最近学习微信小程序,做一个类似“书库”的小demo,大致流程使用摄像头获取书本后面的isbn,通过豆瓣读书API得到书本介绍、豆瓣评分、图书评论等信息,然鹅https://api.douban.com/v2/book/isbn/:name停服了!

在网上找了一圈,有意思了,ISBN——国际标准书号(International Standard Book Number)这种理论上应该公开的信息却没有相关资源!
号称中国ISBN中心 - 中国版本图书馆,这个网站翻了一遍也没有能够查isbn的地方,不可思议!
然后,鹅厂是这样的:

福厂是这样的:
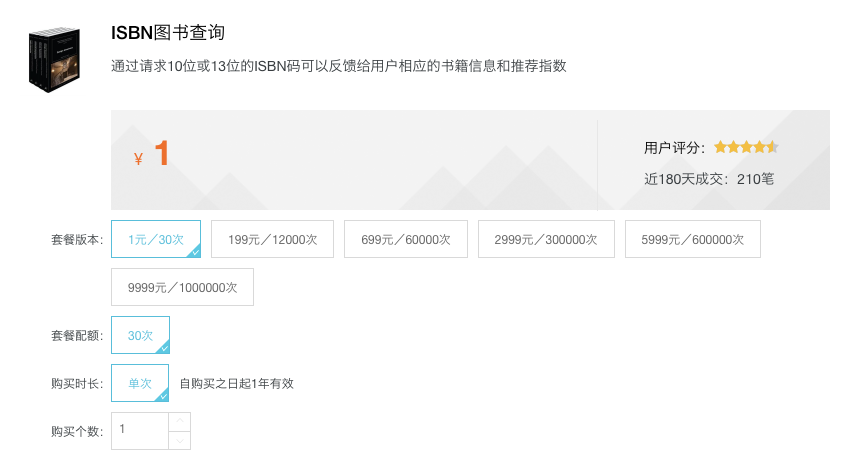
其他厂是这样的:

评论看起来也不太靠谱!图书库信息缺失严重,接口调用失败,调用次数计费不清。。。

豆瓣图书API不在的日子,想ta!
豆瓣提供图书查询API的时候,一个接口就可以查询到书本基本信息、用户评分、用户评论等,豆瓣评分很大程度上描述了一本书受欢迎的程度。但是,近年大家的代码学习也有很多直接调用豆瓣API,我也是,基于豆瓣数据出现了很多商业app,最近比较火的多抓鱼图书评分等数据的来源应该是豆瓣。所以,豆瓣可能也是基于这些原因关闭了图书isbn查询接口。豆瓣关闭图书查询接口后,各个与数据相关的厂商也趁机出来圈钱,质量良莠不齐,豆瓣图书API不在的日子,想ta!
自己造!
ISBN图书查询
调用地址:https://isbn.qiaohaoforever.cn/ISBN
请求方式:GET
返回类型:JSON
请求示例:https://isbn.qiaohaoforever.cn/9787506380263
请求参数(Query)
| 名称 |
类型 |
是否必须 |
描述 |
| ISBN |
STRING |
必选 |
10-13位ISBN码 |
返回参数
| 首级标签 |
名称 |
类型 |
示例值 |
描述 |
|
create_time |
|
1557302752213 |
初次查询时间戳 |
| comments |
rate |
string |
5 |
单个豆瓣用户评分 |
| comments |
user |
string |
小莉啊 |
豆瓣用户昵称 |
| comments |
img |
string |
https://img1.doubanio.com/icon/u47055426-37.jpg |
豆瓣用户头像 |
| comments |
date |
string |
2016-09-27 |
评论发布时间 |
| comments |
content |
string |
太宰治唯恐一生过得不失格 |
评论内容 |
| tags |
title |
string |
日本文学 |
标签
- 还有这种书,程序开发心理学(豆瓣) - 豆瓣读书,转载自:https://book.douban.com/subject/1141154/
登录/注册 下载豆瓣客户端 豆瓣 读书 电影 音乐 同城 小组 阅读 FM 时间 豆品 更多 豆瓣读书 购书单 电子图书 豆瓣书店 2018年度榜单 2018书影音报告 购物车 程序开发心理学 作 ...
- 使用po模式读取豆瓣读书最受关注的书籍,取出标题、评分、评论、题材 按评分从小到大排序并输出到txt文件中
#coding=utf-8from time import sleepimport unittestfrom selenium import webdriverfrom selenium.webdri ...
- 用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评 方法一: #coding=utf-8 ...
- 豆瓣读书爬虫(requests + re)
前面整理了一些爬虫的内容,今天写一个小小的栗子,内容不深,大佬请忽略.内容包括对豆瓣读书网站中的书籍的基本信息进行爬取,并整理,便于我们快速了解每本书的中心. 一.爬取信息 每当爬取某个网页的信息时, ...
- urllib2模块初体验———豆瓣读书页面下载小爬虫
我也是根据:http://blog.csdn.net/pleasecallmewhy/article/details/8927832 ,来写出豆瓣读书的爬虫,废话不说直接上代码: #!/usr/bin ...
- 【Python爬虫】听说你又闹书荒了?豆瓣读书9.0分书籍陪你过五一
说明 五一将至,又到了学习的季节.目前流行的各大书单主打的都是豆瓣8.0评分书籍,却很少有人来聊聊这9.0评分的书籍长什么样子.刚好最近学了学python爬虫,那就拿豆瓣读书来练练手. 爬虫 本来思路 ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- 豆瓣读书top250数据爬取与可视化
爬虫–scrapy 题目:根据豆瓣读书top250,根据出版社对书籍数量分类,绘制饼图 搭建环境 import scrapy import numpy as np import pandas as p ...
- java 语言实现豆瓣电影信息查询
豆瓣上面有很多电影,有时候要查看个电影信息,去豆瓣搜下还是很方便的,但是如何通过接口的形式来查看豆瓣电影,这对于很多网站.app其实是非常实用的功能,这里笔者附上一个java实现的豆瓣电影信息获取的代 ...
随机推荐
- $O(k^2)$ 求前缀 $k$ 次幂和(与长度无关)
接下来求解前缀幂次和 求解 \(\sum_{i = 1}^{k} i^k\) \[ \begin{aligned} (p+1)^k - 1 = (p+1)^k - p^k + p^k - (p-1)^ ...
- 微信小程序入门笔记
目录的作用: 1. pages目录: 该目录下存放所有的定义页面 2. utils目录: 该目录下存放定义的一些小功能组件 3. 根目录下app.js文件: 定义小程序对象, 执行小程序生命周期内的各 ...
- [LeetCode] 281. Zigzag Iterator 之字形迭代器
Given two 1d vectors, implement an iterator to return their elements alternately. Example: Input: v1 ...
- [LeetCode] 48. Rotate Image 旋转图像
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise). ...
- pgsql 的函数
因为pgsql中没有存储过程和包,所以类似功能通过函数来实现 PostgreSQL的存储过程简单入门 http://blog.csdn.net/rachel_luo/article/details/8 ...
- 【idea】【mysql】idea连接mysql
- linux开启tcp_timestamps和tcp_tw_recycle引发的问题研究
环境:centos7.4 内核版本3.10 最近看内核参数tcp_tw_recycle(该参数在内核 4.12 之后被移除),它用于快速回收处理TIME_WAIT状态的socket.搜索该参数相关的资 ...
- maven基本知识的7个提问
在如今的互联网项目开发当中,特别是Java领域,Maven的仓库管理.依赖管理.继承和聚合等特性为项目的构建提供了一整套完善的解决方案. 这里我们通过7个关于Maven的提问来了解Maven的一些基本 ...
- Java中List集合去除重复数据的六种方法
1. 循环list中的所有元素然后删除重复 public static List removeDuplicate(List list) { for ( int i = 0 ; i < list. ...
- 使用jedis操作redis常用方法
在redis入门及在商城案例中的使用中简单介绍了下使用jedis如何操作redis,但是其实方法是跟redis的操作大部分是相对应的.我这里做下记录 1.String类型操作 public class ...
|
{kind=link}