HDFS的数据流读写数据 (面试开发重点)
1 HDFS写数据流程
1.1 剖析文件写入
HDFS写数据流程,如图所示
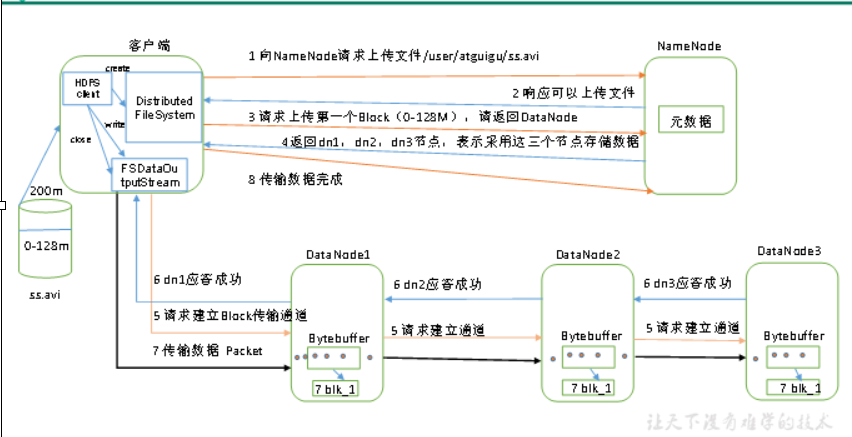
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
1.2 网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
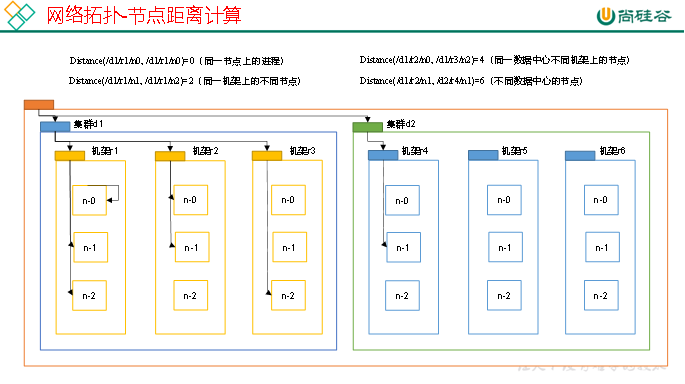
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述,如上图所示。
大家算一算每两个节点之间的距离,如下图所示。

1.3 机架感知(副本存储节点选择)
1. 官方ip地址
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack.
2. Hadoop2.7.2副本节点选择

4.2 HDFS读数据流程
HDFS的读数据流程,如图所示。
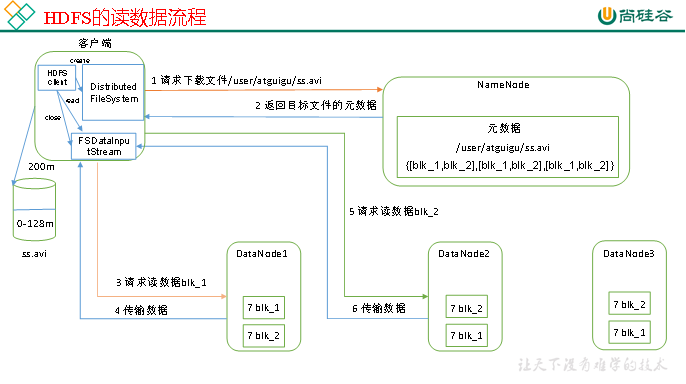
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
HDFS的数据流读写数据 (面试开发重点)的更多相关文章
- NameNode和SecondaryNameNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点) 1 NN和2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁 ...
- DataNode(面试开发重点)
1 DataNode工作机制 DataNode工作机制,如图所示. 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 VC中进程与进程之间共享内存 .net环境下跨进程、高频率读写数据 使用C#开发Android应用之WebApp 分布式事务之消息补偿解决方案
C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing). ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- .net环境下跨进程、高频率读写数据
一.需求背景 1.最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下. 单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑, 难点在于这个规模的热点数据,变化非常频繁. ...
- Python中异常和JSON读写数据
异常可以防止出现一些不友好的信息返回给用户,有助于提升程序的可用性,在java中通过try ... catch ... finally来处理异常,在Python中通过try ... except .. ...
随机推荐
- Python网络编程基础|百度网盘免费下载|零基础入门学习资料
百度网盘免费下载:Python网络编程基础|零基础学习资料 提取码:k7a1 目录: 第1部分 底层网络 第1章 客户/服务器网络介绍 第2章 网络客户端 第3章 网络服务器 第4章 域名系统 第5章 ...
- python xpath的基本用法
XPath是一种在XML文档中查找信息的语言,使用路径表达式在XML文档中进行导航.学习XPath需要对XML和HTML有基本的了解. 在XPath中,有七种类型的节点:文档(根)节点.元素.属性.文 ...
- Java进阶专题(十一) 想理解JVM看了这篇文章,就知道了!(中)
前言 上次讲解了JVM内存相关知识,今天继续JVM专题. JVM垃圾回收算法 什么是垃圾回收 程序的运行必然需要申请内存资源,无效的对象资源如果不及时处理就会一直占有内存资源,最终将导致内存溢 ...
- numpy巩固
导包 import numpy as np 创建二维数组 x = np.matrix([[1,2,3],[4,5,6]]) 创建一维数组 y = np.matrix([1,2,3,4,5,6]) x ...
- PHP array_diff_uassoc() 函数
实例 比较两个数组的键名和键值(使用用户自定义函数比较键名),并返回差集: <?phpfunction myfunction($a,$b){if ($a===$b){return 0;}retu ...
- PHP zip_read() 函数
定义和用法 zip_read() 函数读取打开的 zip 档案中的下一个文件.高佣联盟 www.cgewang.com 如果成功,该函数则返回包含 zip 档案中一个文件的资源.如果没有更多的项目可供 ...
- 探究:编程语言那么多,为什么偏偏是 C 语言成了大学的必修课?
谁叫你不幸生在中国了? ——何祚庥(中国科学院院士) 这是一本给非计算机专业的大学生的C语言的书.“我不是学计算机的,为啥要学C语言?”这个问题每年在中华大地都会被问上几百万次.被问的对象可能是老师, ...
- UOJ #22 UR #1 外星人
LINK:#22. UR #1 外星人 给出n个正整数数 一个初值x x要逐个对这些数字取模 问怎样排列使得最终结果最大 使结果最大的方案数又多少种? n<=1000,x<=5000. 考 ...
- bzoj 4238 电压
LINK:电压 一张图 每个点可以为黑点或百点 每一条边的两端都必须为一黑一白.询问又多少条边满足除了这条边不满足条件其余所有边都满足条件. 分析一下这个所谓的条件 每一条边的两端必须为一黑一白 所以 ...
- js 读取word和txt(react版) + 正则分割段落
show the code 前提:需要mammoth包~ import React, { useState, useReducer } from 'react'; import { Button, A ...