深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
val sc = new SparkContext(conf)
val words = Array("one", "two", "two", "three", "three", "three")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))
val wordsCountWithReduce = wordsRDD.
reduceByKey(_ + _).
collect().
foreach(println)
val wordsCountWithGroup = wordsRDD.
groupByKey().
map(w => (w._1, w._2.sum)).
collect().
foreach(println)虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
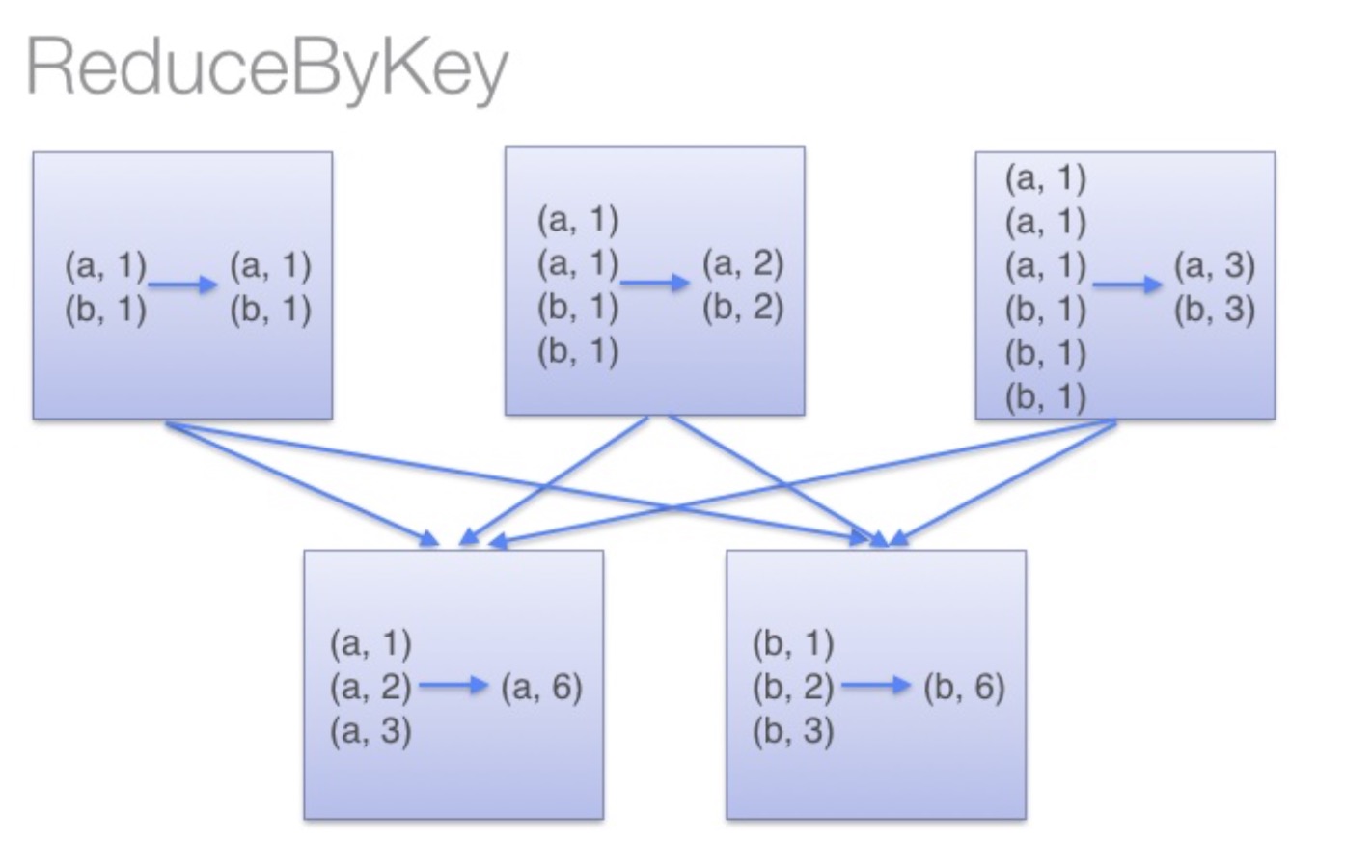
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的key调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时Spark会把数据保存到磁盘上。 不过在保存时每次会处理一个key的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
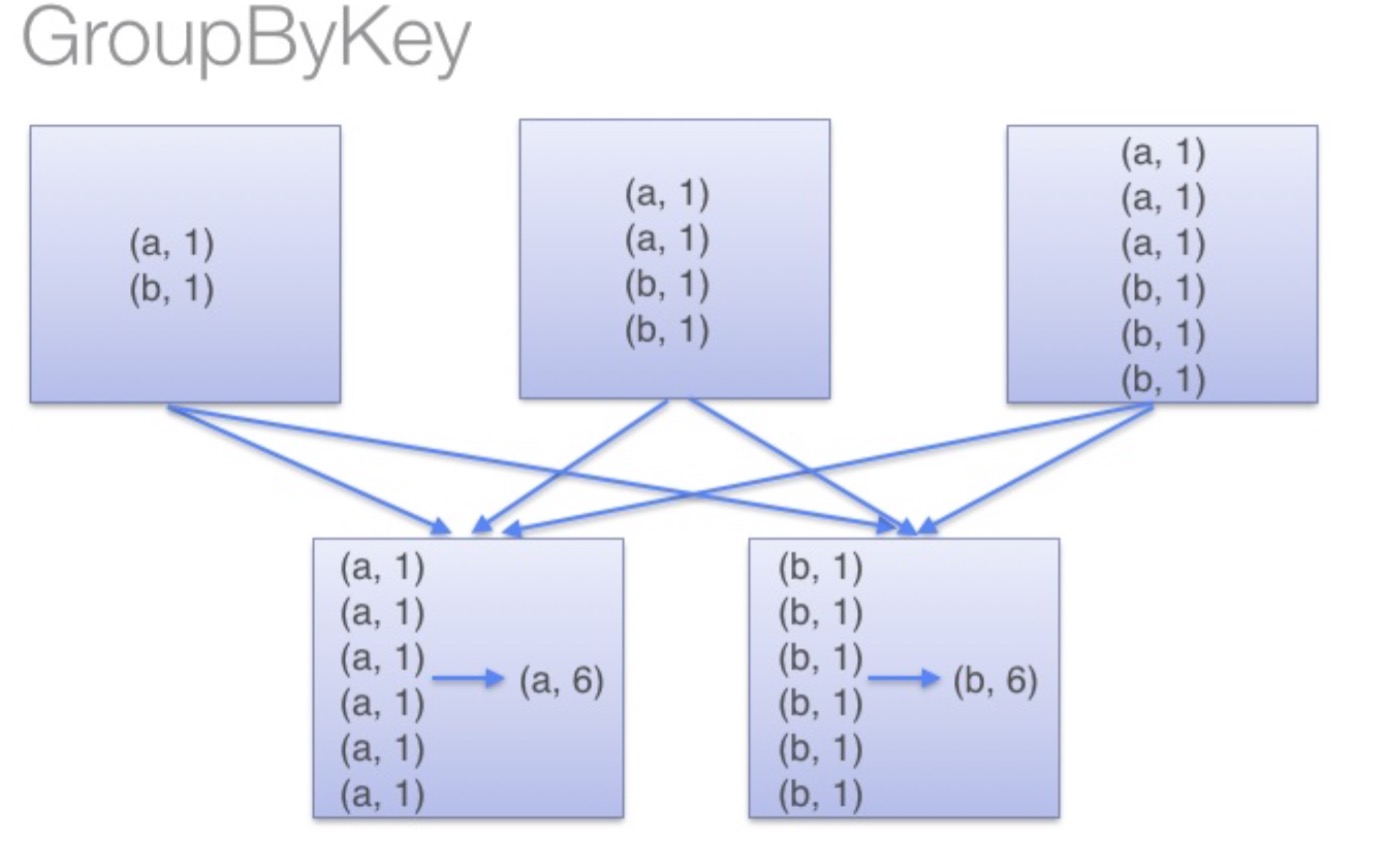
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
摘自:http://www.jianshu.com/p/0c6705724cff
深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- [Spark RDD_add_1] groupByKey & reduceBykey 的区别
[groupByKey & reduceBykey 的区别] 在都能实现相同功能的情况下优先使用 reduceBykey Combine 是为了减少网络负载 1. groupByKey 是没有 ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- Spark 学习笔记之 distinct/groupByKey/reduceByKey
distinct/groupByKey/reduceByKey: distinct: import org.apache.spark.SparkContext import org.apache.sp ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- Web框架本质及第一个Django实例 Web框架
Web框架本质及第一个Django实例 Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web ...
- php实现反转链表(链表题一定记得画图)(指向链表节点的指针本质就是一个记录地址的变量)($p->next表示的是取p节点的next域里面的数值,next只是p的一个属性)
php实现反转链表(链表题一定记得画图)(指向链表节点的指针本质就是一个记录地址的变量)($p->next表示的是取p节点的next域里面的数值,next只是p的一个属性) 一.总结 链表反转两 ...
- 关于API和SDK的个人理解及两者区别
关于API和SDK的个人理解及两者区别 最近接到公司的一项任务,调用第三方库的一些东西.因此记录一下在使用第三方的功能模块时常常提及到的两个名词--API和SDK. 1.SDK是什么?SDK:概念:软 ...
- String的本质是一个char*,只是以类的形式提供,使用起来比较方便
String的本质是一个char*,只是以类的形式提供,使用起来比较方便 Class String {private: char* m_data;}摘自<后台开发 核心技术与应用实践__徐晓鑫& ...
随机推荐
- 删除django
1.命令行运行python 2.import django3.print(django.__path__)4.删除django目录即可
- jQuery学习笔记之插件开发(4)
jQuery学习笔记之插件开发(4) github源码地址 插件:了让原有功能的增强. 1.插件的种类(3种):局部.全局.选择器插件 1.1封装对象方法的插件 这种类型的插件是把一些常用或者重复使用 ...
- OpenCV中IplImage/CvMat/Mat转化关系
原文链接:http://www.cnblogs.com/summerRQ/articles/2406109.html 如对内容和版权有何疑问,请拜访原作者或者通知本人. opencv中常见的与图像操作 ...
- Dll中的方法向外返回dynamic类型可能会失败
如果Dll中有某个类的方法返回dynamic实例,并且dynamic对象实际实例为匿名类类型,则Dll的外部使用者可能最终无法正常使用此dynamic对象.当使用此dynamic对象时,可能会遇到x属 ...
- window phone 8 开发准备工作(一)
一.下载安装Window phone SDK 1.Windows Phone SDK 8.0下载 http://www.microsoft.com/ZH-CN/download/details.asp ...
- Java基础学习笔记: 多线程,线程池,同步锁(Lock,synchronized )(Thread类,ExecutorService ,Future类)(卖火车票案例)
多线程介绍 学习多线程之前,我们先要了解几个关于多线程有关的概念.进程:进程指正在运行的程序.确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能. 线 ...
- Spring AOP --JDK动态代理方式
我们知道Spring是通过JDK或者CGLib实现动态代理的,今天我们讨论一下JDK实现动态代理的原理. 一.简述 Spring在解析Bean的定义之后会将Bean的定义生成一个BeanDefinit ...
- 原来这才是Kafka的“真面目”
作者介绍 郑杰文,腾讯云存储,高级后台工程师,2014 年毕业加入腾讯,先后从事增值业务开发.腾讯云存储开发.对业务性.技术平台型后台架构设计都有深入的探索实践.对架构的海量并发.高可用.可扩展性都有 ...
- python之testlink模块
1.安装:pip install TestLink-API-Python-client >>>>>>待续
- UDP、线程、mutex锁(day15)
一.基于UDP的网络编程模型 服务器端 .创建socket. .将fd和服务器的ip地址和端口号绑定 .recvfrom阻塞等待接收客户端数据 .业务处理 .响应客户端 客户端: .创建socket ...