内存与IO的交换【转】

用户进程的内存页分为两种:
- file-backed pages(文件背景页)
- anonymous pages(匿名页)
比如进程的代码段、映射的文件都是file-backed,而进程的堆、栈都是不与文件相对应的、就属于匿名页。
file-backed pages在内存不足的时候可以直接写回对应的硬盘文件里,称为page-out,不需要用到交换区(swap);而anonymous pages在内存不足时就只能写到硬盘上的交换区(swap)里,称为swap-out。
file-backed pages(文件背景页)
对于有文件背景的页面,程序去读文件时,可以通过read也可以通过mmap去读。当你通过任何一种方式从磁盘读文件时,内核都会给你申请一个page cache,来缓存硬盘上的内容。这样的话,读过一遍的数据,本进程或其他进程下次再读的时候就直接从page cache里去拿,就很快了,提升系统的整体性能。因此用户的read/write实际上是跟page cache的相互拷贝。
而用户的mmap则会将一段虚拟地址(3G)以下映射到page cache上,这样的话,用户就可以通过读写这段虚拟地址来修改文件内容,省去了内核和用户之间的拷贝。
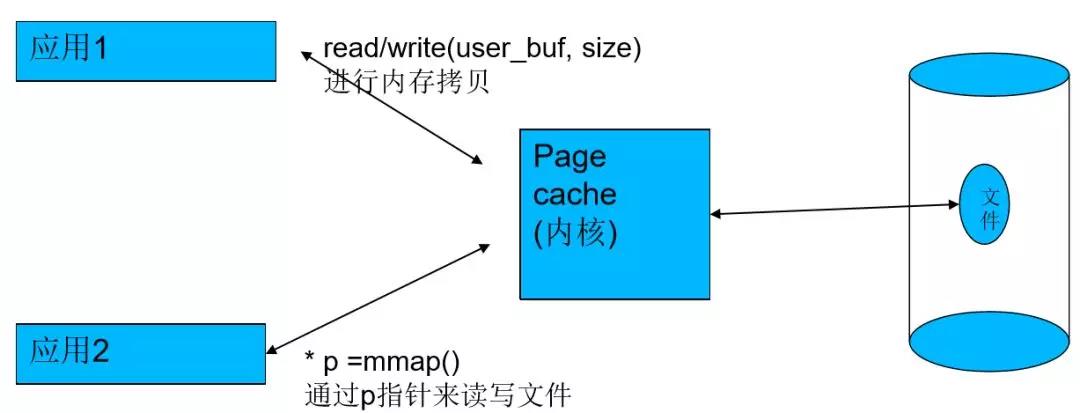
所以文件对于用户程序来讲其实只是内存,page cache就是磁盘中文件的一个副本。可以通过 “echo 3 > /proc/sys/vm/drop_cache” 来清cache。清掉之后,进程第一次读文件就会变慢。
通过free命令可以看到当前page cache占用内存的大小,free命令中会打印buffers和cached(有的版本free命令将二者放到一起了)。通过文件系统来访问文件(挂载文件系统,通过文件名打开文件)产生的缓存就由cached记录,而直接操作裸盘(打开/dev/sda设备去读写)产生的缓存就由buffers记录。
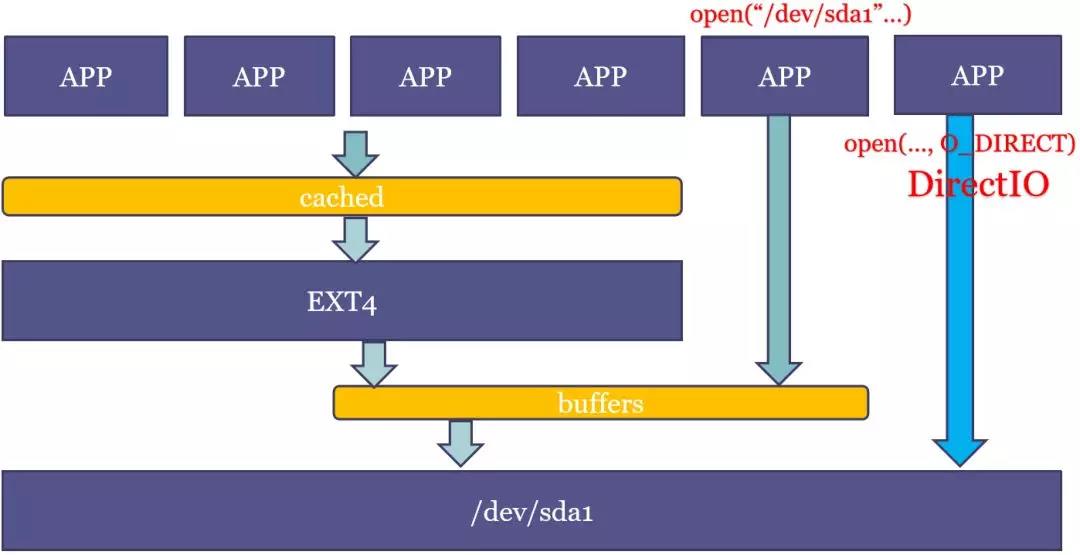
实际上文件系统本身再读写文件就是操作裸分区的方式,用户态也可以直接操作裸盘,像dd命令操作一个设备名也是直接访问裸分区。那么,通过文件系统读写的时候,就会既有cached又有buffers。从图中可以看到,文件名等元数据和文件系统相关,是进cached,实际的数据缓存还是在buffers。例如,read一个文件(如ext4文件系统)的时候,如果文件cache命中了,就不用走到ext4层,从vfs层就返回了。
当然,还可以在open的时候加上O_DIRECT标记,做直接IO,就连buffers都不进了,直接读写磁盘。
anonymous pages(匿名页)
没有文件背景的页面,即匿名页(anonymous page),如堆,栈,数据段等,不是以文件形式存在,因此无法和磁盘文件交换,但可以通过硬盘上划分额外的swap分区或使用swap文件进行交换。swap分区可以将不活跃的页交换到硬盘中,缓解内存紧张。swap分区可以当做针对匿名页伪造的文件背景。
页面回收(reclaim)
- 有文件背景的数据实际上就是page cache,但page cache不能无限增加,不能说慢慢的所有文件都缓存到内存了。肯定要有一个机制,让不常用的文件数据从page cache刷出去。内核中有一个水位控制的机制,在系统内存不够用的时候,会触发页面回收。
- 对于没有文件背景的页面即匿名页,比如堆、栈、数据段,如果没有swap分区,不能与磁盘交换,就要常驻内存了。但是常驻内存的话,就会吃内存,可以通过给硬盘搞一个swap分区或硬盘中创建一个swap文件让匿名页也能交换到磁盘上。可认为是为匿名页伪造的文件背景。swap分区或swap文件实际上最终是到达了增大内存的效果。当然,如果频繁交换的话,被交换出去的数据的访问就会慢一些,因为要有IO操作了。
1. 水位(watermark)控制:
内核中有三个水位:
- min:如果剩余内存减少到触及这个水位,可认为内存严重不足,当前进程就会被堵住,kernel会直接在这个进程的进程上下文里面做内存回收(direct reclaim)。
- low:当剩余内存慢慢减少,触到这个水位时,就会触发kswapd线程的内存回收。
- high: 进行内存回收时,内存慢慢增加,触到这个水位时,就停止回收。
由于每个ZONE是分别管理各自内存的,因此每个ZONE都有这三个水位
2. swapness:
回收的时候,是回收有文件背景的页还是匿名页还是都会回收呢,可通过/proc/sys/vm/swapness来控制让谁回收多一点点。swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。当然,它们的回收方法都是一样的LRU算法,即最近最少使用的页会被回收。

3. 如何计算水位:
/proc/sys/vm/min_free_kbytes 是一个用户可配置的值,默认值是min_free_kbytes = 4 * sqrt(lowmem_kbytes)。然后根据min算出来low和high水位的值:low=5/4min,high=6/4min。
脏页的写回
sync是用来回写脏页的,脏页不能在内存中呆的太久,因为如果突然断电没有写到硬盘的话脏数据就丢了,另一方面如果攒了很多一起写回也会明显占用CPU时间。
那么脏页时候写回呢?脏页回写的时机由时间和空间两方面共同控制:
时间:
- dirty_expire_centisecs: 脏页的到期时间,或理解为老化时间,单位是1/100s,内核中的flusher thread会检查驻留内存的时间超过dirty_expire_centisecs的脏页,超过的就回写。
- dirty_writeback_centisecs:内核的flusher thread周期性被唤醒(wakeup_flusher_threads())的时间间隔,每次被唤醒都会去检查是否有脏页老化了。如果将这个值置为0,则flusher线程就完全不会被唤醒了。
空间:
- dirty_ratio: 一个写磁盘的进程所产生的脏页到达这个比例时,这个进程自己就会去回写脏页。
- dirty_background_ratio: 如果脏页的数量超过这个比例时,flusher线程就会启动脏页回写。
所以:
- 即使只有一个脏页,那如果它超时了,也会被写回。防止脏页在内存驻留太久。dirty_expire_centisecs这个值默认是3000,即30s,可以将其设置得短一些,这样掉电后丢失的数据会更少,但磁盘写操作也更密集。
- 不能有太多的脏页,否则会给磁盘IO造成很大压力,例如在内存不够做内存回收时,还要先回写脏页,也会明显耗时。
需要注意的是,在达到dirty_background_ratio后,flusher线程(名为“[flush-devname]”)开始回写,但由于写磁盘速度慢,如果此时应用进程还在不停地写磁盘,flusher线程回写没那么快,那么就会导致进程的脏页达到dirty_ratio,这时这个进程就会去回写脏页而导致write被堵住。也就是说dirty_background_ratio通常是比dirty_ratio小的。
脏页都是指有文件背景的页面,匿名页不会存在脏页。从/proc/meminfo的’Dirty’一行可以看到当前系统的脏页有多少,用sync命令可以刷掉。
zRAM机制
不用swap分区,也可以用zRAM机制来缓解内存紧张: 从内存里拿出一段内存空间(compressed block),作为交换空间模拟硬盘的交换分区,用来交换匿名页,并且让kernel看到的物理内存大小不包括这段内存。而这段交换空间自带透明压缩功能,即交换到这块zRAM分区时,Linux会自动将这块匿名页压缩存放。系统访问这块页面的内容时,产生page fault后从交换分区去拿,这时Linux给你透明解压再交换出来。
使用zRAM的好处,就是访存比访问硬盘或flash的速度提高很多,且不用考虑寿命问题,并且由于这段内存是压缩后存储的,因此可以存更多的数据,虽然占用了一段内存,但实际可以存更多的数据,也达到了增加内存的效果。缺点就是压缩要占用CPU时间。
Android里面普遍使用了zRAM技术,由于zRAM牺牲了CPU时间,所以交换次数还是越少越好。像Android和windows,内存越大越好,因为发生交换的几率就小。这样两个进程相互切换(如微博和微信)时就会变得流畅,因为内存足够的话,后台进程无需被换进swap分区或被OOM杀掉。当然如果你只打打电话,就没必要大内存啦。
本篇内容实际上来自于宋宝华老师讲课的内容,更多内容关注阅马场公众号。
内存与IO的交换【转】的更多相关文章
- java使用siger 获取服务器硬件信息(CPU 内存 网络 io等)
通过使用第三方开源jar包sigar.jar我们可以获得本地的信息 1.下载sigar.jar sigar官方主页 sigar-1.6.4.zip 2.按照主页上的说明解压包后将相应的文件copy到j ...
- [转帖]linux下CPU、内存、IO、网络的压力测试,硬盘读写速度测试,Linux三个系统资源监控工具
linux下CPU.内存.IO.网络的压力测试,硬盘读写速度测试,Linux三个系统资源监控工具 https://blog.51cto.com/hao360/1587165 linux_python关 ...
- VPS性能测试:CPU内存,硬盘IO读写,带宽速度,UnixBench和压力测试
现在便宜的VPS主机越来越多了,一些美国的VPS主机甚至给出1美元一月的VPS,堪比虚拟主机还要便宜,巨大的价格优势吸引不少人购买和使用,而近些年来国内的主机商也开始意识到便宜的VPS对草根站长的诱惑 ...
- Cgroups控制cpu,内存,io示例
Cgroups是control groups的缩写,最初由Google工程师提出,后来编进linux内核. Cgroups是实现IaaS虚拟化(kvm.lxc等),PaaS容器沙箱(Docker等)的 ...
- linux下的CPU、内存、IO、网络的压力测试
linux下的CPU.内存.IO.网络的压力测试 要远程测试其实很简单了,把结果放到一个微服务里直接在web里查看就可以了,或者同步到其他服务器上 一.对CPU进行简单测试: 1.通过bc命令计算特 ...
- 如何使用 Docker 来限制 CPU、内存和 IO等资源?
如何使用 Docker 来限制 CPU.内存和 IO等资源?http://www.sohu.com/a/165506573_609513
- [转帖]linux下的CPU、内存、IO、网络的压力测试
linux下的CPU.内存.IO.网络的压力测试 https://www.cnblogs.com/zhuochong/p/10185881.html 一.对CPU进行简单测试: 1.通过bc命令计算特 ...
- 转载: 一、linux cpu、内存、IO、网络的测试工具
来源地址: http://blog.csdn.net/wenwenxiong/article/details/77197997 记录一下 以后好找.. 一.linux cpu.内存.IO.网络的测试工 ...
- Cgroups控制cpu,内存,io示例【转】
本文转载自:https://www.cnblogs.com/yanghuahui/p/3751826.html 百度私有PaaS云就是使用轻量的cgoups做的应用之间的隔离,以下是关于百度架构师许立 ...
随机推荐
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- 如何在eclipse中快速debug到想要的参数条件场景下
前言 俗话说,工欲善其事必先利其器. 对于我们经常使用的开发工具多一些了解,这也是对我们自己工作效率的一种提升. 场景 作为开发,我们经常会遇到各种bug,大部分的bug很明确,我们直接可以打断点定位 ...
- vue.js window.removeEventListener 移除
vue项目中的小坑记录下,想要移除window的addEventListener,需要把后面的function挂在到this上,removeEventListener 和 addEventListen ...
- Redis集群架构
Redis集群概述 集群的核心意义只有一个:保证一个节点出现了问题之后,其他的节点可以继续提供服务使用. Redis基础部分讲解过主从配置:对于主从配置可以有两类:一主二从,层级关系.开发者一主二从是 ...
- Workbooks 对象的 Open 方法参数说明
Workbooks 对象的 Open 方法参数说明 打开一个工作簿. expression.Open(FileName, UpdateLinks, ReadOnly, Format, Password ...
- python实现列表的排序
群里有同行遇到这样一个面试题:有一个整数构成的列表,需要给这个列表进行从小到大存入到另一个列表中. 本身排序可以用python的内置函数sort和sorted,但题目的要求是手动实现. 看起来很简单, ...
- mongo connections url string 的问题
摘要 driver 连接Mongo DB的url其实很简单,就是几个变量拼接成一个url,和关系型数据库没什么不同.但是因为mongo有单个instance和replicaSet不同的部署策略,还有m ...
- Castle Windsor 的动态代理类如何获取实际类型
问题 在实际开发过程当中我们可能会针对某些类型使用动态代理技术(AOP),注入了一些拦截器进行处理,但是一旦某个类型被动态代理了,那么就会生成一个代理类.这个时候在该类内部使用 GetType() 方 ...
- Java实现单链表
真正的动态数据结构(引用和指针) 优点:真正的动态,不需要处理固定容量的问题. 缺点:丧失随机访问的能力. 链表就像寻宝,我们拿到藏宝图开始出发寻宝,每找到一个地方后,里面藏着下一步应该去哪里寻找.一 ...
- 分享一些 Kafka 消费数据的小经验
前言 之前写过一篇<从源码分析如何优雅的使用 Kafka 生产者> ,有生产者自然也就有消费者. 建议对 Kakfa 还比较陌生的朋友可以先看看. 就我的使用经验来说,大部分情况都是处于数 ...