spark调优——算子调优
算子调优一:mapPartitions
普通的map算子对RDD中的每一个元素进行操作,而mapPartitions算子对RDD中每一个分区进行操作。如果是普通的map算子,假设一个partition有1万条数据,那么map算子中的function要执行1万次,也就是对每个元素进行操作。
如果是mapPartition算子,由于一个task处理一个RDD的partition,那么一个task只会执行一次function,function一次接收所有的partition数据,效率比较高。
比如,当要把RDD中的所有数据通过JDBC写入数据,如果使用map算子,那么需要对RDD中的每一个元素都创建一个数据库连接,这样对资源的消耗很大,如果使用mapPartitions算子,那么针对一个分区的数据,只需要建立一个数据库连接。
mapPartitions算子也存在一些缺点:对于普通的map操作,一次处理一条数据,如果在处理了2000条数据后内存不足,那么可以将已经处理完的2000条数据从内存中垃圾回收掉;但是如果使用mapPartitions算子,但数据量非常大时,function一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会OOM,即内存溢出。
因此,mapPartitions算子适用于数据量不是特别大的时候,此时使用mapPartitions算子对性能的提升效果还是不错的。(当数据量很大的时候,一旦使用mapPartitions算子,就会直接OOM)
在项目中,应该首先估算一下RDD的数据量、每个partition的数据量,以及分配给每个Executor的内存资源,如果资源允许,可以考虑使用mapPartitions算子代替map。
算子调优二:foreachPartition优化数据库操作
在生产环境中,通常使用foreachPartition算子来完成数据库的写入,通过foreachPartition算子的特性,可以优化写数据库的性能。
如果使用foreach算子完成数据库的操作,由于foreach算子是遍历RDD的每条数据,因此,每条数据都会建立一个数据库连接,这是对资源的极大浪费,因此,对于写数据库操作,我们应当使用foreachPartition算子。
与mapPartitions算子非常相似,foreachPartition是将RDD的每个分区作为遍历对象,一次处理一个分区的数据,也就是说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接,如图2-5所示:

使用了foreachPartition算子后,可以获得以下的性能提升:
1. 对于我们写的function函数,一次处理一整个分区的数据;
2. 对于一个分区内的数据,创建唯一的数据库连接;
3. 只需要向数据库发送一次SQL语句和多组参数;
在生产环境中,全部都会使用foreachPartition算子完成数据库操作。foreachPartition算子存在一个问题,与mapPartitions算子类似,如果一个分区的数据量特别大,可能会造成OOM,即内存溢出。
算子调优三:filter与coalesce的配合使用
在Spark任务中我们经常会使用filter算子完成RDD中数据的过滤,在任务初始阶段,从各个分区中加载到的数据量是相近的,但是一旦进过filter过滤后,每个分区的数据量有可能会存在较大差异,如图2-6所示:
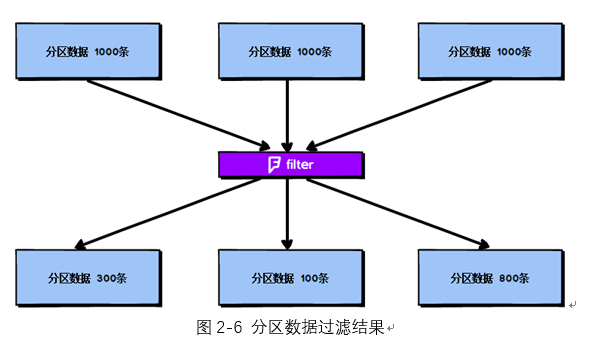
根据图2-6我们可以发现两个问题:
1. 每个partition的数据量变小了,如果还按照之前与partition相等的task个数去处理当前数据,有点浪费task的计算资源;
2. 每个partition的数据量不一样,会导致后面的每个task处理每个partition数据的时候,每个task要处理的数据量不同,这很有可能导致数据倾斜问题。
如图2-6所示,第二个分区的数据过滤后只剩100条,而第三个分区的数据过滤后剩下800条,在相同的处理逻辑下,第二个分区对应的task处理的数据量与第三个分区对应的task处理的数据量差距达到了8倍,这也会导致运行速度可能存在数倍的差距,这也就是数据倾斜问题。
针对上述的两个问题,我们分别进行分析:
1. 针对第一个问题,既然分区的数据量变小了,我们希望可以对分区数据进行重新分配,比如将原来4个分区的数据转化到2个分区中,这样只需要用后面的两个task进行处理即可,避免了资源的浪费。
2. 针对第二个问题,解决方法和第一个问题的解决方法非常相似,对分区数据重新分配,让每个partition中的数据量差不多,这就避免了数据倾斜问题。
那么具体应该如何实现上面的解决思路?我们需要coalesce算子。
repartition与coalesce都可以用来进行重分区,其中repartition只是coalesce接口中shuffle为true的简易实现,coalesce默认情况下不进行shuffle,但是可以通过参数进行设置。
假设我们希望将原本的分区个数A通过重新分区变为B,那么有以下几种情况:
- A > B(多数分区合并为少数分区)
① A与B相差值不大
此时使用coalesce即可,无需shuffle过程。
② A与B相差值很大
此时可以使用coalesce并且不启用shuffle过程,但是会导致合并过程性能低下,所以推荐设置coalesce的第二个参数为true,即启动shuffle过程。
- A < B(少数分区分解为多数分区)
此时使用repartition即可,如果使用coalesce需要将shuffle设置为true,否则coalesce无效。
我们可以在filter操作之后,使用coalesce算子针对每个partition的数据量各不相同的情况,压缩partition的数量,而且让每个partition的数据量尽量均匀紧凑,以便于后面的task进行计算操作,在某种程度上能够在一定程度上提升性能。
注意:local模式是进程内模拟集群运行,已经对并行度和分区数量有了一定的内部优化,因此不用去设置并行度和分区数量。
算子调优四:repartition解决SparkSQL低并行度问题
在第一节的常规性能调优中我们讲解了并行度的调节策略,但是,并行度的设置对于Spark SQL是不生效的,用户设置的并行度只对于Spark SQL以外的所有Spark的stage生效。
Spark SQL的并行度不允许用户自己指定,Spark SQL自己会默认根据hive表对应的HDFS文件的split个数自动设置Spark SQL所在的那个stage的并行度,用户自己通spark.default.parallelism参数指定的并行度,只会在没Spark SQL的stage中生效。
由于Spark SQL所在stage的并行度无法手动设置,如果数据量较大,并且此stage中后续的transformation操作有着复杂的业务逻辑,而Spark SQL自动设置的task数量很少,这就意味着每个task要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有Spark SQL的stage速度很慢,而后续的没有Spark SQL的stage运行速度非常快。
为了解决Spark SQL无法设置并行度和task数量的问题,我们可以使用repartition算子。
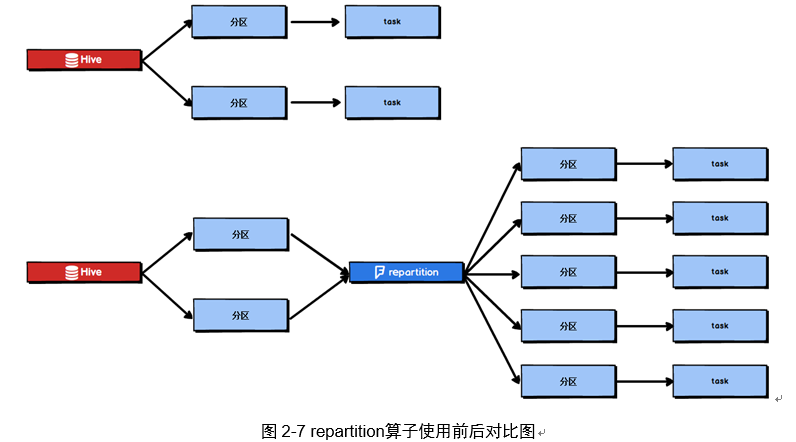
Spark SQL这一步的并行度和task数量肯定是没有办法去改变了,但是,对于Spark SQL查询出来的RDD,立即使用repartition算子,去重新进行分区,这样可以重新分区为多个partition,从repartition之后的RDD操作,由于不再设计Spark SQL,因此stage的并行度就会等于你手动设置的值,这样就避免了Spark SQL所在的stage只能用少量的task去处理大量数据并执行复杂的算法逻辑。使用repartition算子的前后对比如图2-7所示。
算子调优五:reduceByKey本地聚合
reduceByKey相较于普通的shuffle操作一个显著的特点就是会进行map端的本地聚合,map端会先对本地的数据进行combine操作,然后将数据写入给下个stage的每个task创建的文件中,也就是在map端,对每一个key对应的value,执行reduceByKey算子函数。reduceByKey算子的执行过程如图2-8所示:

使用reduceByKey对性能的提升如下:
- 本地聚合后,在map端的数据量变少,减少了磁盘IO,也减少了对磁盘空间的占用;
- 本地聚合后,下一个stage拉取的数据量变少,减少了网络传输的数据量;
- 本地聚合后,在reduce端进行数据缓存的内存占用减少;
- 本地聚合后,在reduce端进行聚合的数据量减少。
基于reduceByKey的本地聚合特征,我们应该考虑使用reduceByKey代替其他的shuffle算子,例如groupByKey。reduceByKey与groupByKey的运行原理如图2-9和图2-10所示:

根据上图可知,groupByKey不会进行map端的聚合,而是将所有map端的数据shuffle到reduce端,然后在reduce端进行数据的聚合操作。由于reduceByKey有map端聚合的特性,使得网络传输的数据量减小,因此效率要明显高于groupByKey。
spark调优——算子调优的更多相关文章
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- 【原创 Hadoop&Spark 动手实践 8】Spark 应用经验、调优与动手实践
[原创 Hadoop&Spark 动手实践 7]Spark 应用经验.调优与动手实践 目标: 1. 了解Spark 应用经验与调优的理论与方法,如果遇到Spark调优的事情,有理论思考框架. ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- iOS-Core-Animation-Advanced-Techniques/12-性能调优/性能调优.md
性能调优 代码应该运行的尽量快,而不是更快 - 理查德 在第一和第二部分,我们了解了Core Animation提供的关于绘制和动画的一些特性.Core Animation功能和性能都非常强大,但如果 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- sql让时间调前,调后的语句
时间调前,调后 select billid,DATEADD(mm,2,billdate) from bi_Bill 注:用dateadd(/时间年/月/日,调前或后多少,字段) mm为月份,2为调前两 ...
- Spark性能调优九之常用算子调优
1.使用mapPartitions算子提高性能 mapPartition的优点:使用普通的map操作,假设一个partition中有1万条数据,那么function就要被执行1万次,但是使用mapPa ...
- Spark(十)Spark之数据倾斜调优
一 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多.数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作 ...
随机推荐
- SQLite中字段顺序和PAGE_SIZE对性能的影响
1.背景 SQLite数据库中有1张表,该表含若干个字段,其中有1个字段为BLOB类型,且BLOB字段不是最后1个字段.表结构类似如下(col3为BLOB字段): T (col1 INTEGER,co ...
- LPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization [Paper Reading]
Motivation: 阈值分割的阈值并没有通过模型训练学出来,而是凭借主观经验设置,本文通过与背景得分比较提取对应的proposal,不用阈值的另一篇文章是Shou Zheng的AutoLoc,通过 ...
- Hive sampling 语法之TABLESAMPLE用法理解
官网关于LanguageManual Sampling的教程,部分截图如下,这里主要分享对TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解 官网中假设创建表时设 ...
- kubeadm安装依赖镜像
使用kubeadm安装的时候如果不能翻墙下载镜像是个很大的问题,这里自己把需要的镜像下载push下留作不时之需 docker pull davygeek/kube-proxy:v1.14.2 dock ...
- CSP-S2019 自闭记
$Day0:$ 最后一场zr十连测从200挂到60,嘴上说着攒rp心里觉得药丸. 得知自己在本校考试感觉8错. $Day1:$ 早上7点50到了校门口,没让进QAQ早知道我再下一把棋了. 于是跟熊聊天 ...
- 关于海大邮箱(ouc.edu)客户端配置及使用说明
关于海大邮箱(ouc.edu)客户端配置及使用说明 邮箱说明 系统简介 海大邮箱使用的是论客(Coremail)提供的邮件系统:(很多大学都是) Coremail论客简介(摘自官网): Coremai ...
- Java Base64Utils
Java Base64Utils /** * <html> * <body> * <P> Copyright 1994 JsonInternational</ ...
- 封装:WPF绘制曲线视图
原文:封装:WPF绘制曲线视图 一.目的:绘制简单轻量级的曲线视图 二.实现: 1.动画加载曲线 2.点击图例显示隐藏对应曲线 3.绘制标准基准线 4.绘制蒙板显示标准区域 曲线图示例: 心电图示例: ...
- Vue--基础2
目录 Vue--基础2 vue成员获取 分隔符成员 计算属性成员 什么是计算属性 计算属性的用法 注意: 监听属性成员 组件 组件的介绍 组件的优点: 局部组件 全局组件 组件复用的数据隔离 组件之间 ...
- 2019-08-01 JQuery事件
Jquery简单的事件 l blur(fn) 当失去焦点时 l change(fn) 当内容发生改变时 l click(fn) 当鼠标单击时 l dblclick 当鼠标双击时 l focus(fn) ...