python系列:一、Urllib库的基本使用
开篇介绍:
因为我本人也是初学者,爬虫的例子大部分都是学习资料上面来的,只是自己手敲了一遍,同时加上自己的理解。
写得不好请多谅解,如果有错误之处请多赐教。
我本人的开发环境是vscode,pythong为3.6版本。
准备好了吗?我们从例子开始吧。
1、扒一个网页下来

是的,你没有看错,上面的代码就能爬百度首页,核心代码就一句:urllib.request.urlopen('http://www.baidu.com')
2.分析扒网页的方法
我们重点来看看这行代码:urllib.request.urlopen("http://www.baidu.com").
调用的是urllib库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议,urlopen一般接受三个参数,它的参数如下:urlopen(url, data, timeout)
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
第二行代码:f.read()。response对象有一个read方法,可以返回获取到的网页内容。
3、POST和GET数据传送
上面的程序演示了最基本的网页抓取,不过,现在大多数网站都是动态网页,需要你动态地传递参数给它,它做出对应的响应。所以,在访问时,我们需要传递数据给它。
数据传送分为POST和GET两种方式,两种方式有什么区别呢?
最重要的区别是GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
POST方式:
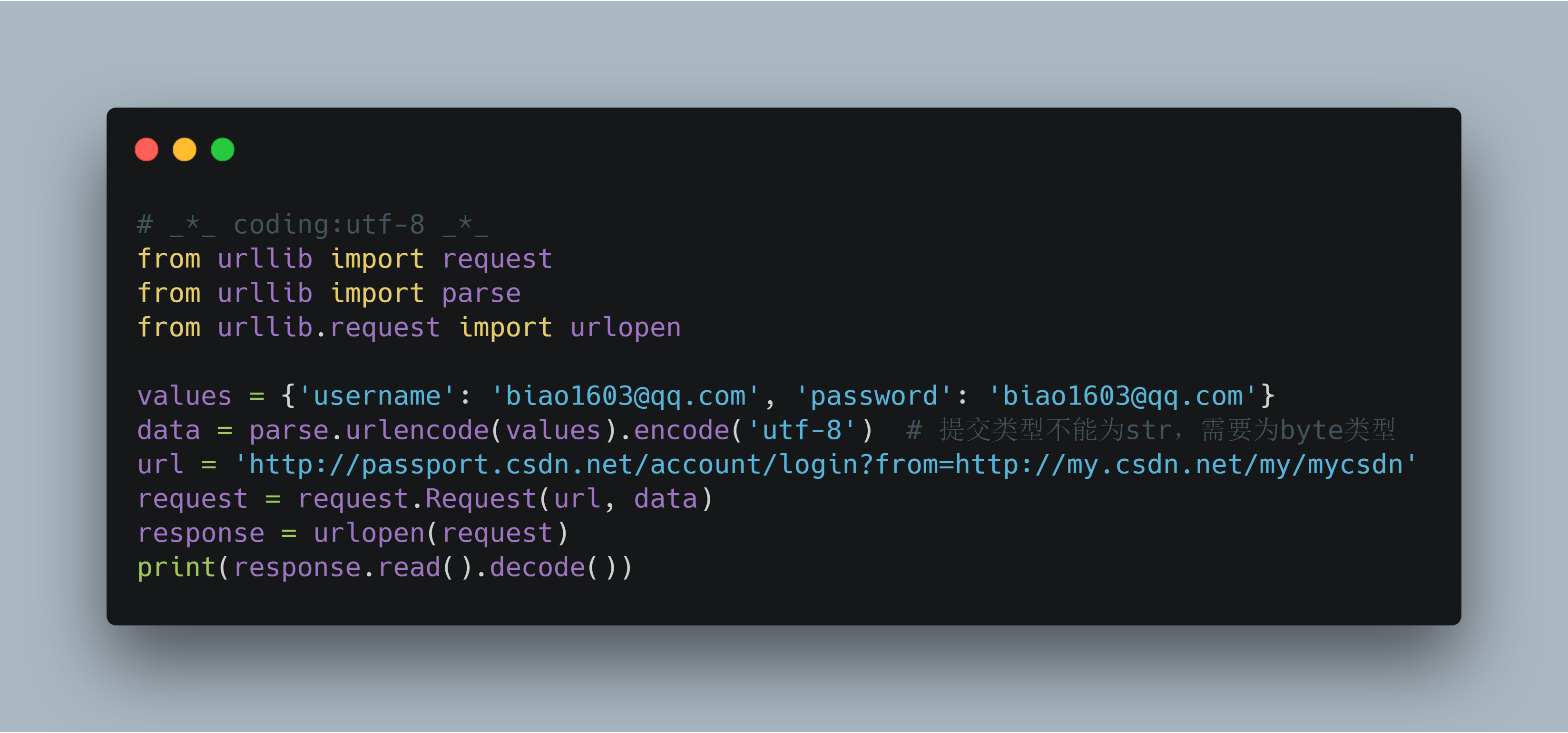
友情提示:如果报错urllib.error.HTTPError: HTTP Error 405: 原因:请求协议问题 解决:将http 改成https试试。
里面的json也可以写成:
values = {}
GET方式:
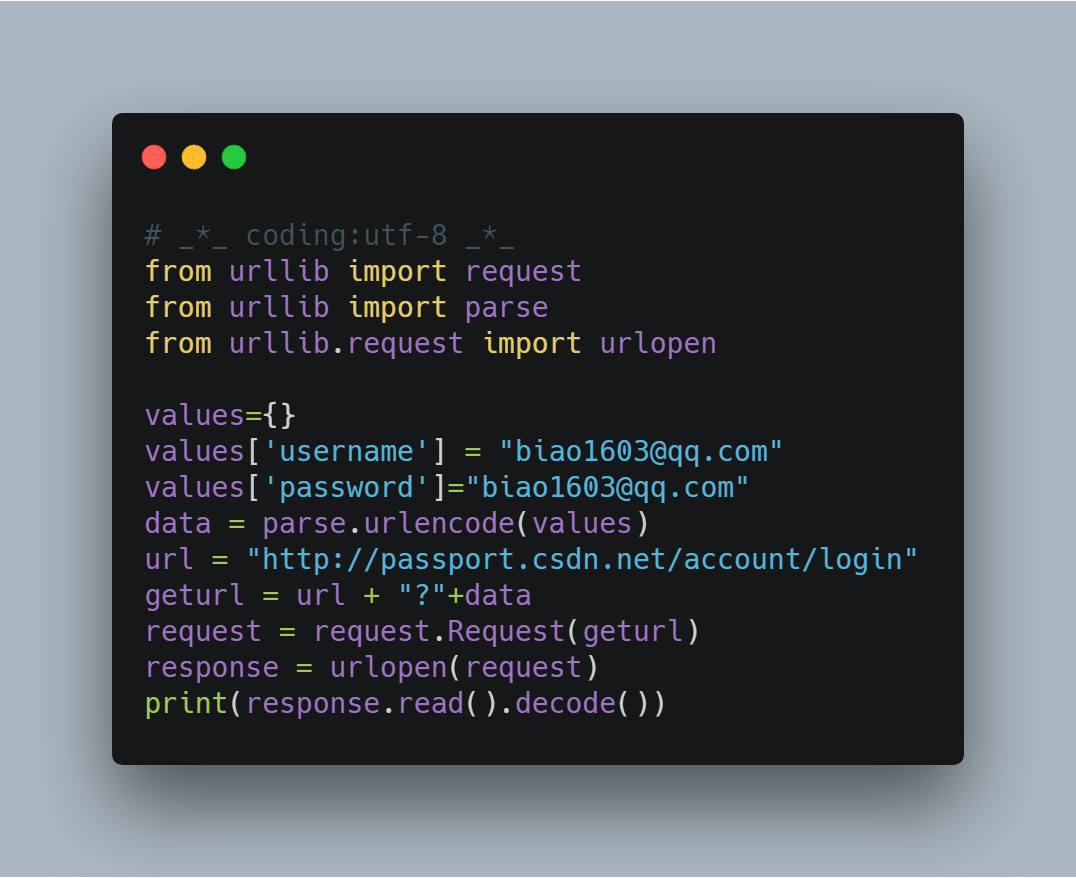
本章讲解了一些基本使用,可以抓取到一些基本的网页信息。
源码如下:
# _*_ coding:utf-8 _*_
import urllib.request def run_demo():
f=urllib.request.urlopen('http://www.baidu.com')
print(f.read()) if __name__=='__main__':
run_demo() '''
# _*_ coding:utf-8 _*_
from urllib import request
from urllib import parse
from urllib.request import urlopen values = {'username': 'biao1603@qq.com', 'password': 'biao1603@qq.com'}
data = parse.urlencode(values).encode('utf-8') # 提交类型不能为str,需要为byte类型
url = 'http://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn'
request = request.Request(url, data)
response = urlopen(request)
print(response.read().decode()) # _*_ coding:utf-8 _*_
from urllib import request
from urllib import parse
from urllib.request import urlopen values={}
values['username'] = "biao1603@qq.com"
values['password']="biao1603@qq.com"
data = parse.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = request.Request(geturl)
response = urlopen(request)
print(response.read().decode())
'''
python系列:一、Urllib库的基本使用的更多相关文章
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- python学习笔记——urllib库中的parse
1 urllib.parse urllib 库中包含有如下内容 Package contents error parse request response robotparser 其中urllib.p ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python 爬虫之 urllib库
文章更新于:2020-03-02 注:代码来自老师授课用样例. 一.初识 urllib 库 在 python2.x 版本,urllib 与urllib2 是两个库,在 python3.x 版本,二者合 ...
- python爬虫03 Urllib库
Urllib 这可是 python 内置的库 在 Python 这个内置的 Urllib 库中 有这么 4 个模块 request request模块是我们用的比较多的 就是用它来发起请求 所以我 ...
- Python 爬虫之urllib库的使用
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
- Python爬虫入门 Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
随机推荐
- QT5.12 qtcreate 在Ubuntu14.04
Ubuntu14.04 下出现了 symbol dbus_message_get_allow_interactive_authorization, version LIBDBUS_1_3 not de ...
- WebGL学习笔记(十):雾化
雾化是指距离我们较远的物体看不清晰的情况,比如模拟大雾环境,或者模拟水下环境时会用到. 实现雾化的方式有很多种,我们这里使用的是线性雾化的方式: 线性雾化 线性雾化比较简单,我们算出每个像素点到摄像机 ...
- 【NPDP笔记】第三章 新产品流程
3.1 产品开发,风险与汇报的过程,开发实践和流程提升成功率 管控新产品失败的风险,随着成本增加,风险降低 知识能改改进决策,降低风险,决策框架 识别问题与机会 收集信息 组织记录,组织员工 外部 ...
- 解决SQL语句在Dapper执行超时比Query慢的问题
在语句结尾加上 Add OPTION (RECOMPILE) to the end https://stackoverflow.com/questions/10933366/sp-executesql ...
- CTS/APIO2019 游记
已经记不得是第几天了就按顺序编号好了. 一 久违的到了北京,上次来北京还是在去年CTSC和APIO的时候.回想起来,这一年发生了很多事情啊. 下午是THUPC的试机赛,我和假雪菜.嘿嘿嘿两个神仙队友过 ...
- STL之空间配置器allocator
摘要 C++STL的空间配置器将内存的分配.释放,对象的构造.析构都分开执行,内存分配由alloc::allocate()负责,内存的释放由alloc::deallocate()负责:对象的构造由:: ...
- css3网站响应式写法
css3响应式写法因为media不支持ie9以下的浏览器 所有要加个判断<pre> <!-- 全部通用的 --><link rel="stylesheet&qu ...
- window安装mysql8.0解决大部分客户端无法连接问题登陆问题
https://blog.csdn.net/u013308810/article/details/80114021
- Redis解决“重试次数”场景的实现思路
很多地方都要用到重试次数限制,不然就会被暴力破解.比如登录密码. 下面不是完整代码,只是伪代码,提供一个思路. 第一种(先声明,这样写有个bug) import java.text.MessageFo ...
- Linux下将.Asp Core 部署到 Docker容器中
我们来部署一个简单的例子: 将一个简单的.Aps Core项目部署到Docker容器中并被外网访问 说明: 下面的步骤都是建立在宿主服务器系统已经安装配置过Docker容器,安装Docker相对比较简 ...