0807再整理SQL执行流程
转自http://www.cnblogs.com/annsshadow/p/5037667.html
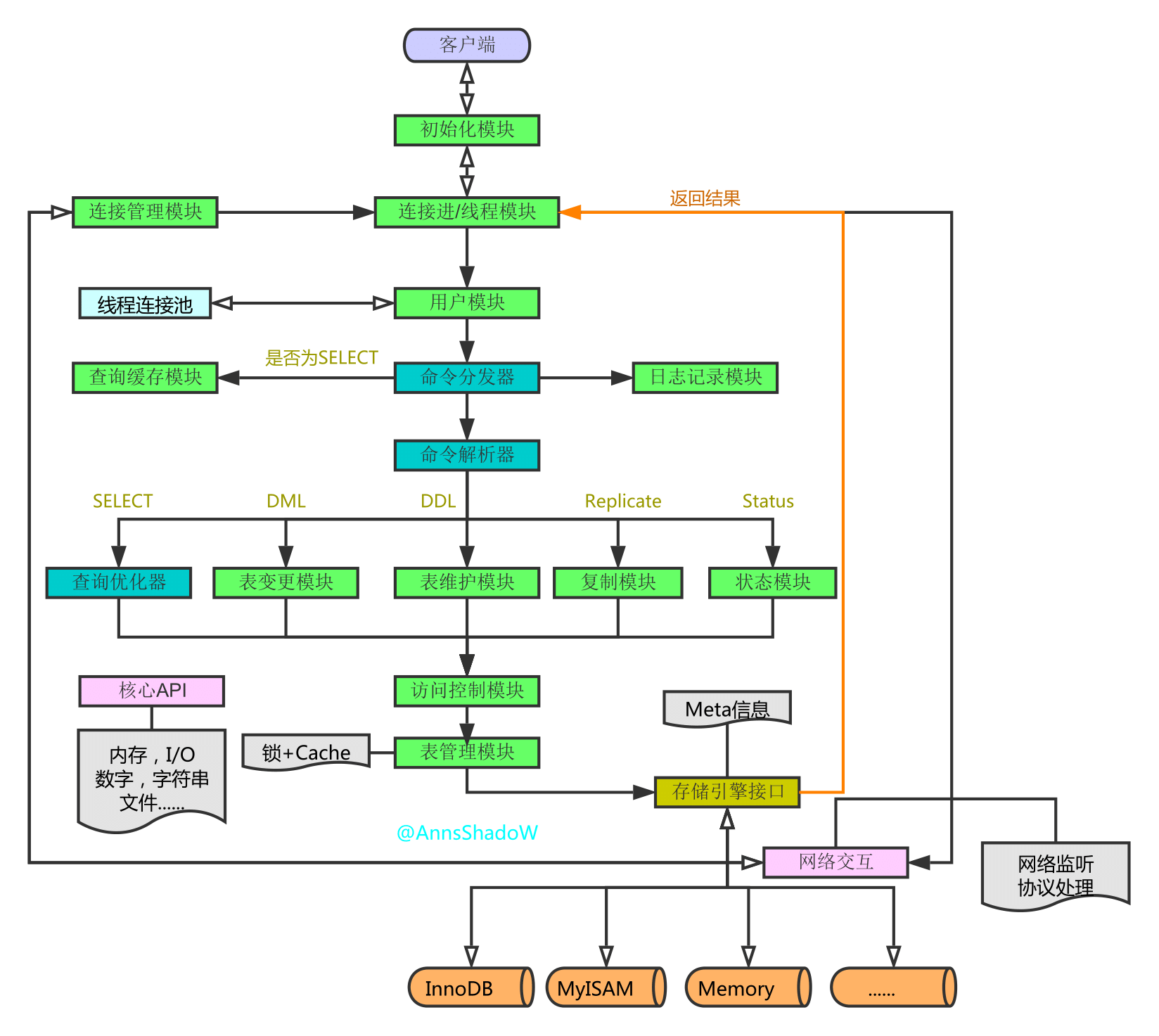
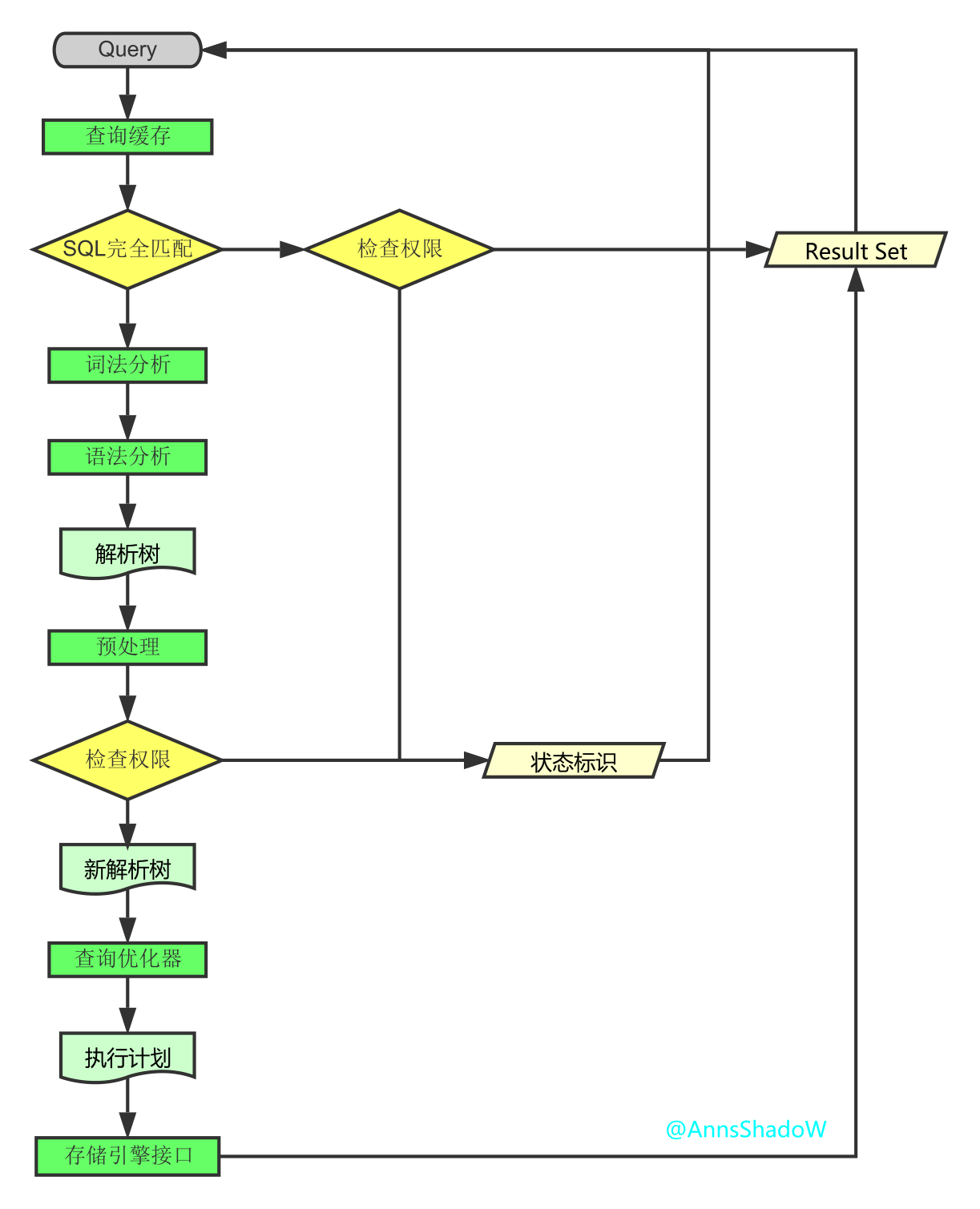
MySQL架构总览->查询执行流程->SQL解析顺序

SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

0807再整理SQL执行流程的更多相关文章
- Hive SQL执行流程分析
转自 http://www.tuicool.com/articles/qyUzQj 最近在研究Impala,还是先回顾下Hive的SQL执行流程吧. Hive有三种用户接口: cli (Command ...
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- MySQL架构与SQL执行流程
MySQL架构设计 下面是一张MySQL的架构图: 上方各个组件的含义如下: Connectors 指的是不同语言中与SQL的交互 Management Serveices & Utiliti ...
- MySQL笔记(5)-- SQL执行流程,MySQL体系结构
MySQL的体系结构,可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程:Server层包括连接层.查询缓存.分析器.优化器.执行器等,涵盖MySQL的大多数核心服务功能,以及所有 ...
- 深入浅出Mybatis系列(十)---SQL执行流程分析(源码篇)
最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前九篇中,介绍了mybatis的配置以及使用, 那么本篇将走进mybatis的源码,分析mybatis 的执行流程, ...
- 深入浅出Mybatis系列十-SQL执行流程分析(源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- spark-sql执行流程分析
spark-sql 架构 图1 图1是sparksql的执行架构,主要包括逻辑计划和物理计划几个阶段,下面对流程详细分析. sql执行流程 总体流程 parser:基于antlr框架对 sql解析,生 ...
- 3、myql的逻辑架构和sql的执行流程
msyql逻辑架构 逻辑架构的解析 逻辑架构图如下(序号代表的是:服务器处理客户端请求的流程) 1.1connectors connectors是指使用不同语言的客户端与mysql server服务器 ...
随机推荐
- media type
https://www.sitepoint.com/mime-types-complete-list/ application/base64 https://github.com/dotnet/doc ...
- Android中Calendar类的用法总结
Calendar是Android开发中需要获取时间时必不可少的一个工具类,通过这个类可以获得的时间信息还是很丰富的,下面做一个总结,以后使用的时候就不用总是去翻书或者查资料了. 在获取时间之前要先获得 ...
- Tool-Java:Spring Tool Suite
ylbtech-Tool-Java:Spring Tool Suite Spring Tool Suite 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 0. ...
- Java图形用户界面编程
1.Java图形用户界面编程概述 JavaAPI中提供了两套组件用于支持编写图形用户界面:AWT(抽象窗口包)和Swing 2. 容器(Container):重量级容器和轻量级容器(一个容器可以放置 ...
- javascript必须知道的知识要点(二)
该文章不详细叙述各知识要点的具体内容,仅把要点列出来,供大家学习的时候参照,或者检测自己是否熟练掌握了javascript,清楚各个部分的内容. 内建对象可划分为数据封装类对象.工具类对象.错误类对象 ...
- 动态title
<html><head><meta charset="uft8"><title>测试title</title></ ...
- 原生JS---2
js中的程序控制语句 常见的程序有三种执行结构: 1. 顺序结构 2. 分支结构 3. 循环结构 顺序结构:程序从第一行开始执行,按顺序执行到最后一行 分支结构:就像一条岔路口,必须选择且只能选择其中 ...
- idea使用svn
一.在idea中配置svn 二.导出maven项目 连接svn 点击checkout 点击ok就可以 到Commit Changes 这里有几个选项需要了解的: Auto-update after c ...
- Struts2 在登录拦截器中对ajax请求的处理
前言: 由于ajax请求不像http请求,可以直接进行页面跳转,你返回的所有东西,ajax都只会识别为一个字符串. 之前尝试的方法是在拦截器中返回一个标识给ajax,然后再在每一个ajax请求成功之后 ...
- Windows phone开发 页面布局之屏幕方向
(博客部分内容参考Windows phone开发文档) Windows phone的屏幕方向是利用Windows phone设备的方向传感器提供的数据实现切换的. Windows Phone支持纵向和 ...