深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local")
val sc = new SparkContext(conf)
val words = Array("one", "two", "two", "three", "three", "three")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))
val wordsCountWithReduce = wordsRDD.
reduceByKey(_ + _).
collect().
foreach(println)
val wordsCountWithGroup = wordsRDD.
groupByKey().
map(w => (w._1, w._2.sum)).
collect().
foreach(println)虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
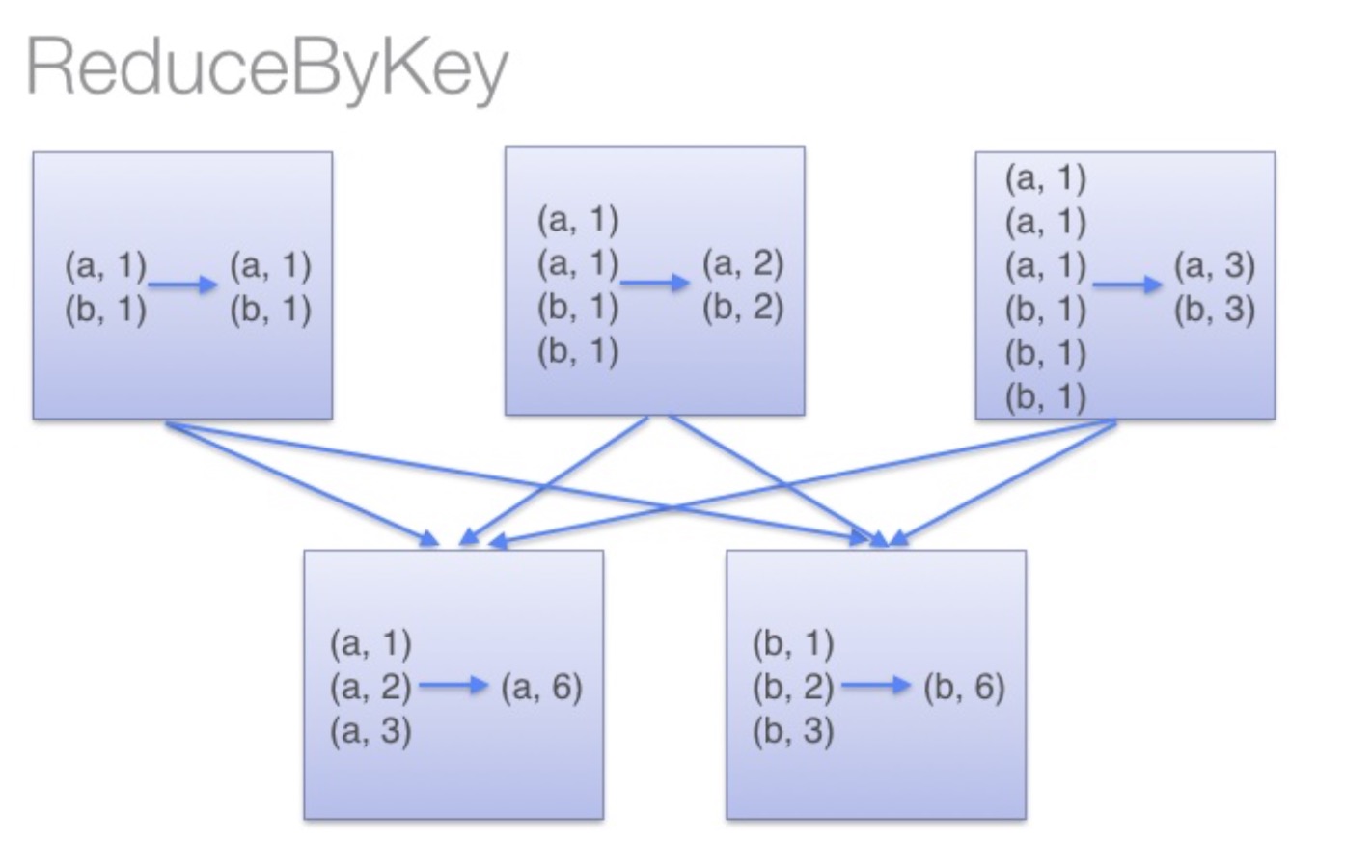
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的key调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时Spark会把数据保存到磁盘上。 不过在保存时每次会处理一个key的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
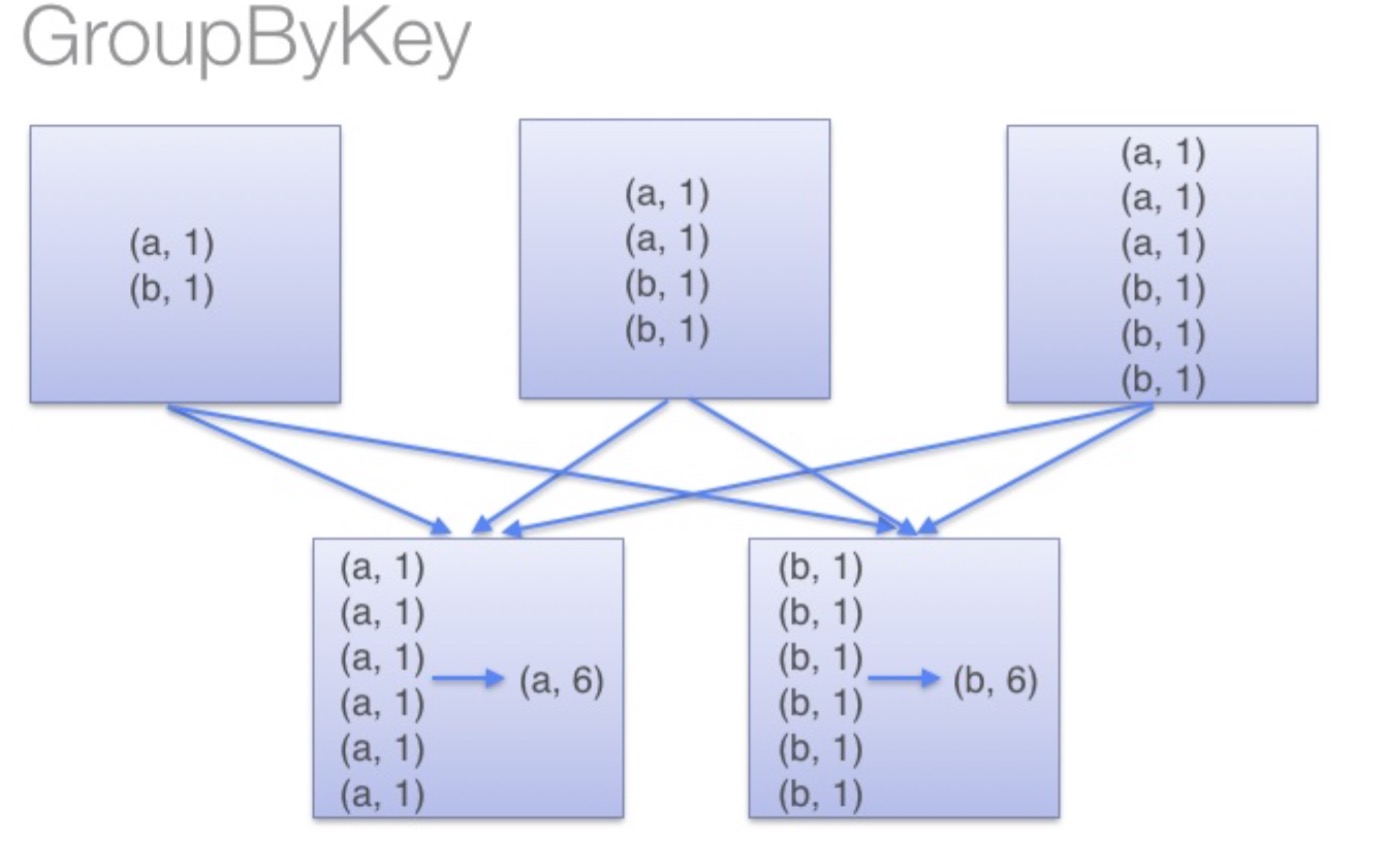
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
摘自:http://www.jianshu.com/p/0c6705724cff
深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- [Spark RDD_add_1] groupByKey & reduceBykey 的区别
[groupByKey & reduceBykey 的区别] 在都能实现相同功能的情况下优先使用 reduceBykey Combine 是为了减少网络负载 1. groupByKey 是没有 ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- Spark 学习笔记之 distinct/groupByKey/reduceByKey
distinct/groupByKey/reduceByKey: distinct: import org.apache.spark.SparkContext import org.apache.sp ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- Web框架本质及第一个Django实例 Web框架
Web框架本质及第一个Django实例 Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现Web ...
- php实现反转链表(链表题一定记得画图)(指向链表节点的指针本质就是一个记录地址的变量)($p->next表示的是取p节点的next域里面的数值,next只是p的一个属性)
php实现反转链表(链表题一定记得画图)(指向链表节点的指针本质就是一个记录地址的变量)($p->next表示的是取p节点的next域里面的数值,next只是p的一个属性) 一.总结 链表反转两 ...
- 关于API和SDK的个人理解及两者区别
关于API和SDK的个人理解及两者区别 最近接到公司的一项任务,调用第三方库的一些东西.因此记录一下在使用第三方的功能模块时常常提及到的两个名词--API和SDK. 1.SDK是什么?SDK:概念:软 ...
- String的本质是一个char*,只是以类的形式提供,使用起来比较方便
String的本质是一个char*,只是以类的形式提供,使用起来比较方便 Class String {private: char* m_data;}摘自<后台开发 核心技术与应用实践__徐晓鑫& ...
随机推荐
- linux下常用命令失效
注意:修改一下PATH环境变量 export PATH=/bin:/usr/bin/:. 可以把这句话加到你的.profile或者.bash_profile里,这样每次登录的时候都会生效
- layui 时间前后节点验证
var start = { istime: true, format: 'YYYY-MM-DD hh:mm:ss', max: '2099-06-16', istoday: true, choose: ...
- list用法(用到了再补充)
之前学list吧,也知道很多,但是到用的时候却无从下手,还是不熟悉的缘故,看来基础知识应该再加强,要达到信手拈来的程度才行. 先说下list的特性:有序可重复,也可以存储多个空值. 我用到的方法: L ...
- 分布式机器学习框架:CXXNet
caffe是很优秀的dl平台.影响了后面很多相关框架. cxxnet借鉴了很多caffe的思想.相比之下,cxxnet在实现上更加干净,例如依赖很少,通过mshadow的模板化使得gpu ...
- 点云处理软件Pointscene
转载于PCL中国:点云处理软件Pointscene 软件官网:https://pointscene.com/ 笔者评: Pointscene是目前的点云处理软件之一,其主要是操作简单直观 ...
- Redis 之set集合结构及命令详解
注:集合的元素具有唯一性,无序性 1.sadd key value1 value2 添加一个集合 2.smembers key 获取一个集合的所有值 3.srem key valu ...
- python tips:dict的key顺序
python3.6+版本中,dict的键值保持插入有序. t = list(range(10)) b = t[:] d = dict(zip(t, b)) print(list(d.items())) ...
- 【转载】java的常见类型转换
//Int型数字转换成String int num1=123456; //方法1 String str1=num1+""; System.out.println(str1); // ...
- python 遍历xml所有节点
1.xml文件 2.代码 #coding:utf-8 import xml import xml.etree.ElementTree as ET """ 实现从xml文件 ...
- pytorch实战(7)-----卷积神经网络
一.卷积: 卷积在 pytorch 中有两种方式: [实际使用中基本都使用 nn.Conv2d() 这种形式] 一种是 torch.nn.Conv2d(), 一种是 torch.nn.function ...