0807再整理SQL执行流程
转自http://www.cnblogs.com/annsshadow/p/5037667.html
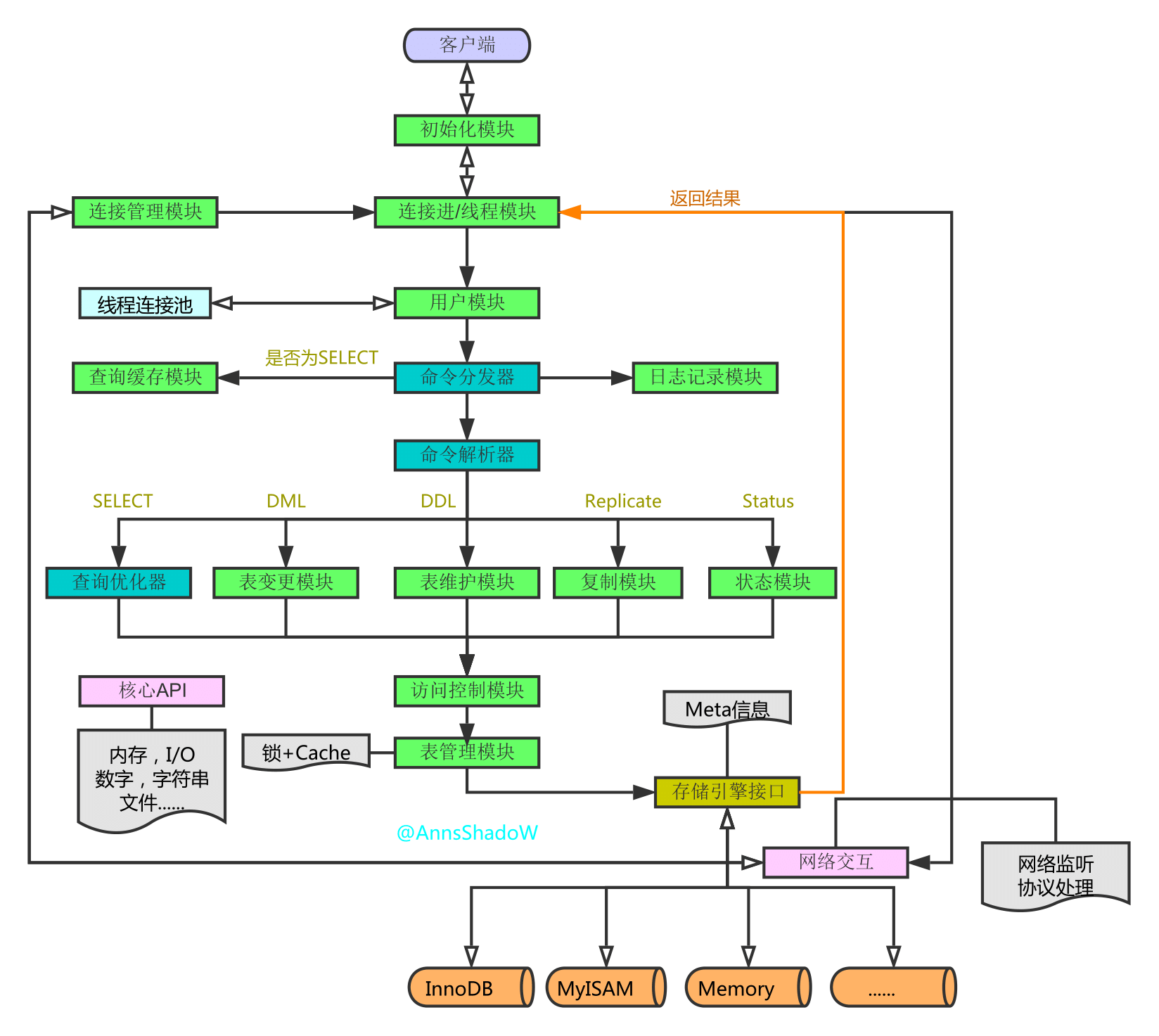
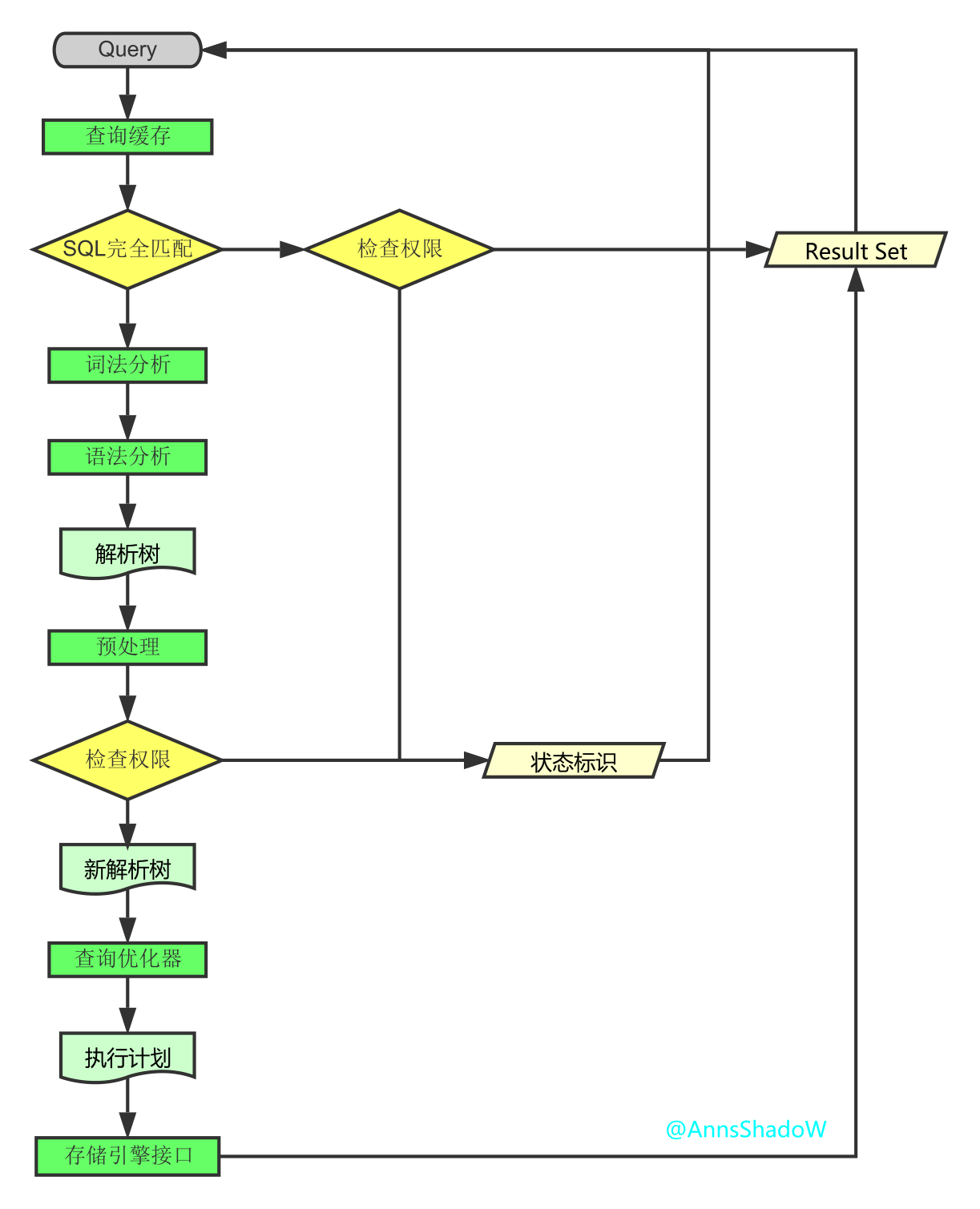
MySQL架构总览->查询执行流程->SQL解析顺序

SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

0807再整理SQL执行流程的更多相关文章
- Hive SQL执行流程分析
转自 http://www.tuicool.com/articles/qyUzQj 最近在研究Impala,还是先回顾下Hive的SQL执行流程吧. Hive有三种用户接口: cli (Command ...
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- MySQL架构与SQL执行流程
MySQL架构设计 下面是一张MySQL的架构图: 上方各个组件的含义如下: Connectors 指的是不同语言中与SQL的交互 Management Serveices & Utiliti ...
- MySQL笔记(5)-- SQL执行流程,MySQL体系结构
MySQL的体系结构,可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程:Server层包括连接层.查询缓存.分析器.优化器.执行器等,涵盖MySQL的大多数核心服务功能,以及所有 ...
- 深入浅出Mybatis系列(十)---SQL执行流程分析(源码篇)
最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前九篇中,介绍了mybatis的配置以及使用, 那么本篇将走进mybatis的源码,分析mybatis 的执行流程, ...
- 深入浅出Mybatis系列十-SQL执行流程分析(源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- spark-sql执行流程分析
spark-sql 架构 图1 图1是sparksql的执行架构,主要包括逻辑计划和物理计划几个阶段,下面对流程详细分析. sql执行流程 总体流程 parser:基于antlr框架对 sql解析,生 ...
- 3、myql的逻辑架构和sql的执行流程
msyql逻辑架构 逻辑架构的解析 逻辑架构图如下(序号代表的是:服务器处理客户端请求的流程) 1.1connectors connectors是指使用不同语言的客户端与mysql server服务器 ...
随机推荐
- Android 系统开机logo的修改【转】
本文转载自:http://blog.csdn.net/yandongqiangZHRJ/article/details/8585273 看到了好几个修改logo的博文,但是说的不是很清楚,在这里亲手送 ...
- 【POJ 3460】 Booksort
[题目链接] http://poj.org/problem?id=3460 [算法] IDA* 注意特判答案为0的情况 [代码] #include <algorithm> #include ...
- B1270 [BeijingWc2008]雷涛的小猫 dp
这个题的原始方法谁都会,但是n^3会T.之后直接优化,特别简单,就是每次处理出来每层的最大值,而不用枚举.之前没这么做是因为觉得在同一棵树的时候没有下落,所以不能用这个方法.后来想明白了,在同一棵树上 ...
- AAC帧格式及编码介绍
参考资料: AAC以adts格式封装的分析:http://wenku.baidu.com/view/45c755fd910ef12d2af9e74c.html aac编码介绍:http://wenku ...
- CentOS7 网卡名称重命名为eth*
CentOS7 禁用网卡名称命名规则,启动时传递"net.ifnames=0 biosdevname=0"/etc/default/grupgrup2-mkconfig -o /b ...
- 87.Ext_菜单组件_Ext.menu.Menu
转自:https://blog.csdn.net/lms1256012967/article/details/52574921 菜单组件常用配置: /* Ext.menu.Menu主要配置项表: it ...
- E20170902-hm
devise v. 设计; 想出; 发明; 策划; n. 遗赠; 遗赠的财产; 遗赠的条款; device n. 设备
- 0428-mysql(事务、权限)
1.事务 “事务”是一种可以保证“多条语句一次性执行完成”或“一条都不执行”的机制. 两种开始事务的方法: 1.set autocommit = 0; //false,此时不再是一条语句一个事务了, ...
- 使用Github做服务器展示前端页面
1)在github上创建自己一个项目,项目名称必须是你的github账号名.github.io 譬如 fk123456.github.io 因为我已经创建了,所以显示名字重复. 2)使用命令行的方式 ...
- Hadoop Hive概念学习系列之Hive里的2维坐标系统(第一步定位行键 -> 第二步定位字段)(二十三)
HBase里的4维坐标系统(第一步定位行键 -> 第二步定位列簇 -> 第三步定位列修饰符 -> 第四步定位时间戳) HBase里的4维坐标系统(第一步定位行键 ...