常见数据挖掘算法的Map-Reduce策略(2)
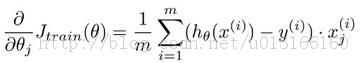 ,每一次迭代的个过程可以转换成一个map-reduce过程,按行或者按列拆分数据,分配到N各节点上,每个节点再通过计算,最后,输出到reduce,进行合并更新W权重系数,完成一次迭代过程。下图文献1中也提到LR的并行,不过用的优化方法是
,每一次迭代的个过程可以转换成一个map-reduce过程,按行或者按列拆分数据,分配到N各节点上,每个节点再通过计算,最后,输出到reduce,进行合并更新W权重系数,完成一次迭代过程。下图文献1中也提到LR的并行,不过用的优化方法是


class MRsvm(MRJob):
DEFAULT_INPUT_PROTOCOL = 'json_value'
#一些参数的设置
def __init__(self, *args, **kwargs):
super(MRsvm, self).__init__(*args, **kwargs)
self.data = pickle.load(open('data_path'))
self.w = 0
self.eta = 0.69 #学习率
self.dataList = [] #用于收集样本的列表
self.k = self.options.batchsize
self.numMappers = 1
self.t = 1 # 迭代次数
def map(self, mapperId, inVals):
#<key,value> 对应着 <机器mapperID,W值或者样本特征跟标签>
if False: yield
#判断value是属于W还是样本ID
if inVals[0]=='w':
self.w = inVals[1]
elif inVals[0]=='x':
self.dataList.append(inVals[1])
elif inVals[0]=='t': self.t = inVals[1]
def map_fin(self):
labels = self.data[:,-1]; X=self.data[:,0:-1]#解析样本数据
if self.w == 0: self.w = [0.001]*shape(X)[1] #初始化W
for index in self.dataList:
p = mat(self.w)*X[index,:].T #分类该样本
if labels[index]*p < 1.0:
yield (1, ['u', index])#这是错分样本id,记录该样本的id
yield (1, ['w', self.w]) #map输出该worker的w
yield (1, ['t', self.t])
def reduce(self, _, packedVals):
for valArr in packedVals: #解析数据,错分样本ID,W,迭代次数
if valArr[0]=='u': self.dataList.append(valArr[1])
elif valArr[0]=='w': self.w = valArr[1]
elif valArr[0]=='t': self.t = valArr[1]
labels = self.data[:,-1]; X=self.data[:,0:-1]
wMat = mat(self.w); wDelta = mat(zeros(len(self.w)))
for index in self.dataList:
wDelta += float(labels[index])*X[index,:] #更新W
eta = 1.0/(2.0*self.t) #更新学习速率
#累加对W的更新
wMat = (1.0 - 1.0/self.t)*wMat + (eta/self.k)*wDelta
for mapperNum in range(1,self.numMappers+1):
yield (mapperNum, ['w', wMat.tolist()[0] ])
if self.t < self.options.iterations:
yield (mapperNum, ['t', self.t+1])
for j in range(self.k/self.numMappers):
yield (mapperNum, ['x', random.randint(shape(self.data)[0]) ])
def steps(self):
return ([self.mr(mapper=self.map, reducer=self.reduce,
mapper_final=self.map_fin)]*self.options.iterations)
2,《Map-Reduce for Machine Learning on Multicore NG的一篇nips文章》
4,http://www.csdn.net/article/2014-02-13/2818400-2014-02-13
常见数据挖掘算法的Map-Reduce策略(2)的更多相关文章
- 常见数据挖掘算法的Map-Reduce策略(1)
大数据这个名词是被炒得越来越火了,各种大数据技术层出不穷,做数据挖掘的也跟着火了一把,呵呵,现今机器学习算法常见的并行实现方式:MPI,Map-Reduce计算框架,GPU方面,grap ...
- MapReduce 支持的部分数据挖掘算法
MapReduce 支持的部分数据挖掘算法 MapReduce 能够解决的问题有一个共同特点:任务可以被分解为多个子问题,且这些子问题相对独立,彼此之间不会有牵制,待并行处理完这些子问题后,任务便被解 ...
- 分布式基础学习(2)分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分 布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件 系统,很 ...
- 分布式基础学习【二】 —— 分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件系统,很大程 ...
- 图解kubernetes scheduler基于map/reduce无锁设计的优选计算
优选阶段通过分离计算对象来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用了随机的方式来 ...
- 图解kubernetes scheduler基于map/reduce模式实现优选阶段
优选阶段通过分map/reduce模式来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用 ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
随机推荐
- Unity里面的自动寻路(二)
接着我的 上一篇自动寻路文章,这一次我们就来学习一下与自动寻路有关的组件吧.Unity中与自动寻路相关的组件主要有两个:NavMeshAgent ( 又称导航网格代理 ),Off Mesh Link ...
- 类的成员函数指针和mem_fun适配器的用法
先来看一个最简单的函数: void foo(int a) { cout << a << endl; } 它的函数指针类型为 void (*)(int); 我们可以这样使用: v ...
- List装form
List<MemberPrivilegeForm> formlist = new ArrayList<MemberPrivilegeForm>(); int status = ...
- Linux——vi命令的使用
vi的基本操作 a) 进入vi 在系统提示符号输入vi及文件名称后,就进入vi全屏幕编辑画面: $ vi myfile 不过有一点要特别注意,就是您进入vi之后,是处于「命令行模式(command m ...
- 【HTML5】元素<head>的使用
功能描述 在新建的页面<head>元素中,加入该元素所包含的各类标签,并定义超级链接的样式.当单击"请点击我"标签时,并展示相应效果并进入<base>元素设 ...
- JDBC编程理论知识(1)
1.SUN公司为统一对数据库的操作,定义了一套Java操作数据库的规范,称之为JDBC 2.JDBC全称为:Java Data Base Connectivity(java数据库连接),它主要由接口组 ...
- MVC| Razor 布局-模板页 | ViewStart.cshtml
来自:http://blog.csdn.net/fanbin168/article/details/49725175 这个图就看明白了 _ViewStart.cshtml 视图文件的作用 _View ...
- 微信公众号开发之创建菜单栏代码示例(php)
思路很简单:就是先获取access_token,然后带着一定规则的json数据参数请求创建菜单的接口.废话不多讲,直接上代码. class Wechat { public $APPID="w ...
- SVN 创建仓库操作
服务端安装完成后 1.创建一个存放仓库的文件夹(这里在home目录创建) #mkdir svnRepo #cd svnRepo/ 创建一个仓库 (写全路径) # svnadmin create /ro ...
- CoreAnimation的使用小结
參考:http://www.cnblogs.com/wendingding/p/3801157.htmlhttp://www.cnblogs.com/wendingding/p/3802830.htm ...