xpath定位不到原因浅析
在爬虫中,我们经常使用xpath来对元素进行定位,xpath定位分为两种,一种是绝对定位,/html/body/div[2]/div[1]/div/div[3]/a[7],另外一种是相对定位,比如r'//*[@id ='ul' ]/a[7]'
通常我们可以通过开发者工具,复制元素对应的xpath,这种xpath都是绝对定位,方便获取,但是绝对路径太长,如果里面元素被隐藏了或者元素有变动的话,绝对定位就会出错,就会出现定位不到的情况。这个时候用相对定位可以解决这个问题,相对定位更精准,相对定位通常可以和id或者class-name结合使用。
方法,我们可以将我们写的xpath 放到开发者工具里,看是不是能定位到,如果能定位到,说明不是xpath定位的问题。
还有的情况是页面几个元素的xpah一模一样,这个我们可以用下标解决,举例
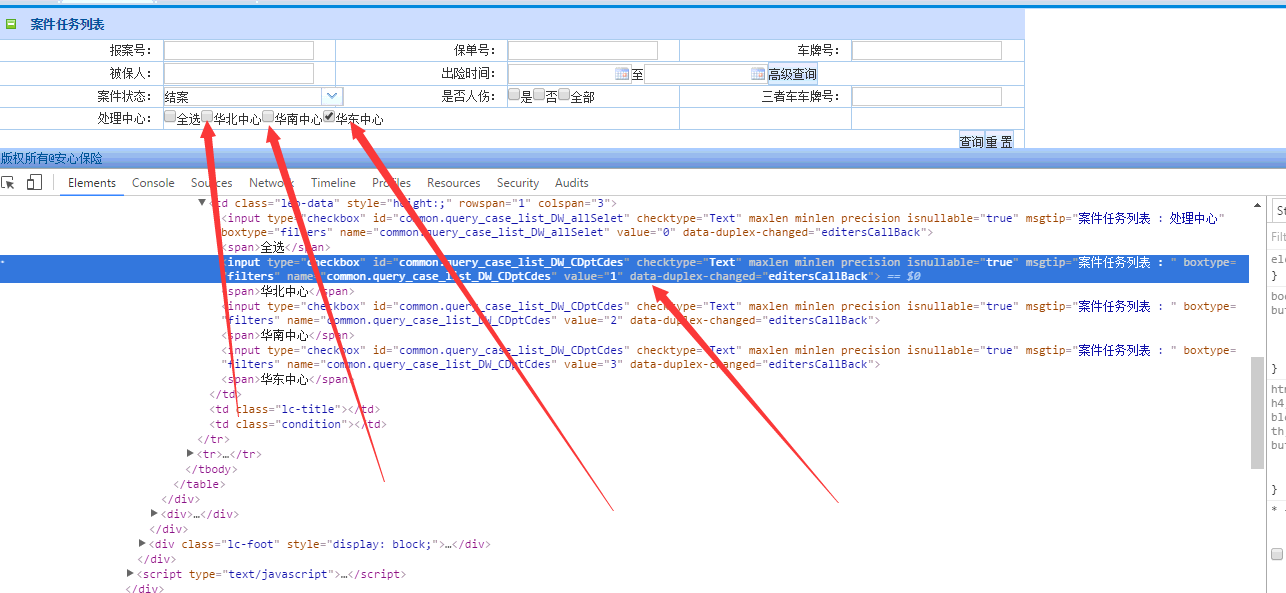 现在我们要抓取的是华东地区这个标签,但是问题是华北中心,华南中心,华东中心的三个标签的xpah是一样的。都是//*[@id="common.query_case_list_DW_CDptCdes"] 。这个时候我们选择华东中心,可以通过下标定位,既是
现在我们要抓取的是华东地区这个标签,但是问题是华北中心,华南中心,华东中心的三个标签的xpah是一样的。都是//*[@id="common.query_case_list_DW_CDptCdes"] 。这个时候我们选择华东中心,可以通过下标定位,既是
//*[@id="common.query_case_list_DW_CDptCdes"][3] 这样就可以了。
另外看标签是否选中,还有一个小知识点,就是 is_selected(),如果返回true 则表名被选中,如果返回false ,则表名未被选中
browser.find_element_by_xpath('//*[@id="report.report_loss_type_DW_HasGds"]').is_selected()
下面的是一位大神总结的:
什么是xpath呢?
官方介绍:XPath即为XML路径语言,它是一种用来确定XML1(标准通用标记语言3的子集)文档中某部分位置的语言。反正小编看这个介绍是云里雾里的,通俗一点讲就是通过元素的路径来查找到这个元素的,相当于通过定位一个对象的坐标,来找到这个对象。
一、xpath:属性定位
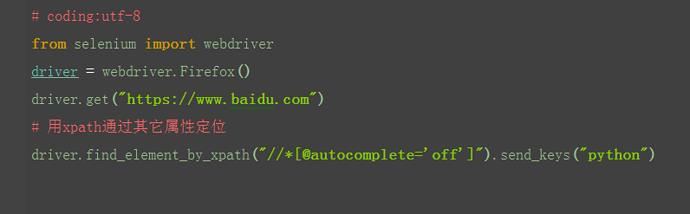
- xptah也可以通过元素的id、name、class这些属性定位,如下图

2.于是可以用以下xpath方法定位

二、xpath:其它属性
1.如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
三、xpath:标签
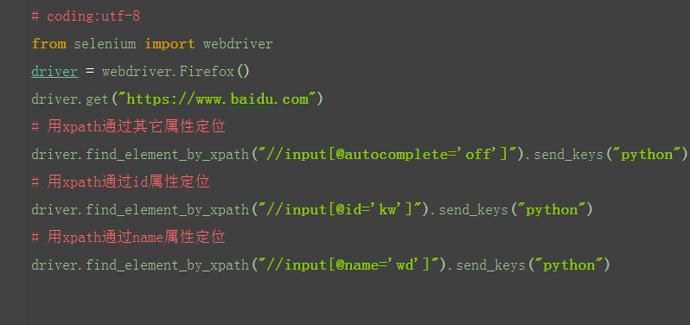
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
2.如果不想制定标签名称,可以用*号表示任意标签
3.如果想制定具体某个标签,就可以直接写标签名称
四、xpath:层级
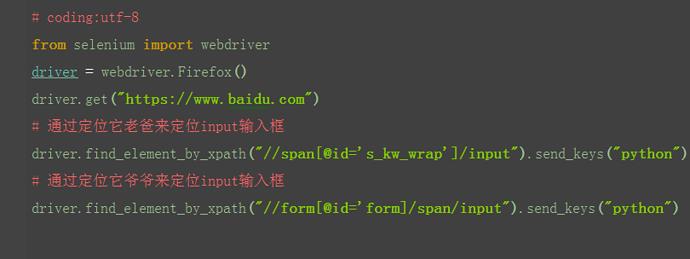
1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)
2.找到它老爸后,再找下个层级就能定位到了

3.如上图所示,要定位的是input这个标签,它的老爸的id=s_kw_wrap.
4.要是它老爸的属性也不是很明显,就找它爷爷id=form
5.于是就可以通过层级关系定位到
五、xpath:索引
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图三胞胎兄弟

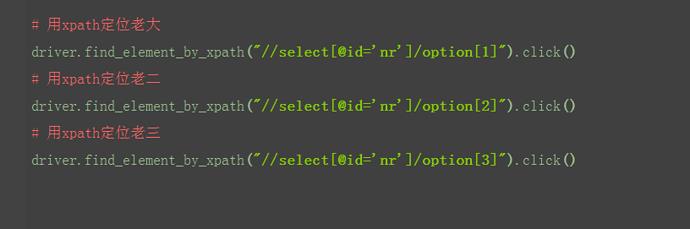
4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)
六、xpath:逻辑运算
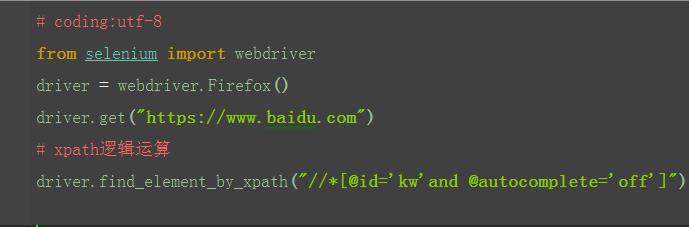
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性
七、xpath:模糊匹配
1.xpath还有一个非常强大的功能,模糊匹配
2.掌握了模糊匹配功能,基本上没有定位不到的
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。

可以把xpath看成是元素定位界的屠龙刀。武林至尊,宝刀xpath,css不出,谁与争锋?下节课将亮出倚天剑css定位。
原文链接https://www.cnblogs.com/wanghaihong200/p/8461770.html
xpath定位不到原因浅析的更多相关文章
- Selenium-Python学习——通过XPath定位元素
用Xpath定位元素的方法总是记不住,经常要翻出各种文档链接参考,干脆把需要用到的内容整到这个笔记中方便查找. Xpath是在XML文档中定位节点的语言.使用 XPath 的主要原因之一是当想要查找的 ...
- 元素定位-XPATH定位方法总结
1.Xpath定位方法探讨 xpath是比较常用的一种定位元素的方式,因为它很方便,缺点是,消耗系统性能.如果Xpath使用的比较好,几乎可以定位到任何页面元素,而且受页面变化影响较小. 1.1.什么 ...
- 【转载】Xpath定位方法深入探讨及元素定位失败常见情况
一.Xpath定位方法深入探讨 (1)常用的Xpath定位方法及其特点 使用绝对路径定位元素. 例如: driver.findElement(By.xpath("/html/body/div ...
- Xpath定位方法深入探讨及元素定位失败常见情况
一.Xpath定位方法深入探讨 (1)常用的Xpath定位方法及其特点 使用绝对路径定位元素. 例如: driver.findElement(By.xpath("/html/body/div ...
- python+selenium基础之XPATH定位(第一篇)
世界上最远的距离大概就是明明看到一个页面元素矗在那里,但是我却定位不到!! selenium定位元素的方法有很多种,像是通过id.name.class_name.tag_name.link_text等 ...
- appium 3-4-1034等待、日志、性能数据、xpath定位、web driver协议
1.等待 1.1精确等待 sleep 不推荐 @Test public void testWait1() throws InterruptedException{ day_time(); Thread ...
- 关于Xpath定位方法知道这些基本够用
一.写在前面 之前写过一些关于元素定位的文章,但是感觉都是很碎片,现在想做个整合,便有了这篇文章. 二.xpath的定位方法 关于xpath定位方法,网上写的已经很成熟了,现已百度首页为例,如下图: ...
- java selenium (六) XPath 定位
xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. 阅读目录 什么是xpath xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面, ...
- 常用的CSS定位,XPath定位和JPath定位
CSS定位 举例 描述 div#menu id为menu的div元素 div.action-btn.ok-btn class为action-btn和ok-btn的div元素 table#emailLi ...
随机推荐
- Trailing Zeroes (III) LightOJ - 1138 不找规律-理智推断-二分
其实有几个尾零代表10的几次方但是10=2*510^n=2^n*5^n2增长的远比5快,所以只用考虑N!中有几个5就行了 代码看别人的: https://blog.csdn.net/qq_422797 ...
- Mac--PHP已经开启gd扩展验证码不显示
错误显示:Call to undefined function imagettftext() 原因: mac系统中自带的php的gd库中,缺少对freetype的支持,导致图片无法显示. 解决: 1 ...
- SVG.JS 画弧线
需求描述: 使用svg.js,绘制一个弧线.下图绿色弧线. 准备工作: 1.了解SVG Path中的A指令 详细文档,请戳这里 给定x半径.y半径后,经过指定的两点,可以有2个椭圆,因此两点间有2条弧 ...
- JDK 13 的 12 个新特性,真心涨姿势了
作者:木九天 my.oschina.net/mdxlcj/blog/3107021 1.switch优化更新 JDK11以及之前的版本: switch (day) { case MONDAY: cas ...
- OSI模型——传输层
OSI模型——传输层 运输层 运输层概述 运输层提供应用层端到端通信服务,通俗的讲,两个主机通讯,也就是应用层上的进程之间的通信,也就是转换为进程和进程之间的通信了,我们之前学到网络层,IP协议能将分 ...
- LED音乐频谱之点阵
转载请注明出处:http://blog.csdn.net/ruoyunliufeng/article/details/37967455 一.硬件 watermark/2/text/aHR0cDovL2 ...
- asp.net 获取表单中控件的值
原文:https://blog.csdn.net/happymagic/article/details/8480235 C# 后台获取前台 input 文本框值.(都是以控件的Name来获取) s ...
- .linux基础命令三
一. 两台服务器免密登录: 1. 生成密钥 ssh-keygen的命令手册,通过”man ssh-keygen“命令查看指令: 通过命令”ssh-keygen -t rsa“创建一对密匙,包括公匙和私 ...
- iOS开发-retain/assign/strong/weak/copy/mutablecopy/autorelease区别
依旧本着尊重原创和劳动者的原则,将地址先贴在前面: http://www.cnblogs.com/nonato/archive/2013/11/28/3447162.html,作者Nonato 以下内 ...
- noscript
<noscript> <article id="noscript" class="error info_panel"> <head ...