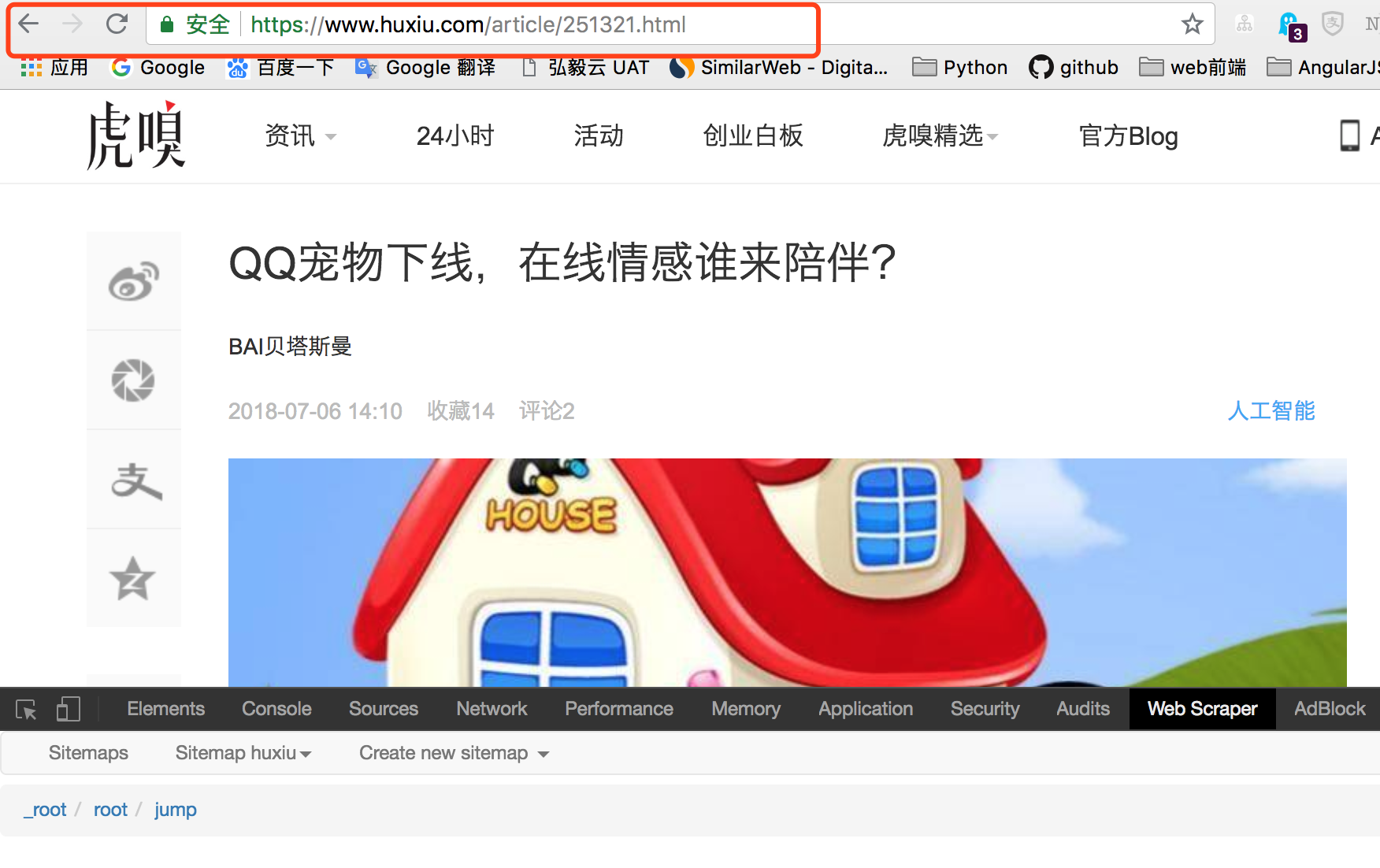
7、继续 Add new selector ,输入Id,类型选择 text 即可,点击 select ,选择日期部分,最后保存。如果需要其他信息,依次添加 selector 即可。
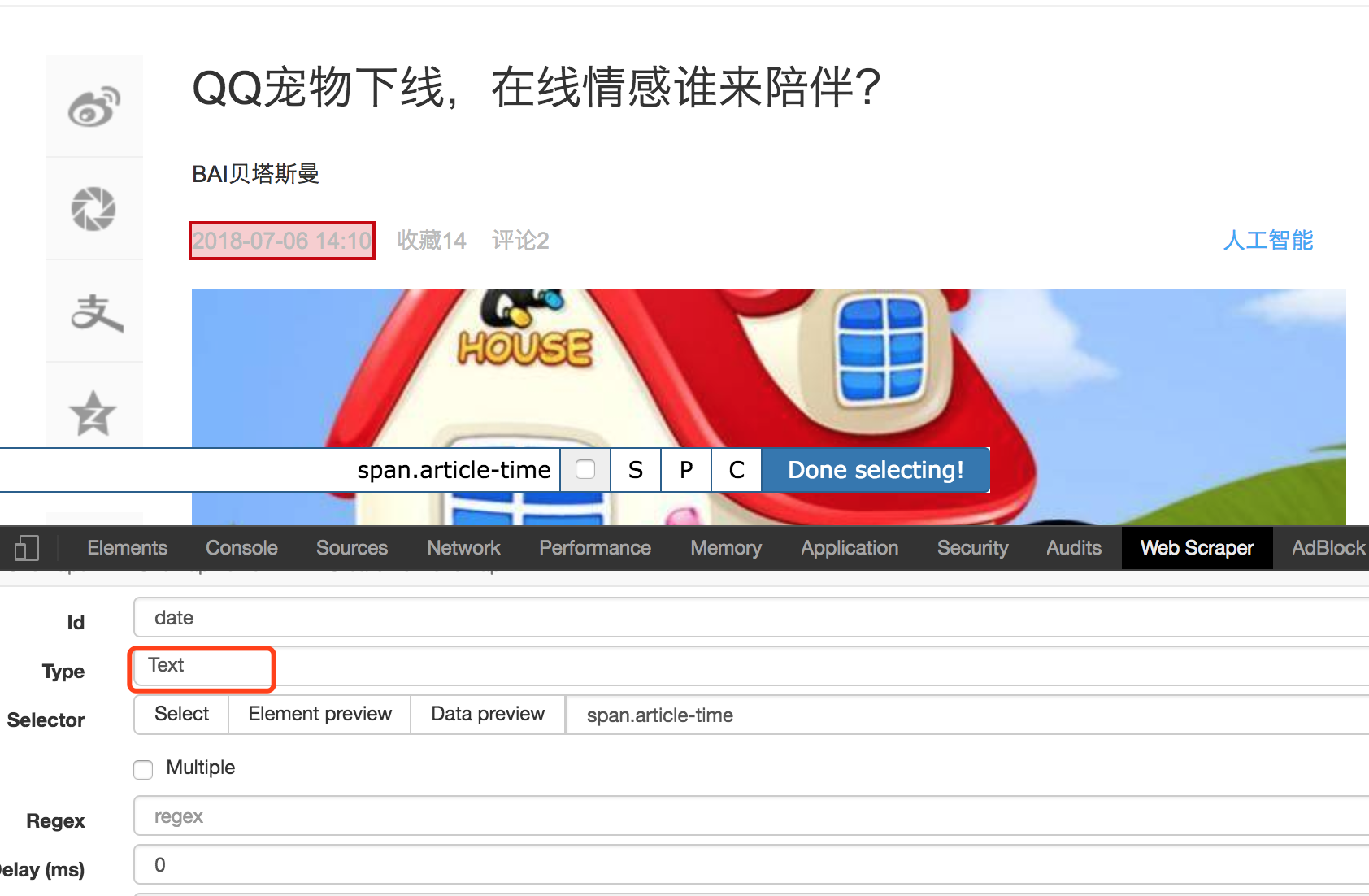
8、最后运行,抓出来的结果是这样的。

最后,关注公众号 古时的风筝 回复关键词 「二级页面」获取本例 sitemap

web scraper 抓取分页数据和二级页面内容的更多相关文章
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Fiddler:在PC和移动设备上抓取HTTPS数据包
Fiddler是一个免费的Web调试代理,支持任何浏览器.系统以及平台.这个工具是进行Web和App网络开发的必备工具,戳此处下载. 根据Fiddler官网的描述,具有以下六大特点: Web调试 性能 ...
- Fiddler基础用法-抓取浏览器数据包
Fiddler基础知识 Fiddler是强大的抓包工具,它的原理是以web代理服务器的形式进行工作的,使用的代理地址是:127.0.0.1,端口默认为8888,我们也可以通过设置进行修改. 代理就是在 ...
- Charles 如何抓取https数据包
Charles可以正常抓取http数据包,但是如果没有经过进一步设置的话,无法正常抓取https的数据包,通常会出现乱码.举个例子,如果没有做更多设置,Charles抓取https://www.bai ...
随机推荐
- java 基础知识小结
1. java 有三个求整的函数 math.floor () (floor 是地板的意思) 向下求整 math.ceil () (ceil 是天花板的意思 ) 向上求整 math.round() ...
- HrbustOJ 1564 螺旋矩阵
Description 对于给定的一个数n,要你打印n*n的螺旋矩阵. 比如n=3时,输出: 1 2 3 8 9 4 7 6 5 Input 多组测试数据,每个测试数据包含一个整数n(1<=n& ...
- sau交流学习社区--songEagle开发系列:Vue.js + Koa.js项目中使用JWT认证
一.前言 JWT(JSON Web Token),是为了在网络环境间传递声明而执行的一种基于JSON的开放标准(RFC 7519). JWT不是一个新鲜的东西,网上相关的介绍已经非常多了.不是很了解的 ...
- asp.net core系列 51 Identity 授权(下)
1.6 基于资源的授权 前面二篇中,熟悉了五种授权方式(对于上篇讲的策略授权,还有IAuthorizationPolicyProvider的自定义授权策略提供程序没有讲,后面再补充).本篇讲的授权方式 ...
- 一文带你认识Spring事务
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y Spring事务管理我相信大家都用得很多,但可能仅仅 ...
- java之servlet入门操作教程一续
本节主要是在java之servlet入门操作教程一 的基础上使用myeclipse实现自动部署的功能 准备: java之servlet入门操作教程一 中完成myFirstServlet项目的创建: ...
- headfirst设计模式(8)—适配器模式与外观模式
前言 这一章主要讲2个模式,一个是,适配器模式(负责将一个类的接口适配成用户所期待的),另外一个是外观模式(为子系统提供一个共同的对外接口),看完的第一反应是,为什么要把它们两放在同一章,难道它们有什 ...
- android Fragment中使用Toolbar
在Activity中可以直接使用 setSupportActionBar(toolbar); 就可以重写 onCreateOptionsMenu 和 onOptionsItemSelected 方法: ...
- idea解决Maven jar依赖冲突(四)
首先点击右侧的MavenProjects打开以下界面: 这个界面是maven的命令界面: 点击这个图标会进入如下界面: 左上角可以缩放,点击线可以取消冲突依赖,红色线为冲突依赖. 上图为无依赖冲突的s ...
- 使用CAS实现无锁列队-链表
#include <stdlib.h> #include <stdio.h> #include <pthread.h> #include <iostream& ...