[DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.1 训练/开发/测试集
对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验证集,最后一部分作为测试集(test).接下来我们开始对训练集执行训练算法,通过验证集或简单交叉验证集选择最好的模型.经过验证我们选择最终的模型,然后就可以在测试集上进行评估了.在机器学习的小数据量时代常见的做法是将所有数据三七分,就是人们常说的70%训练集集,30%测试集,如果设置有验证集,我们可以使用60%训练,20%验证和20%测试集来划分整个数据集.这是前几年机器学习领域公认的最好的测试与训练方式,如果我们只有100条/1000条/1W条数据,我们按照上面的比例进行划分是非常合理的,但是在大数据时代,我们现在的数据量可能是百万级,那么验证集和测试集占数据总量的比例会趋向变得更小.因为验证集的目的就是验证不同的算法检验那种算法更加有效,在大数据时代我们可能不需要拿出20%的数据作为验证集.比如我们有100W
那我们取1W条数据便足以找出其中表现最好的1-2种算法.同样地,根据最终选择的分类器,测试集的主要目的是正确评估分类器的性能.所以,如果拥有百万级数据我们只需要1000条数据,便足以评估单个分类器.准确评估分类器的性能
假设我们有100W条数据,其中1W条做验证集,1W条做测试集,训练集占98%,验证集和测试集各占1%.对于数据量过百万级别的数据我们可以使测试集占0.5%,验证集占0.5%或者更少.测试集占0.4%,验证集占0.1%.
经验之谈:要确保验证集和测试集的数据来自同一分布.
最后一点,就算没有测试集也不要紧,测试集的目的是对最终选定的神经网络系统做出无偏评估,如果不需要无偏评估也可以不设置测试集所以如果只有验证集没有测试集.我们要做的就是在训练集上训练尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型.因为验证集已经包含有测试集的数据,故不在提供无偏性能评估.当然,如果你不需要无偏评估,那就再好不过了.在机器学习如果只有训练集和验证集但是没有独立的测试集,这种情况下,训练集还是训练集,而验证集则被称为测试集.不过在实际应用中,人们只是把测试集当做简单交叉验证集使用,并没有完全实现该术语的功能.因为他们把验证集数据过度拟合到了测试集中.如果某团队跟你说他们只设置了一个训练集和一个测试集我会很谨慎,心想他们是不是真的有训练验证集.因为他们把验证集数据过渡拟合到了测试集中.让这些团队改变叫法,改称其为"训练验证集".
1.2 偏差/方差
偏差(Bias)方差(Variance)这两个概念易学难精,在深度学习的领域对偏差 方差的权衡研究甚浅.但是深度学习的却很少权衡的考虑这两个概念,都是分别得考虑偏差和方差.
欠拟合
"欠拟合(underfitting)"当数据不能够很好的拟合数据时,有较大的误差.
以下面这个逻辑回归拟合的例子而言:
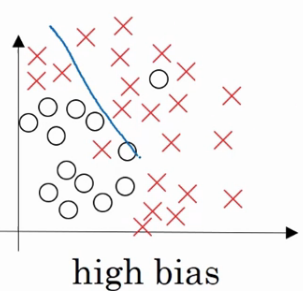
这就是high bias的情况.
过拟合
"过拟合(overfitting)"如果我们拟合一个非常复杂的分类器,比如深度神经网络或者含有隐藏神经的神经网络,可能就非常适用于这个数据集,但是这看起来不是一种很好的拟合方式,分类器方差较高,数据过度拟合
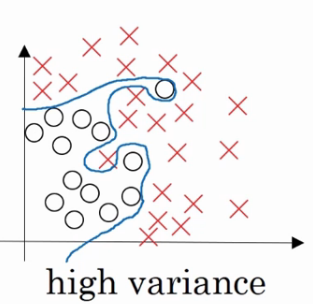
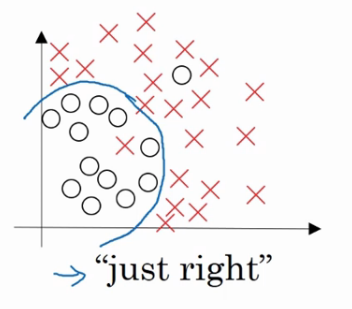
适度拟合
复杂程度市中,数据拟合适度的分类器,数据拟合程度相对合理,我们称之为"适度拟合"是介于过拟合和欠拟合中间的一类.
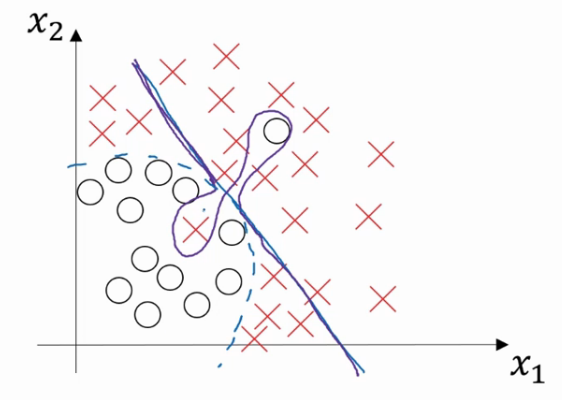
在这样一个只有x1和x2两个特征的二维数据集中,我们可以绘制数据,将偏差和方差可视化.但是在高维空间数据中,会直属局和可视化分割边界无法实现.但我们可以通过几个指标来研究偏差和方差.
高方差高偏差
高偏差指的是无法很好的拟合数据,高偏差指的是数据拟合灵活性过高,曲线过于灵活但是还包含有过度拟合的错误数据.
通过验证集/训练集判断拟合
"过拟合":训练集中错误率很低,但是验证集中错误率比验证集中高很多.方差很大.
"欠拟合":训练集中错误率相对比较高,但是验证集的错误率和训练集中错误率差别不大.偏差很大.
偏差和方差都很大: 如果训练集得到的错误率较大,表示不能很好的拟合数据,同时验证集上的错误率甚至更高,表示不能很好的验证算法.这是偏差和方差都很大的情况.
较好的情况: 训练集和验证集上的错误率都很低,并且验证集上的错误率和训练集上的错误率十分接近.

以上分析的前提都是假设基本误差很小,训练集和验证集数据来自相同分布,如果没有这些前提,分析结果会更加的复杂.
1.3 参数调节基本方法
初始训练完成后,首先看算法的偏差高不高,如果偏差过高,试着评估训练集或训练数据的性能.如果偏差真的很大,甚至无法拟合数据,现在就要选择一个新的网络.比如有更多隐层或者隐藏单元的网络.或者花费更多时间训练算法或者尝试更先进的优化算法.(ps:一般来讲,采用规模更大的网络通常会有帮助,延长训练时间不一定有用,但是也没有坏处,训练学习算法时,会不断尝试这些方法,知道解决掉偏差问题,这是最低标准,通常如果网络足够大,一般可以很好的拟合训练集)
一旦训练集上的偏差降低到一定的水平,可以检查一下方差有没有问题.为了评估方差我们要查看验证集性能.如果验证集和训练集的错误率误差较大即方差较大,最好的方法是采用更多数据.如果不能收集到更多的数据,我们可以采用正则化来减少过拟合.
我们需要选择正确的方法,不断迭代改进,如果是偏差本身比较大,准备更多的训练数据也没有什么用,所以一定要看清是哪方面出了问题.一般来讲选择正确的方法,使用更大更深的网络,更多的数据可以得到很好的效果
[DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习使用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.9 归一化Normaliation 训练神经网络,其中一个加速训练的方法就是归一化输入(normalize inputs). 假设我们有一个 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 mini-batch gradient descent mini-batch梯度下降法 我们将训练数据组合到一个大的矩阵中 \(X=\b ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
随机推荐
- java_web学习(六) request对象中的get和post差异
1.get与post的区别 Get和Post方法都是对服务器的请求方式,只是他们传输表单的方式不一样. 下面我们就以传输一个表单的数据为例,来分析get与Post的区别 1.1 get方法 jsp中 ...
- C++课程设计类作业2
不要问我一个晚上在干啥,就写写这种烦到极点的类,啰嗦! #include <bits/stdc++.h> using namespace std; class complexed { pu ...
- You can Solve a Geometry Problem too(线段求交)
http://acm.hdu.edu.cn/showproblem.php?pid=1086 You can Solve a Geometry Problem too Time Limit: 2000 ...
- SSH中后台传到前台一个信息集合,tr td中怎么进行排列,类似在一个div里排列书籍
总觉得描述问题不对,这里详细说一下,就是把下面图片变成排列整齐,一行四个,多出来的两个排到下一行. 我问过群里的,给的答案都有些简介:1:后台排好了,前台循环出来: 2:前台直接循环,多出来的加< ...
- [国嵌攻略][173][BOA嵌入式服务器移植]
1.解压boa嵌入式web服务 tar zxvf boa-0.94.13.tar.gz 2.进入src目录生成配置文件 ./configure 3.修改生成的Makefile CC=arm-linux ...
- Linq学习(主要参考linq之路)----2LINQ方法语法
方法语法:Fluent Syntax 方法语法是非常灵活和重要的.我们这里讲描述使用连接查询运算符的方式来创建复杂的子查询,方法语法的本质是通过扩展方法和Lambda表达式来创建查询. eg1: st ...
- gettype
取得变量的类型. 语法: string gettype(mixed var); 返回值: 字符串 函数种类: PHP 系统功能 内容说明 本函数用来取得变量的类型.返回的类型字符串可能为下列字符串其中 ...
- 网站地图怎么做?dedecms网站地图制作方法听语音
网站地图怎么生成?下面分享织梦dedecms系统网站地图的生成方式,怎么制作网站地图,方法很简单.下面介绍一下网站地图优化方法及制作方法. 工具/原料 一个网站 方法/步骤 第一步 登录网站后台 第二 ...
- dede 提交表单 发送邮件
第一步:要到dede后台设置好邮箱的资料,并且确定所用的邮箱开启了smtp 第二步:找到/plus/diy.php在 [cce]$query = "INSERT INTO `{$diy-&g ...
- dedecms列表页有图调用缩略图无图留空的方法
默认情况下,织梦的文章列表页会调用出当前栏目下的文章列表,并且调用出每个文章的缩略图:如果文章本身就有图,会调用出一张小图,如果没有,则会显示默认的织梦图片.这种处理方式有时候比较影响美观,其实可以修 ...