R_Studio(癌症)数据连续属性离散化处理
对“癌症.csv”中的肾细胞癌组织内微血管数进行连续属性的等宽离散化处理(分为3类),并用宽值找替原来的值
癌症.csv
setwd('D:\\data')
list.files()
dat=read.csv(file="癌症.csv",header=TRUE)
#等宽离散化
v1=ceiling(dat[,1])
#等频离散化
names(data)='f'#变量重命名
attach(dat)
seq(0,length(f),length(f)/2)#等频划分为6组
v=sort(f)#按大小排序作为离散化依据
v2=rep(0,26)#定义新变量
for(i in 1:26) v2[i]=ifelse(f[i]<=v[13],1,
ifelse(f[i]<=v[26],2))
detach(dat)
#聚类离散化
result=kmeans(dat[,4],2)
v3=result$cluster
#图示结果
plot(dat[,4],v1,xlab='肾细胞癌组织内微血管数',ylab='等宽离散化')
plot(dat[,4],v2,xlab='肾细胞癌组织内微血管数',ylab='等频离散化')
plot(dat[,4],v3,xlab='肾细胞癌组织内微血管数',ylab='聚类离散化')
Gary.R
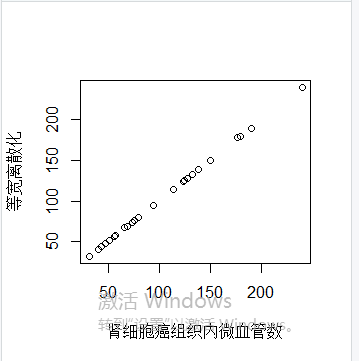
等宽离散化:将连续数据按照等宽区间标准离散化数据
setwd('D:\\data')
list.files()
dat=read.csv(file="癌症.csv",header=TRUE)
#等宽离散化
v1=ceiling(dat[,4])
#图示结果
plot(dat[,4],v1,xlab='肾细胞癌组织内微血管数',ylab="等宽离散化")
等频离散化:将相同数量的数据放进一个区间
setwd('D:\\data')
list.files()
dat=read.csv(file="癌症.csv",header=TRUE)
#等频离散化
names(data)='f'#变量重命名
attach(dat)
seq(0,length(f),length(f)/2)#等频划分为6组
v=sort(f)#按大小排序作为离散化依据
v2=rep(0,26)#定义新变量
for(i in 1:26) v2[i]=ifelse(f[i]<=v[13],1,
ifelse(f[i]<=v[26],2))
#图示结果
plot(dat[,4],v2,xlab='肾细胞癌组织内微血管数',ylab="等频离散化")

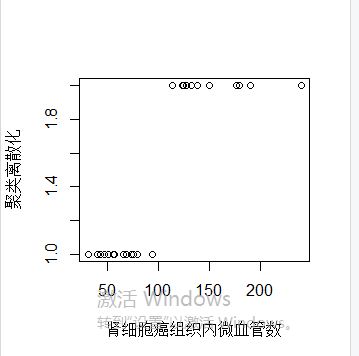
聚类离散化:一维聚类离散包括两个过程:通过聚类算法(K-Means算法)将连续属性值进行聚类,处理聚类之后的到的k个簇,得到每个簇对应的分类值(类似这个簇的标记)
setwd('D:\\data')
list.files()
dat=read.csv(file="癌症.csv",header=TRUE)
#聚类离散化
result=kmeans(dat[,4],2)
v3=result$cluster
#图示结果
plot(dat[,4],v3,xlab='肾细胞癌组织内微血管数',ylab='聚类离散化')
R_Studio(癌症)数据连续属性离散化处理的更多相关文章
- 数据处理:2.异常值处理 & 数据归一化 & 数据连续属性离散化
1.异常值分析 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 异常值分析 → 3σ原则 / 箱型图分析异常值处理方法 → 删除 / 修正填补 ...
- R_Studio(癌症)以等宽类别值、自定义类别值、等频类别值(分为5类)
对“癌症.csv”中的肾细胞癌组织内微血管数进行连续属性的离散化处理 增加“微血管数分类1”属性,取值为等宽类别值(分为5类),增加“微血管数分类2”属性,取值为自定义类别值(0~40,41~60,6 ...
- python数据分析数据标准化及离散化详解
python数据分析数据标准化及离散化详解 本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0 ...
- 多个PVSS数据点属性读写的优化处理
注:本译文出自15多年前,尚未用最新软硬件平台进行重新测试,只提供方法论层面的参考,具体性能指标不具备参考意义. 多个PVSS数据点属性读写的优化处理 本文档概述了测试三种读取和写入多个PVSS数据点 ...
- EF CodeFirst系列(4)--- 数据注释属性
EFCodeFirst模式使用的是约定大于配置的编程模式,这种模式利用默认约定根据我们的领域模型建立概念模型.然后我们也可以通过配置领域类来覆盖默认约定. 覆盖默认约定主要用两种手段: 1.数据注释属 ...
- 在Delphi中调用"数据链接属性"对话框设置ConnectionString
项目需要使用"数据链接属性"对话框来设置ConnectionString,查阅了一些资料,解决办法如下: 1.Delphi 在Delphi中比较简单,步骤如下: 方法1: use ...
- Page5:状态转移矩阵及性质、连续线性系统离散化及其性质[Linear System Theory]
内容包含脉冲响应矩阵和传递函数矩阵之间的关系,状态转移矩阵及性质,以及线性连续系统离散化及其性质
- Angular4.x 创建组件|绑定数据|绑定属性|数据循环|条件判断|事件|表单处理|双向数据绑定
Angular4.x 创建组件|绑定数据|绑定属性|数据循环|条件判断|事件|表单处理|双向数据绑定 创建 angular 组件 https://github.com/angular/angular- ...
- R_Studio(学生成绩)对数据进行属性构造处理
对“Gary.csv”中数据进行进行属性构造处理,增加“总成绩”属性 Gary.csv setwd('D:\\data') list.files() #数据读取 dat=read.csv(file=& ...
随机推荐
- C++练习 | 类的继承与派生练习(1)
#include <iostream> #include <cmath> #include <cstring> #include <string> #i ...
- C# 面向对象6 之前的复习
复习练习 THIS:调用当前类的构造函数
- Spark运行时的内核架构以及架构思考
一: Spark内核架构 1,Drive是运行程序的时候有main方法,并且会创建SparkContext对象,是程序运行调度的中心,向Master注册程序,然后Master分配资源. 应用程序: A ...
- 2019-2020-1 20199319《Linux内核原理与分析》第六周作业
系统调用的三层机制(下) 给MenuOS增加命令 首先进入LinuxKernel文件夹,删除menu目录,然后git clone克隆一个新版本的menu,新版本的menu中已经添加了time和time ...
- filebeat收集nginx的json格式日志
一.在nginx主机上安装filebeat组件 [root@zabbix_server nginx]# cd /usr/local/src/ [root@zabbix_server src]# wge ...
- 自动化运维——MySQL备份脚本(二)
使用if语句编写MySQL备份脚本 代码: #!/bin/bash #auro backup mysql db #by steve yu #define backup path BAK_DIR=/da ...
- javascript模板字符串(标签函数)
前面介绍了javascript的模板字符串的基本知识,今天深入学习一下标签函数 模板字符串概述 这里先简单说一下模板字符串的概念 1.模板字符串,从名字上可以得出其实返回的是字符串,普通使用其实就想引 ...
- pytest重复执行
安装 pip install pytest-repeat 命令: pytest --count=10 test_file.py
- 关于ORACLE的串行化隔离级别--来自ORACLE概念手册
为了描述同时执行的多个事务如何实现数据一致性,数据库研究人员定义了被 称为串行化处理(serializability)的事务隔离模型(transaction isolation model).当所有 ...
- echarts-all.js:1 Uncaught TypeError: Cannot read property 'getAttribute' of null
转载:https://blog.csdn.net/you23hai45/article/details/51595108 由于echarts图形ID是由后台传输过来的,并且是根据图形数据一起传过来,出 ...