hadoop分布式环境安装
1. 下载hadoop和jdk安装包到指定目录,并安装java环境。

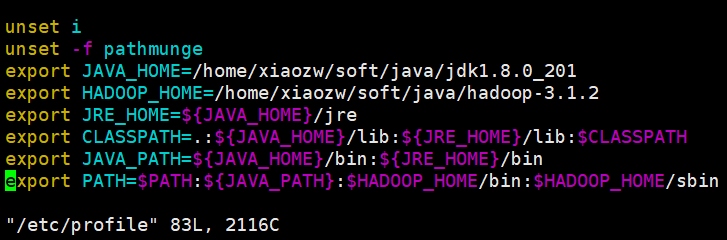
2.解压hadoop到指定目录,配置环境变量。vim /etc/profile
export JAVA_HOME=/home/xiaozw/soft/java/jdk1.8.0_201
export HADOOP_HOME=/home/xiaozw/soft/java/hadoop-3.1.2
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3. 复制配置文件到新文件夹,备份用。
cp -r hadoop hadoop_cluster
重命名配置文件。
mv hadoop hadoop_bak
创建软链接
ln -s hadoop hadoop_cluster

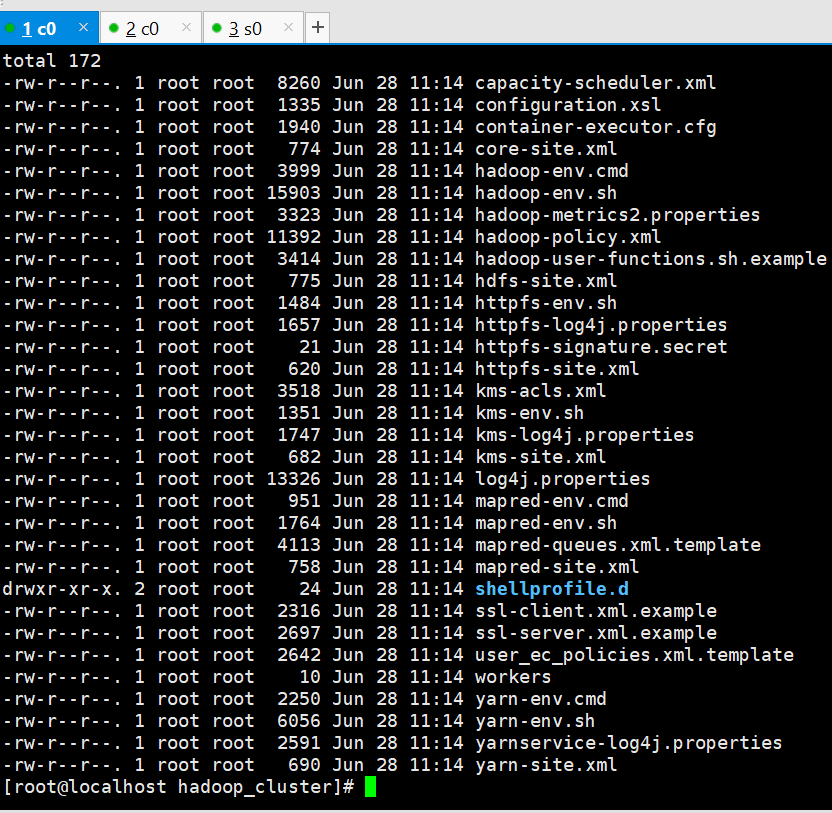
修改配置文件,路径:soft/java/hadoop-3.1.2/etc/hadoop_cluster/
分别修改
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://c0:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xiaozw/soft/tmp/hadoop-${user.name}</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>c3:9868</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.recourcemanager.hostname</name>
<value>c3</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
修改hadoop_cluster/hadoop-env.sh
export JAVA_HOME=/home/xiaozw/soft/java/jdk1.8.0_201

4. 克隆多台机器。修改hostname
分别修改每台机器。
vim /etc/hostname
c0
每台机器都一样配置。
vim /etc/hosts
192.168.132.143 c0
192.168.132.144 c1
192.168.132.145 c2
192.168.132.146 c3
4台服务器需要ssh免密码登录。
设置2台服务器为data-node。进入配置文件目录:
cd soft/java/hadoop-3.1.2/etc/hadoop_cluster/
sudo vim workers
新建脚本方便拷贝文件到多台服务器上面。
bat.sh
for((i=1;i<=3;i++))
{
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hadoop-env.sh xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hadoop-env.sh
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hdfs-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/hdfs-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/core-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/core-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/mapred-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/mapred-site.xml
#scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/yarn-site.xml xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/yarn-site.xml
scp /home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/workers xiaozw@c$i:/home/xiaozw/soft/java/hadoop-3.1.2/etc/hadoop_cluster/workers
ssh xiaozw@c$i rm -rf /home/xiaozw/soft/tmp/
#scp /etc/hosts xiaozw@c$i:/etc/hosts
}
新增权限
chmod a+x bat.sh

5. 启动hadoop
start-all.sh
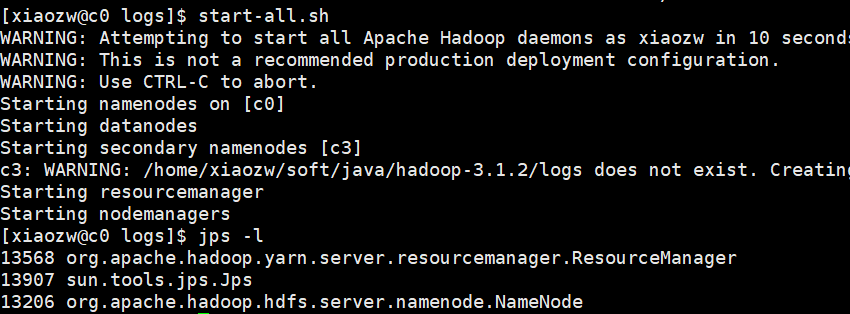
http://192.168.132.143:9870/dfshealth.html#tab-overview
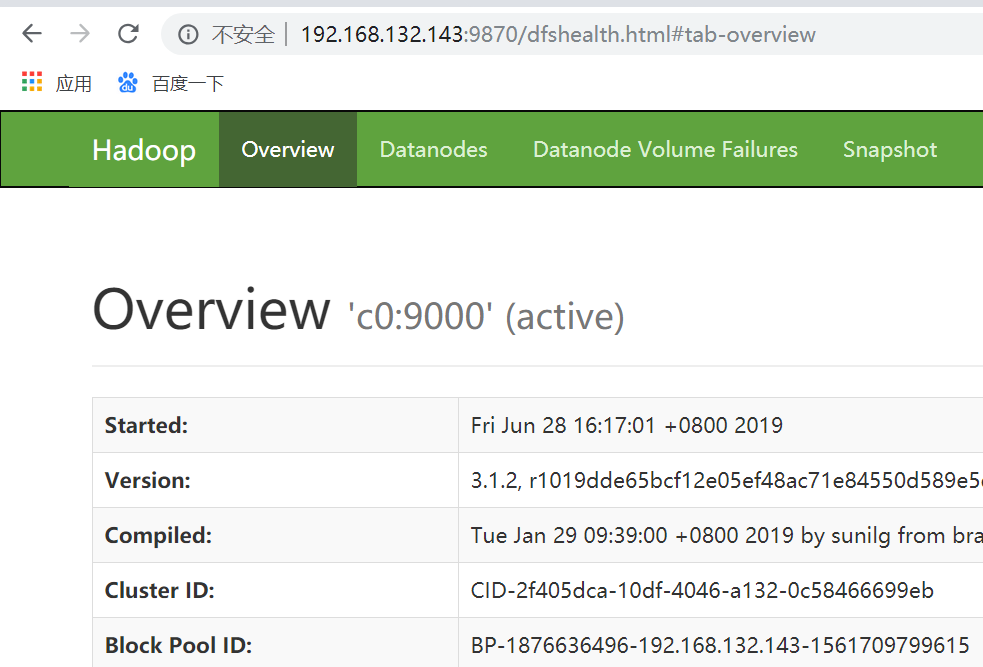
http://192.168.132.143:8088/cluster
统计最高温度demo:
public static void main(String[] args) {
try {
log.info("开始。。。");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// if (otherArgs.length != 2) {
// System.err.println("Usage: wordcount ");
// System.exit(2);
// }
Job job = new Job(conf, "max tempperature");
//运行的jar
//job.setJarByClass(MaxTemperature2.class);
job.setJar("/home/xiaozw/soft/download/demo-0.0.1-SNAPSHOT.jar");
FileSystem fs=FileSystem.get(conf);
//如果输出路径存在,删除。
Path outDir=new Path("/home/xiaozw/soft/hadoop-data/out");
if(fs.exists(outDir)){
fs.delete(outDir,true);
}
Path tmpDir=new Path("/home/xiaozw/soft/tmp");
if(fs.exists(tmpDir)){
fs.delete(tmpDir,true);
}
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReduce.class);
//设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//提交作业并等待它完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
log.info("结束。。。");
}
package com.example.demo; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class TempMapper extends Mapper<Object, Text, Text, IntWritable>{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String lineValue = value.toString();
String year = lineValue.substring(0, 4);
int temperature = Integer.parseInt(lineValue.substring(8));
context.write(new Text(year), new IntWritable(temperature));
}
}
package com.example.demo; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class TempReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxTemp = Integer.MIN_VALUE;
for(IntWritable value : values){
maxTemp = Math.max(maxTemp, value.get());
}
context.write(key, new IntWritable(maxTemp));
}
}
网盘文件和代码下载地址:
链接:https://pan.baidu.com/s/14wdv5CTXzw_0pmDisCa0uA
提取码:auao
hadoop分布式环境安装的更多相关文章
- hadoop 分布式环境安装
centos 多台机器免密登录 hadoop学习笔记(五)--全分布模式下SSH免密码登陆的实现 参考安装教程 Hadoop-2.7.4 集群快速搭建 启动hadoop cd /opt/soft/ha ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- Hadoop 分布式环境slave节点重启忽然不好使了
Hadoop 分布式环境slaves节点重启: 忽然无法启动DataNode和NodeManager处理: 在master节点: vim /etc/hosts: 修改slave 节点的IP (这个时候 ...
- Ubuntu15.10下Hadoop2.6.0伪分布式环境安装配置及Hadoop Streaming的体验
Ubuntu用的是Ubuntu15.10Beta2版本,正式的版本好像要到这个月的22号才发布.参考的资料主要是http://www.powerxing.com/install-hadoop-clus ...
- Hadoop Yarn(一)—— 单机伪分布式环境安装
HamaWhite(QQ:530422429)原创作品,转载请注明出处:http://write.blog.csdn.net/postedit/40556267. 本文是依据Hadoop官网安装教程写 ...
- Hadoop 3.1.3伪分布式环境安装Hive 3.1.2的异常总结
背景:hadoop版本为3.1.3, 且以伪分布式形式安装,hive版本为3.1.2,hive为hadoop的一个客户端. 1. 安装简要步骤 (1) 官网下载apache-hive-3.1.2-bi ...
- [大数据学习研究] 3. hadoop分布式环境搭建
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中 ...
- Hadoop 分布式环境搭建
一.前期环境 安装概览 IP Host Name Software Node 192.168.23.128 ae01 JDK 1.7 NameNode, SecondaryNameNode, Data ...
- Hadoop本地环境安装
一.服务器环境 本人用的是阿里云的ECS的入门机器,配置1核2G,1M带宽,搭了个Hadoop单机环境,供参考 Linux发行版本:Centos7 JDK:阿里云镜像市场中选择JDK8 二.安装步骤 ...
随机推荐
- 日记smarthome
测试命令:测试命令 7e 7e 两个字节 一个字节 两个字节 一个字节 解释: 两个字节是userid的值 int Userid = data[i] * 256 + data[i + 1]; ...
- JAVA总结--java基本语法
static :静态的~ static :静态变量.静态方法: 被修饰的成员变量或者方法独立于该类的任何对象,只要该类被加载,被修饰的成员变量或者方法就存在并可以使用. 用public修饰的stat ...
- 给当当同学的random data
m**o 00'57"32街**o 00'52"23c**6 00'44"15斗**6 00'57"58n**5 00'32"04s**p 00'51 ...
- spark浅谈(2):SPARK核心编程
一.SPARK-CORE 1.spark核心模块是整个项目的基础.提供了分布式的任务分发,调度以及基本的IO功能,Spark使用基础的数据结构,叫做RDD(弹性分布式数据集),是一个逻辑的数据分区的集 ...
- Composer简介与下载安装
简介: 初次接触Composer的PHP程序员可能是需要下载ThinkPHP框架(5.1),那么什么是Composer,怎么下载安装呢? Composer是一个依赖管理工具,下载管理第三方包是其主要功 ...
- 关于print的一点秀操作
我们在玩 Python 的时候 常常会使用到 print 这个函数 主要用它来打印一些输出 这样我们可以更加方便的知道 程序的运行情况 我们常常这样操作 不过不是很骚 有时候我们想更加直观的看到我 ...
- Python实战之网上银行及购物商城
前言:这是初学时写的小项目,觉得有意思就写来玩玩,也当是巩固刚学习的知识.现在看来很不成熟,但还是记录一下做个纪念好了~ 1.名称:网上网上银行及购物商城 2.项目结构: 当时刚接触python啦,哪 ...
- 常见3种Git服务器的构建
学习Git不同的服务器形式,具体如下: - 创建SSH协议服务器 - 创建Git协议服务器 - 创建HTTP协议服务器 方案: Git支持很多服务器协议形式,不同协议的Git服务器,客户端就可以使用不 ...
- CF dp 题(1500-2000难度)
前言 从后往前刷 update 新增 \(\text{\color{red}{Mark}}\) 标记功能,有一定难度的题标记为 \(\text{\color{red}{红}}\) 色. 题单 (刷过的 ...
- php内置函数分析之ucfirst()、lcfirst()
ucfirst($str) 将 str 的首字符(如果首字符是字母)转换为大写字母,并返回这个字符串. 源码位于 ext/standard/string.c /* {{{ php_ucfirst Up ...