简易数据分析 07 | Web Scraper 抓取多条内容

这是简易数据分析系列的第 7 篇文章。
在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息;
在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息;
今天我们要讲的是,如何抓取多个网页里的多类信息。
这次的抓取是在简易数据分析 05的基础上进行的,所以我们一开始就解决了抓取多个网页的问题,下面全力解决如何抓取多类信息就可以了。
我们在实操前先把逻辑理清:
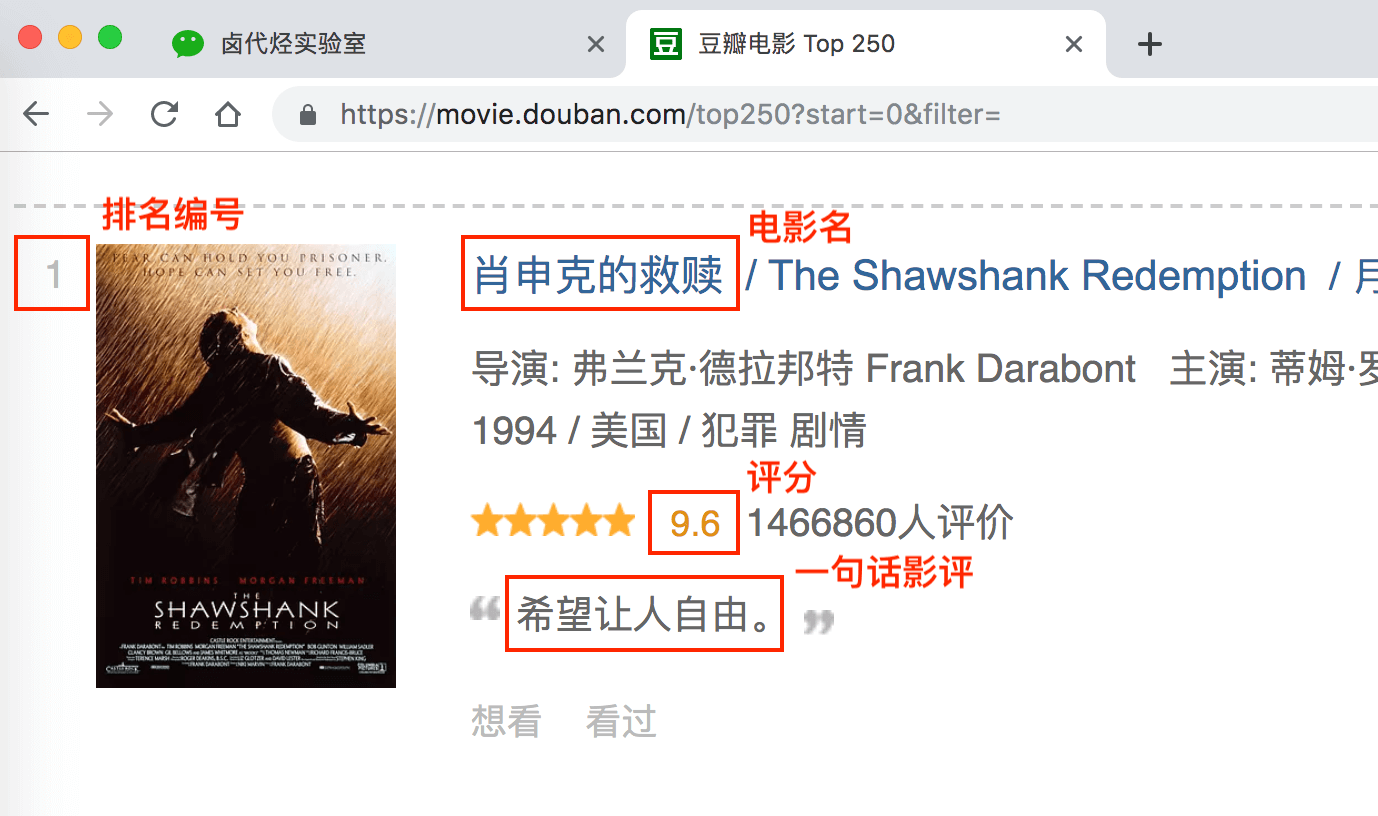
上几篇只抓取了一类元素:电影名字。这期我们要抓取多类元素:排名,电影名,评分和一句话影评。
根据 Web Scraper 的特性,想抓取多类数据,首先要抓取包裹多类数据的容器,然后再选择容器里的数据,这样才能正确的抓取。我画一张图演示一下:

我们首先要抓取多个 container(容器),再抓取 container 里的元素:编号、电影名、评分和一句话影评,当爬虫运行完后,我们就会成功抓取数据。
概念上搞清楚了,我们就可以讲实际操作了。
如果对以下的操作有疑问,可以看 简易数据分析 04 的内容,那篇文章详细图解了如何用 Web Scraper 选择元素的操作
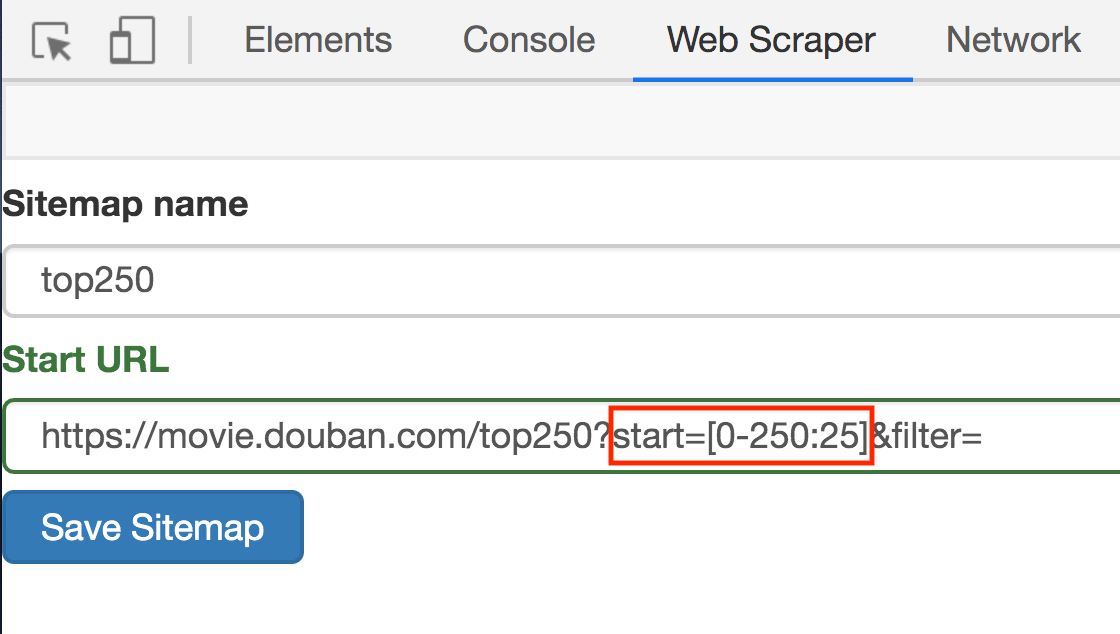
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据

2.删除掉旧的 selector,点击 Add new selector 增加一个新的 selector

3.在新的 selector 内,注意把 Type 类型改为 Element(元素),因为在 Web Scraper 里,只有元素类型才能包含多个内容。

我们勾选的元素区域如下图所示,确认无误后点击 Save selector 按钮,就会回退到上一个操作面板。
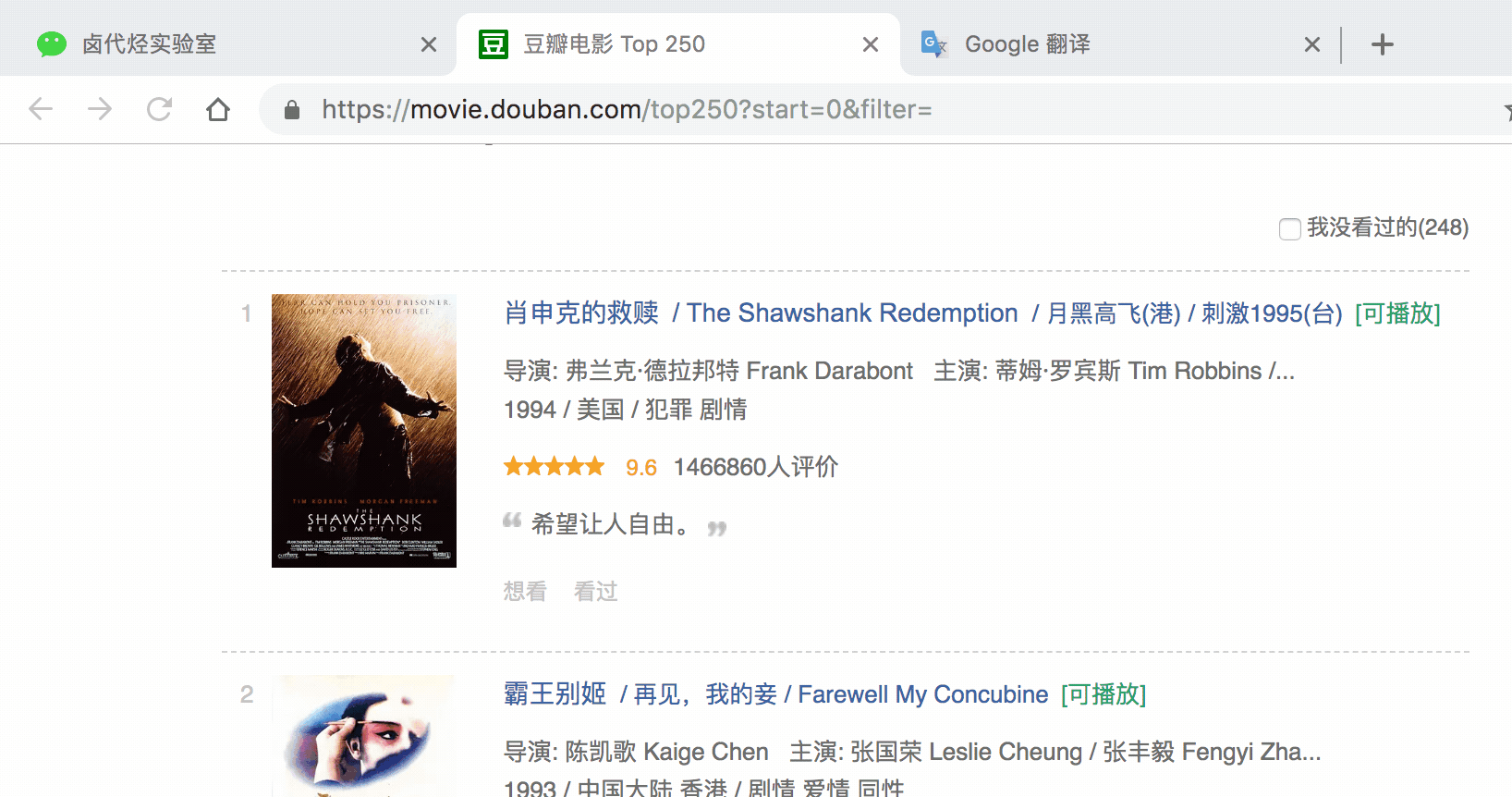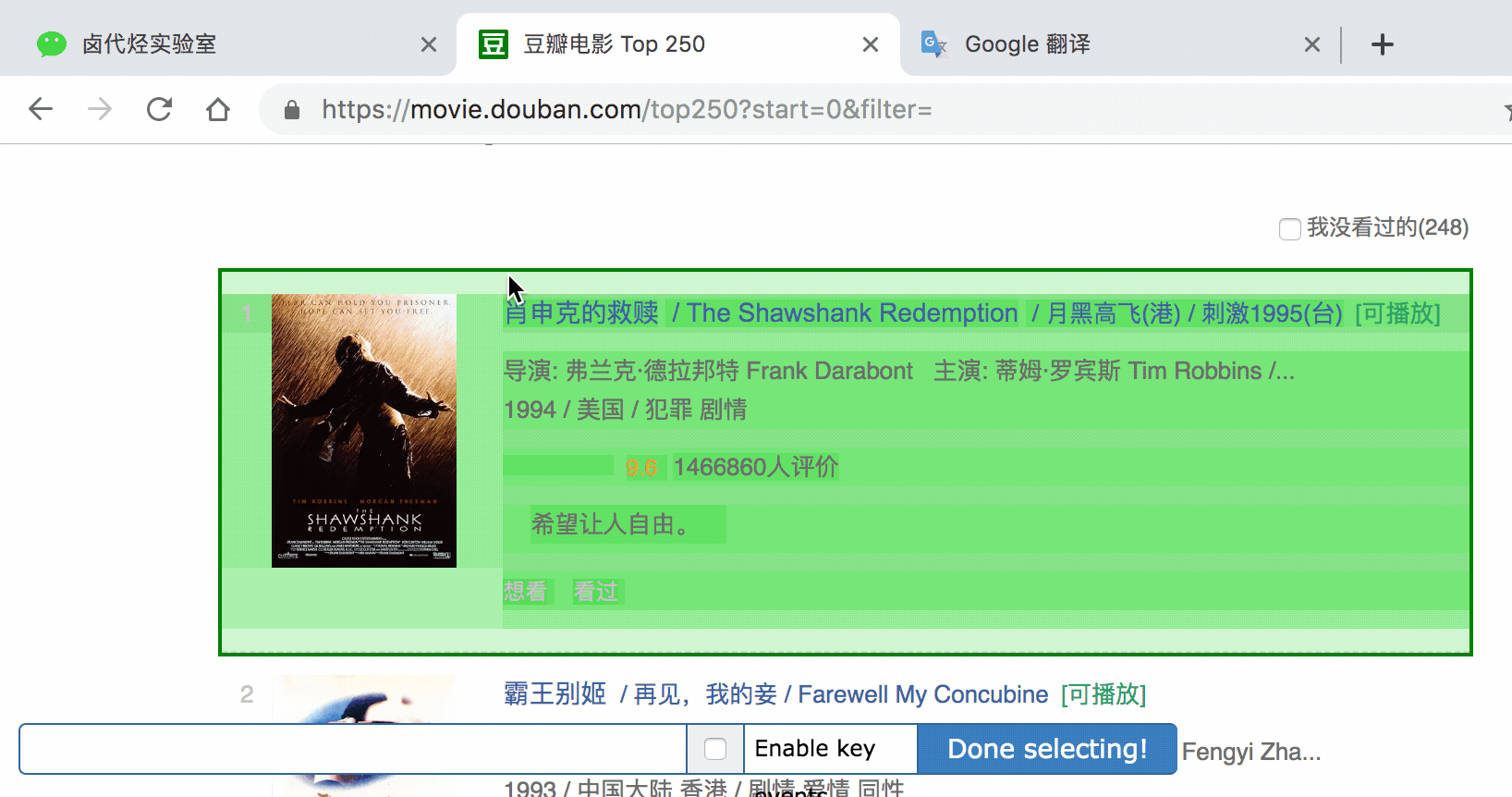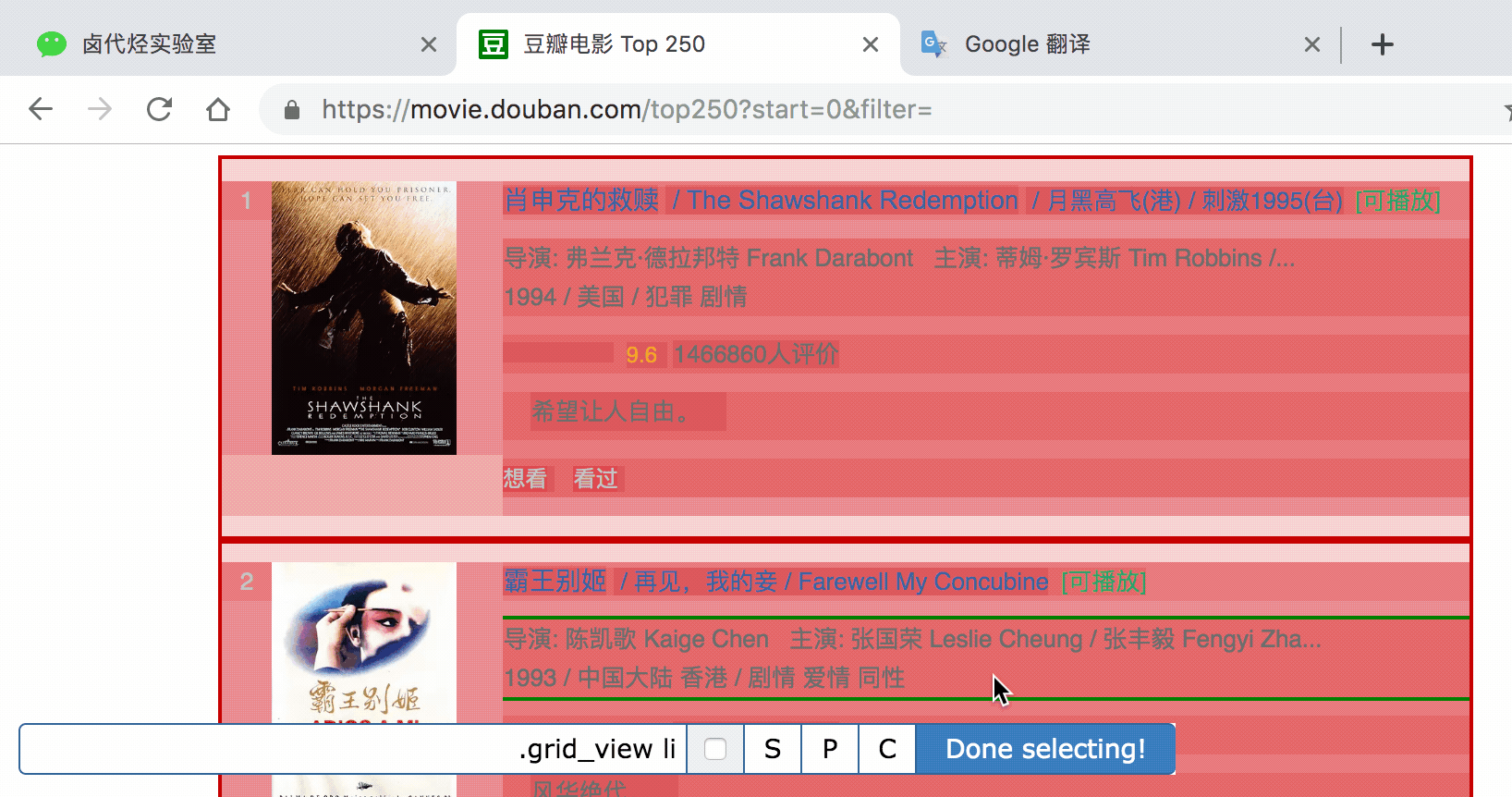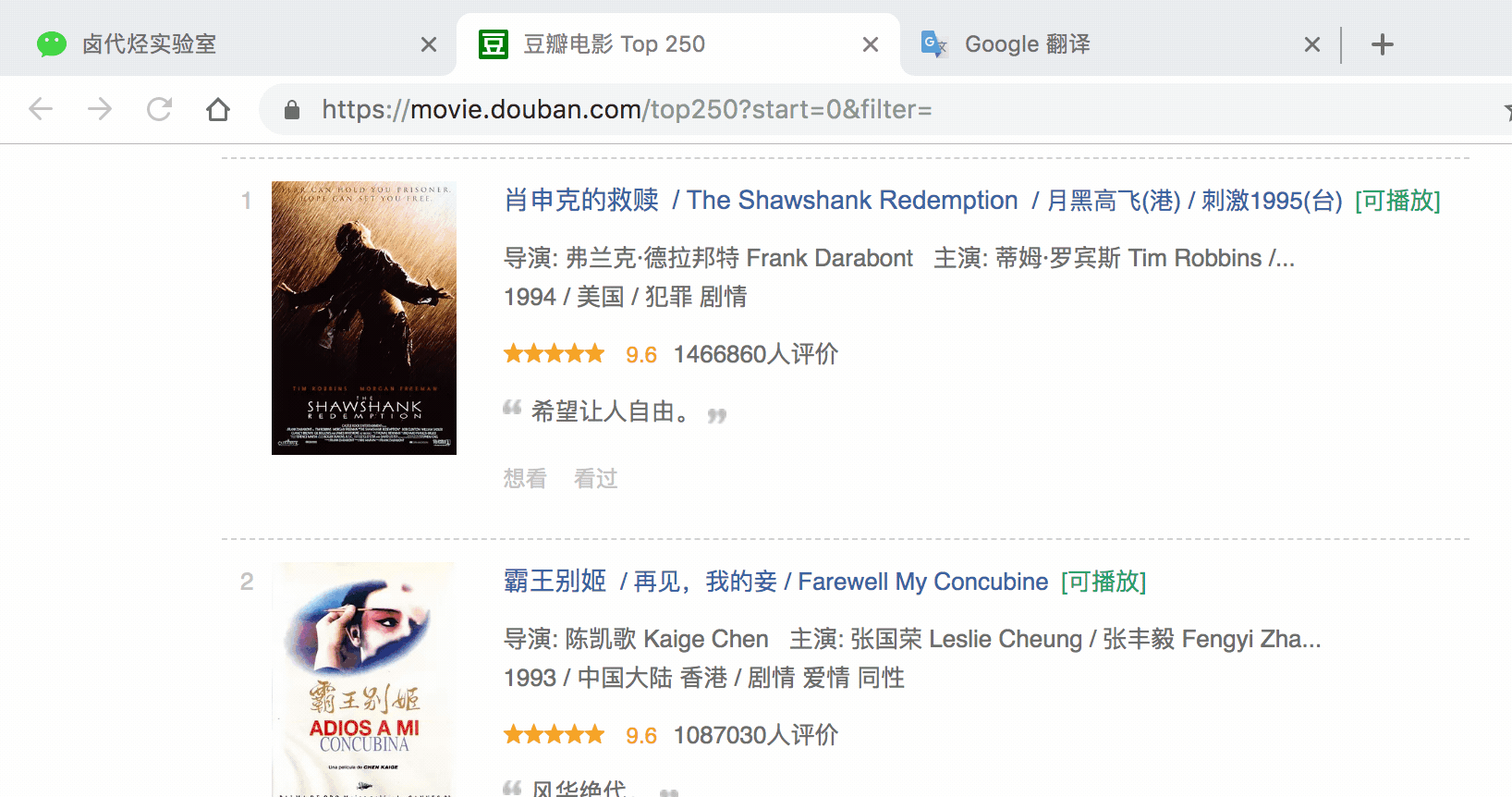
在新的面板里,点击刚刚创建的 selector 那行数据:

点击后我们就会进入一个新的面板,根据导航我们可知在 container 内部。

在新的面板里,我们点击 Add new selector,新建一个 selector,用来抓取电影名,类型为 Text,值得注意的是,因为我们是在 container 内选择文字的,一个 container 内只有一个电影名,所以多选不要勾选,要不然会抓取失败。

选择电影名的时候你会发现 container 黄色高亮,我们就在黄色的区域里选择电影名就好了。
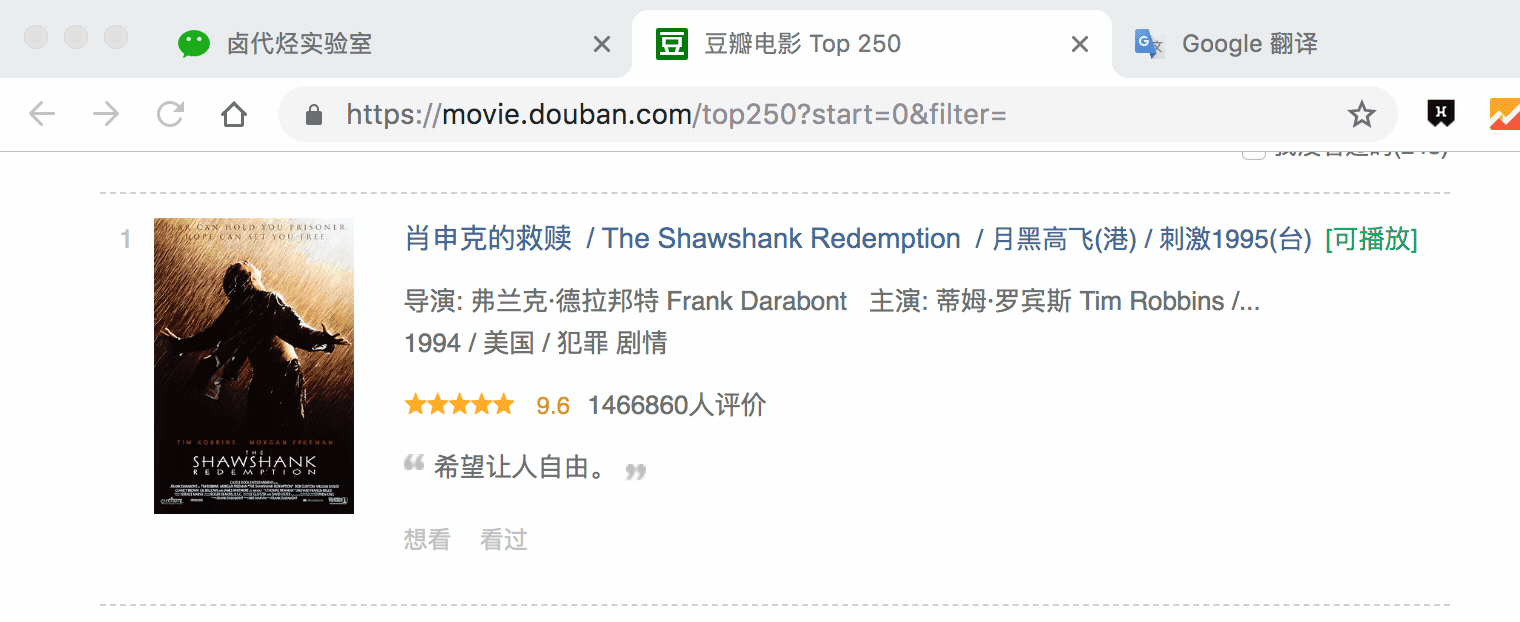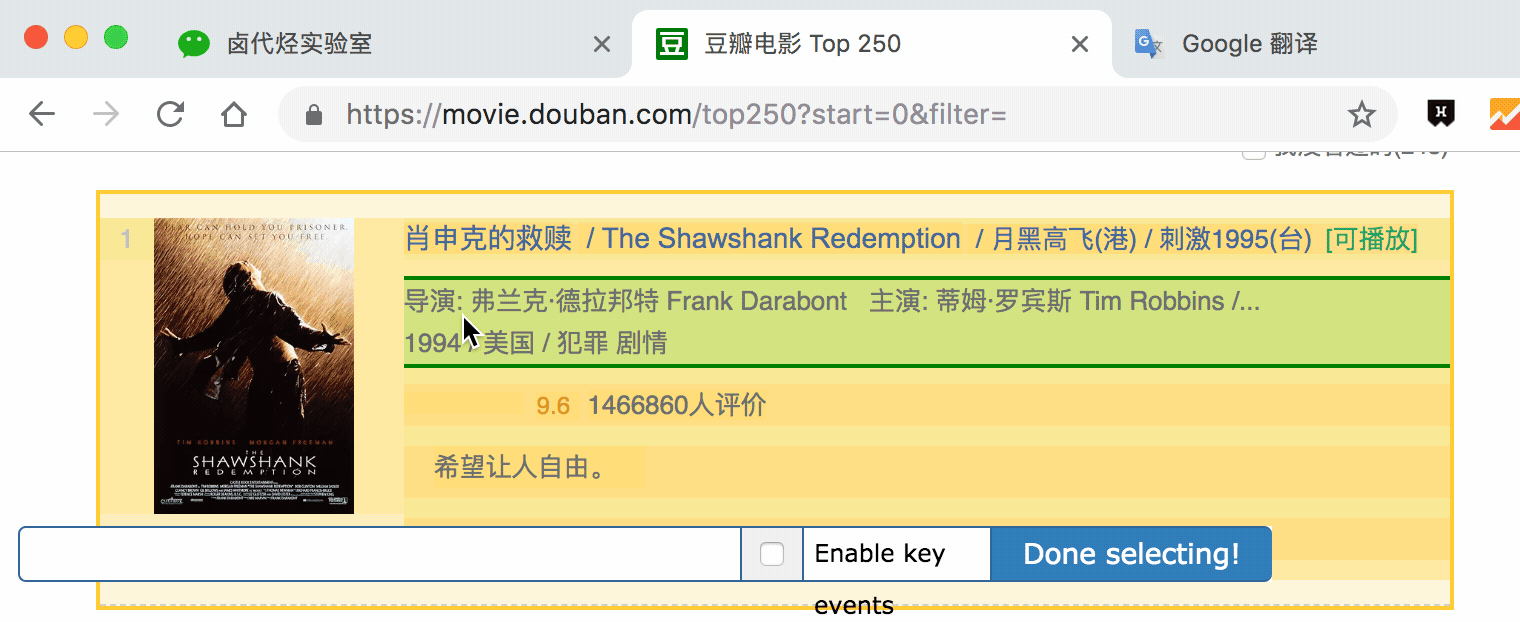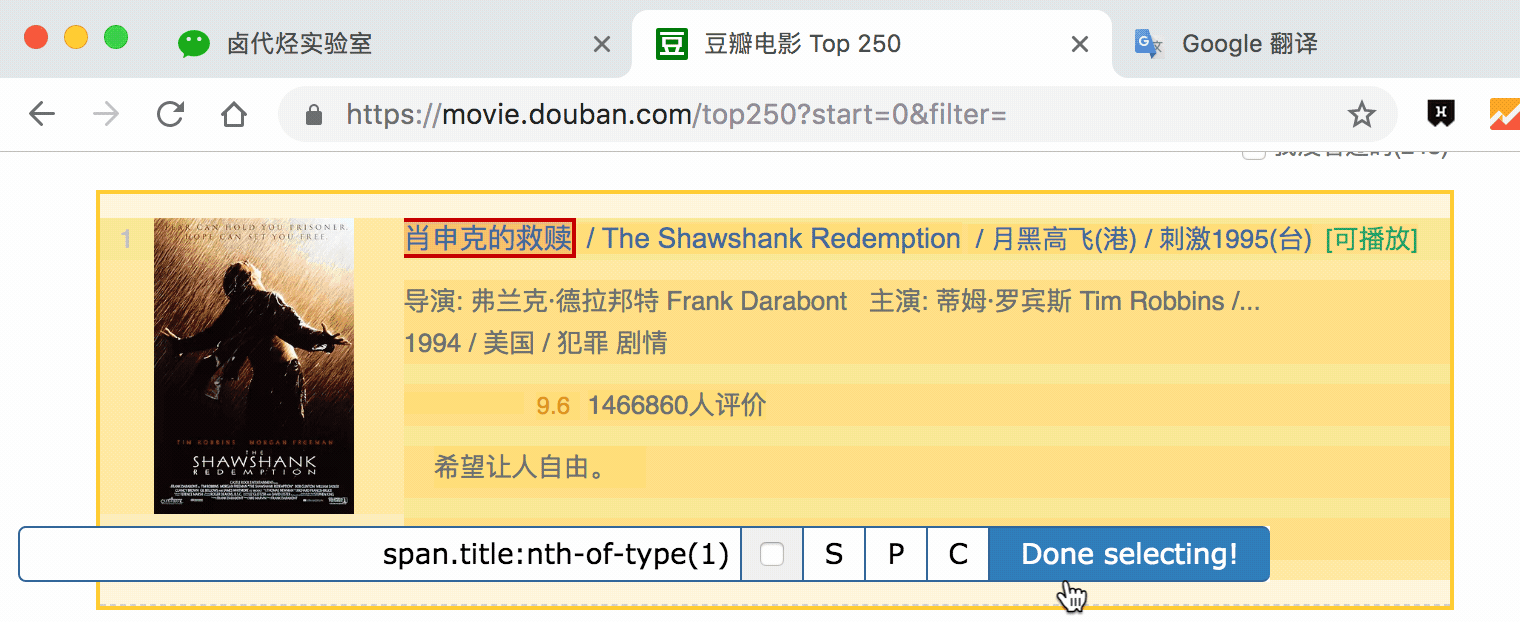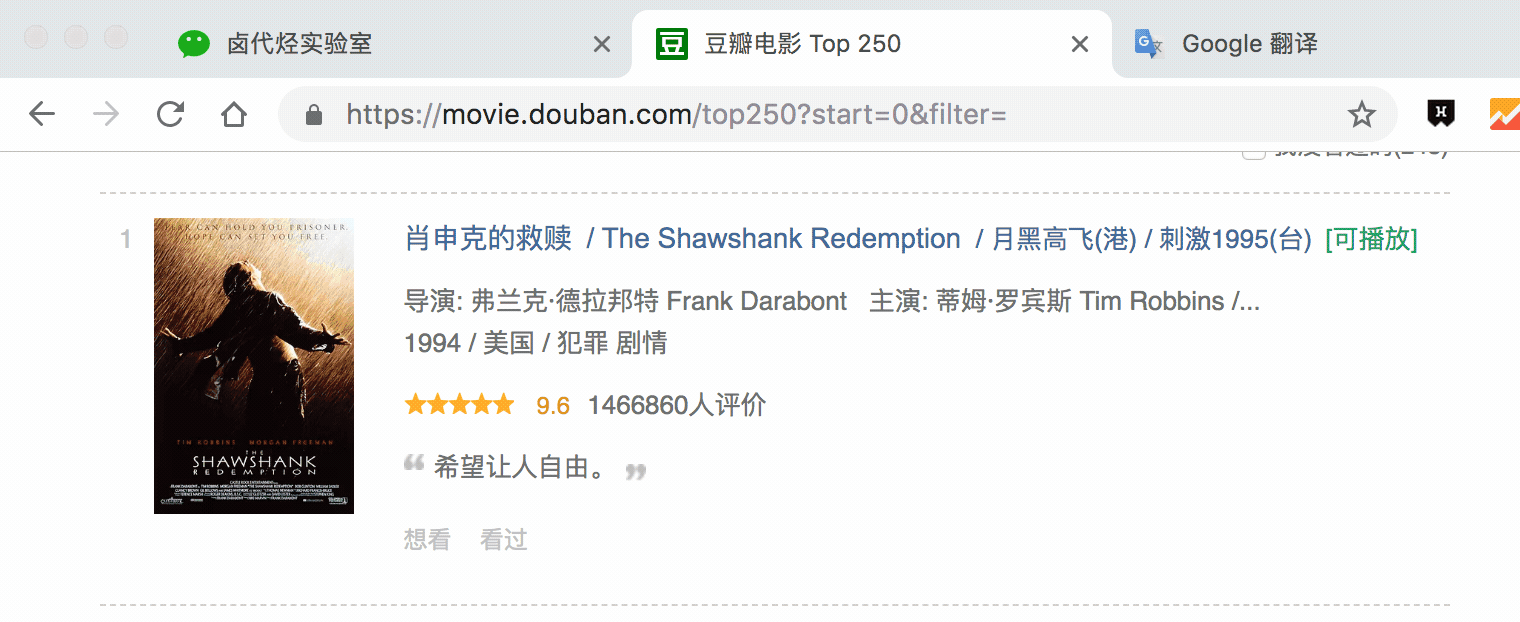
点击 Save selector 保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评,因为操作和上面一模一样,我这里就省略讲解了。
排名编号:

评分:

一句话影评:

我们可以在面板里观察我们选择的多个元素,一共有四个元素:分别为 name、number、score 和 review,类型都是 Text,不需要多选,父选择器都是 container。

我们可以点击 点击 Stiemap top250 下的 selector graph,查看我们爬虫选择元素的层级关系,确认正确后我们再点击 Stiemap top250 下的 Selectors,回到选择器展示面板。
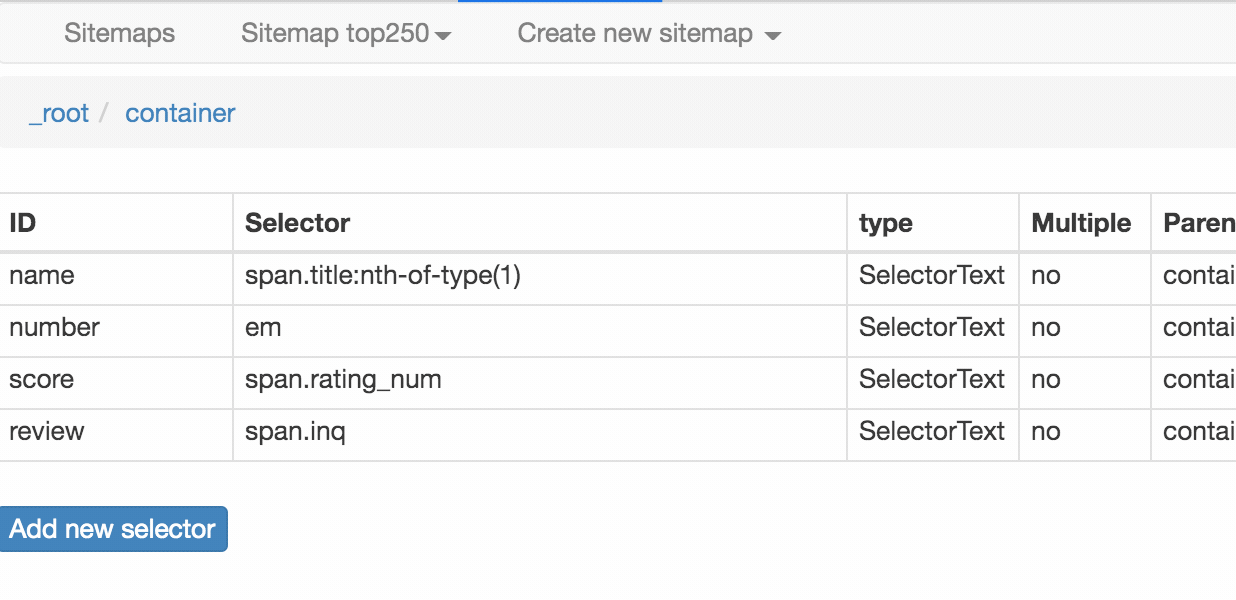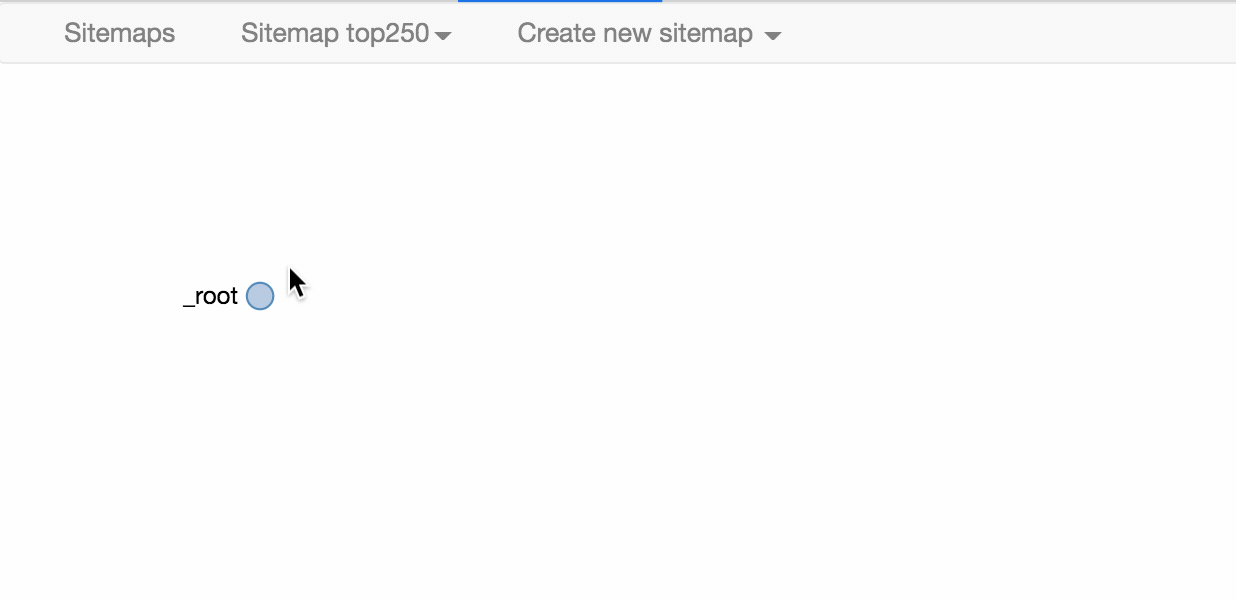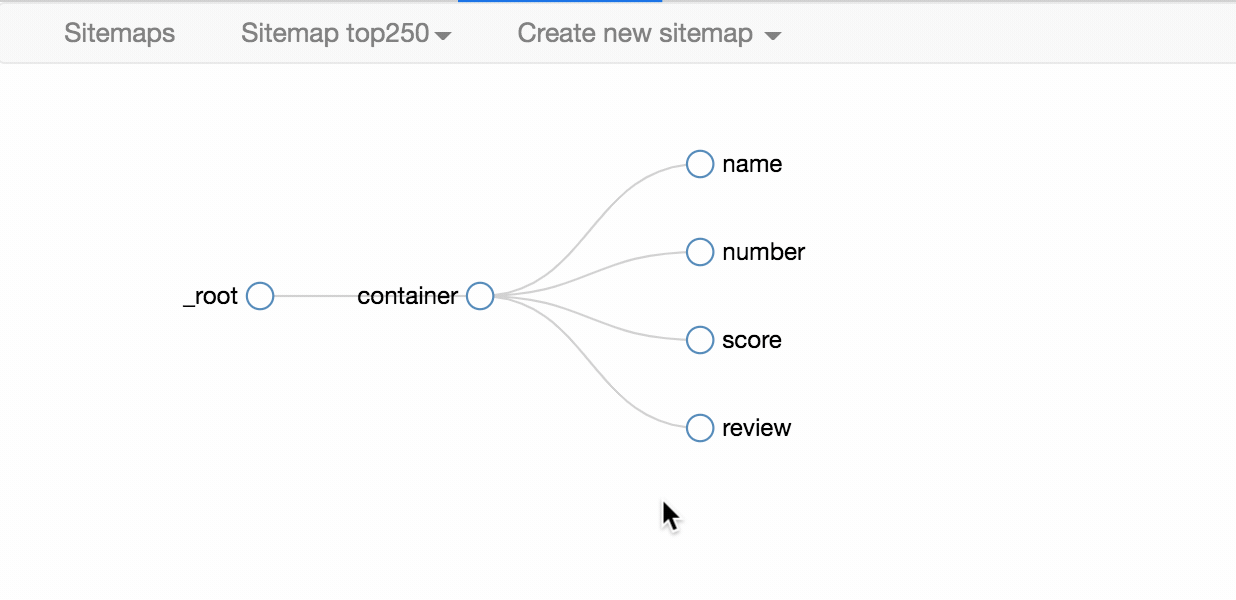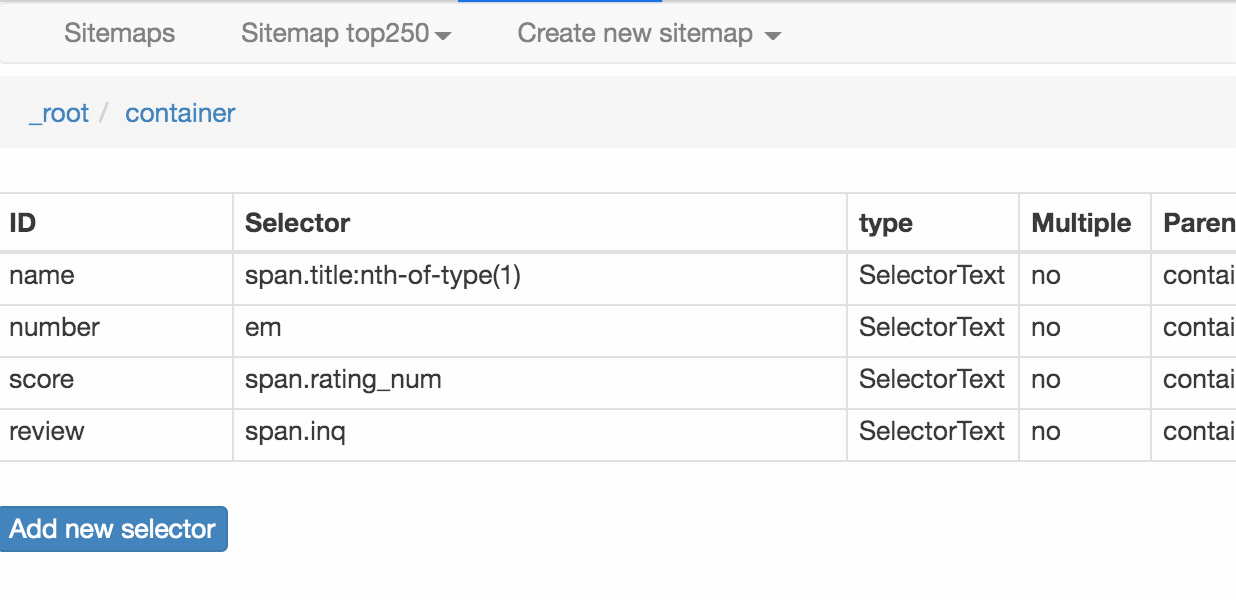
下图就是我们这次爬虫的层级关系,是不是和我们之前理论分析的一样?

确认选择无误后,我们就可以抓取数据了,操作在 简易数据分析 04 、 简易数据分析 05 里都说过了,忘记的朋友可以看旧文回顾一下。下图是我抓取的数据:

还是和以前一样,数据是乱序的,不过这个不要紧,因为排序属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
今天的内容其实还是比较多的,大家可以先消化一下,下一篇我们讲讲,如何抓取点击「加载更多」加载数据的网页内容。
这次的 sitemap 就分享给大家,大家可以导入到 Web Scraper 中进行实验,具体方法可以看我上一篇教程文章。
Sitemap:
{"_id":"top250","startUrl":["https://movie.douban.com/top250?start=[0-250:25]&filter="],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0},{"id":"score","type":"SelectorText","parentSelectors":["container"],"selector":"span.rating_num","multiple":false,"regex":"","delay":0},{"id":"review","type":"SelectorText","parentSelectors":["container"],"selector":"span.inq","multiple":false,"regex":"","delay":0}]}
推荐阅读:
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据

简易数据分析 07 | Web Scraper 抓取多条内容的更多相关文章
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
随机推荐
- Compile for Windows on Linux(交叉编译,在Linux下编译Windows程序),以OpenSSL为例
OpenSSL for Windows In earlier articles, we have looked at how to create a gcc build environment on ...
- 用 eric6 与 PyQt5 实现python的极速GUI编程(35篇PyQT和200多篇Python)
[题记] 我是一个菜鸟,这个系列是我的学习笔记. PyQt5 出来有一段时间了, PyQt5 较之 PyQt4 有一些变化,而网上流传的几乎都是 PyQt4 的教程,照搬的话大多会出错. eric6 ...
- vuejs 项目引入微信jssdk
一.导入依赖包 npm i -S weixin-js-sdk 二.前端页面使用 import wx from 'weixin-js-sdk' export default { created() { ...
- iOS登录及token的业务逻辑(没怎么用过,看各种文章总结)
http:是短连接. 服务器如何判断当前用户是否登录? // 1. 如果是即时通信类:长连接. // 如何保证服务器跟客户端保持长连接状态? // "心跳包" 用来检测用户是否在线 ...
- Thread中的start()方法和自己定义的run()方法有什么区别
在讲这个问题之前引入一下多线程的小知识吧 /*/windows系统中的应用程序来做说明 ,例如:扫雷程序,游戏进行的同时,可以同时记录分数,计算时间等. 其实一个应用程序就是一个可执行文件,中包含了一 ...
- kubernetes实战篇之docker镜像的打包与加载
系列目录 前面我们讲到了使用nexus搭建docker镜像仓库,操作还是有点复杂的,可能有的童鞋仅仅是想尝试kubernetes功能,并不想在搭建仓库上花费过多时间,但是又想在不同的主机之间传递镜像. ...
- SSM框架学习笔记_第1章_SpringIOC概述
第1章 SpringIOC概述 Spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的容器框架. 1.1 控制反转IOC IOC(inversion of controller)是一种概念 ...
- 2. 2.1查找命令——linux基础增强,Linux命令学习
2.1.查找命令 grep命令 grep 命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并 把匹配的行打印出来. 格式: grep [option] pattern [file] 可使用 ...
- JDK1.8之ConcurrentHashMap
目录 简介 JDK1.7 JDK1.8 重要属性 Node类 ForwardingNode类 原子操作和Unsafe类 重要方法 初始化表操作(initTable) 插入键值对(put和putVal) ...
- JcApiHelper 简单好用的.Net ApiHelper
一 背景 随着前端技术的不断发展,各种框架逐渐成熟,前端 Angular,React,Vue 三分天下.再加上移动端的崛起,前后端分离开发成为主流,前端后端代码混合开发的方式沦为被淘汰的局面.如今 M ...