(数据科学学习手札95)elyra——jupyter lab最强插件
本文示例文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
jupyter lab是我最喜欢的编辑器,在过往的文章中也给大家介绍过很多相关资源和实用插件,但本文要给大家介绍的jupyter lab插件elyra,绝对是我使用过的最强大的jupyter lab插件没有之一,因为它的核心功能就是帮助我们解决数据分析工作中非常重要的问题——搭建工作流。
 图1
图1
2 利用elyra搭建工作流
在安装elyra插件集之前,请确保你的jupyter lab版本在2.0及以上,并且已经安装好了nodejs也就是所有jupyter lab拓展插件都需要的依赖。
不像常规的jupyter lab插件的安装方法,我们执行下列命令即可安装elyra下集成的多个插件:
pip install --upgrade elyra && jupyter lab build
安装完之后,你的jupyter lab操作界面外观会发生一些变化,我们先记住在安装elyra之前我们的jupyter lab界面长啥样(我使用的主题感兴趣的朋友可以通过jupyter labextension install jupyterlab-tailwind-theme来安装):
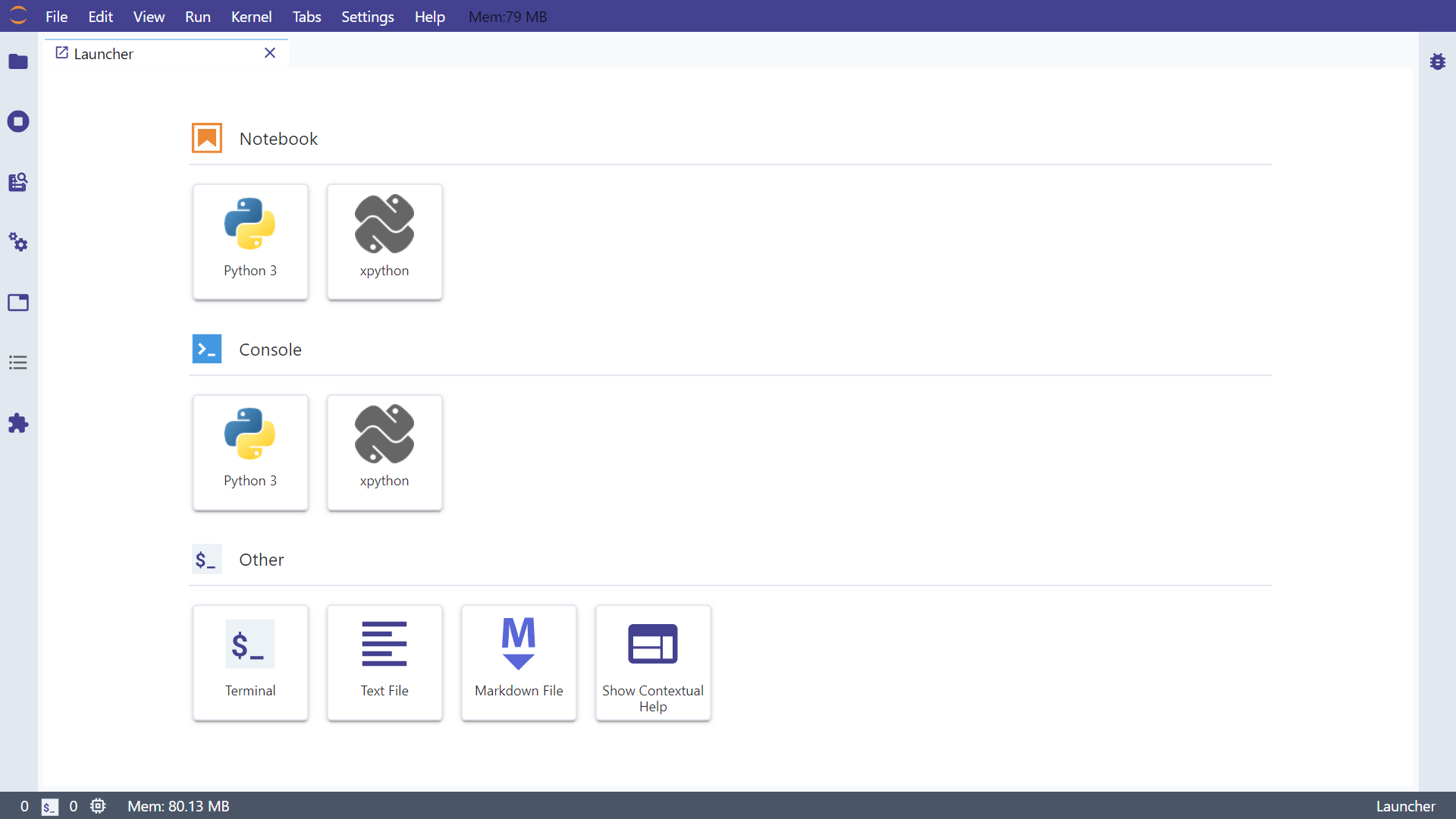 图2
图2
而在安装完成重启jupyter lab之后,除了左上角的jupyterlogo变化了之外,还新增了图中我用红框框选出来的地方:
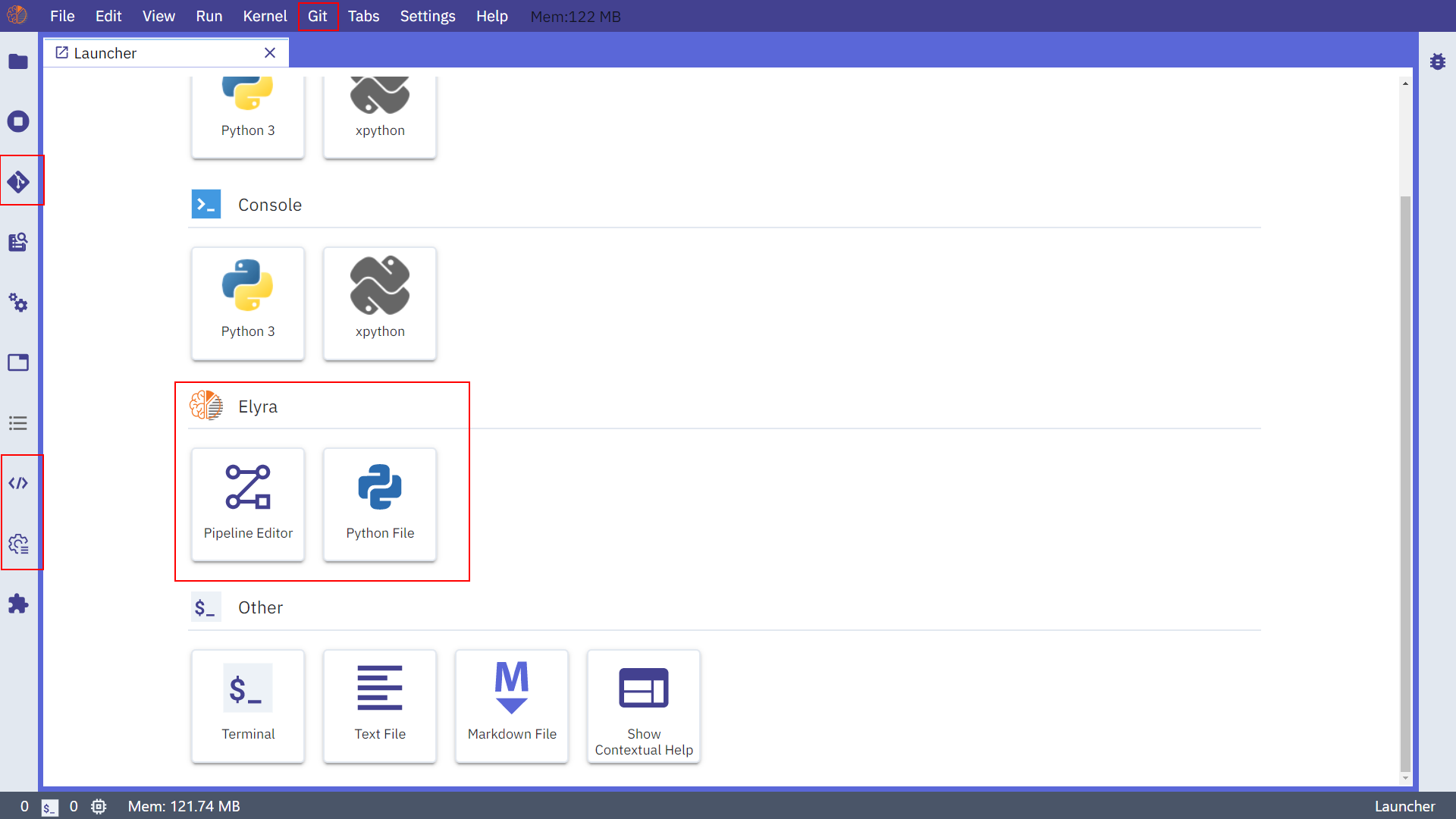 图3
图3
接下来我们就来介绍如何利用elyra交互式地搭建工作流。
elyra赋予了我们通过交互的方式将若干个ipynb文件组织成工作流的能力,为了方便演示,这里我们创建几个带有简单流程代码的ipynb文件:
 图4 step1.ipynb
图4 step1.ipynb
 图5 step2.ipynb
图5 step2.ipynb
 图6 step2-1.ipynb
图6 step2-1.ipynb
 图7 step2-2.ipynb
图7 step2-2.ipynb
接着我们在Launcher页面点击Pipeline Editor打开用来交互式编辑notebook流水线的界面:
 图8
图8
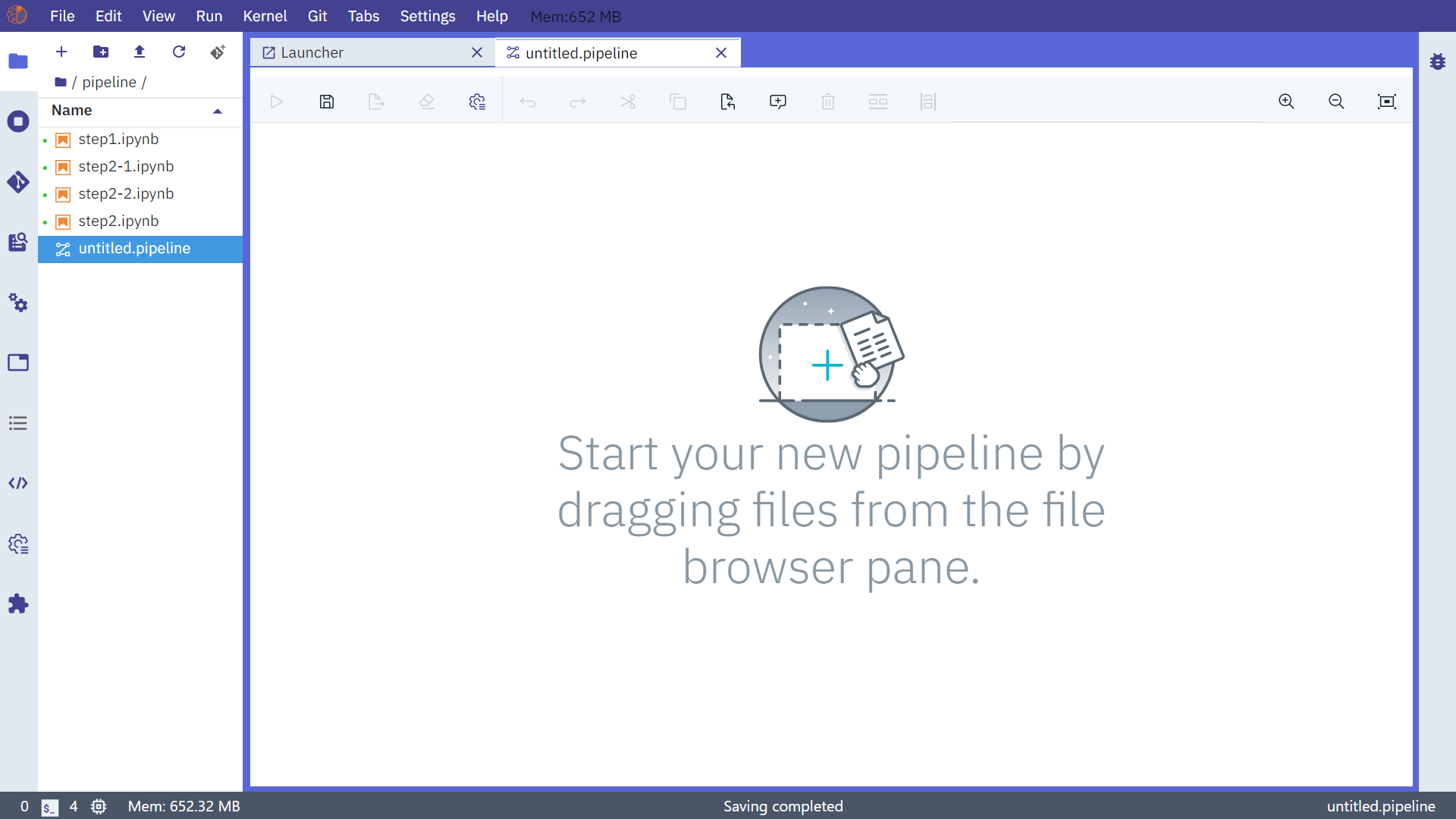 图9
图9
直接将侧边栏中对应的step1.ipynb文件拖拽进来:
 图10
图10
点击流水线界面中ipynb文件对应节点右侧的三个圆点,可以打开更多功能选项:
 图11
图11
因为我们是本地环境,所以这里只需要在properties下必填参数Runtime Image中随便选一个就行:
 图12
图12
保存之后,就完成了本地环境下单个节点的必要参数设置,同样的将其他ipynb文件拖拽进来,各自配置好必要参数再如图13所示将各节点联结起来:
 图13
图13
这样我们的流水线就搭建好了,是不是非常滴好玩~,接着点击左上角的运行按钮,输入流水线名称后即可开始运行我们的工作流:
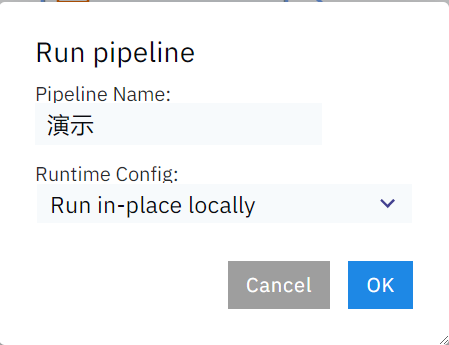 图14
图14
工作流执行成功之后也会有提示:
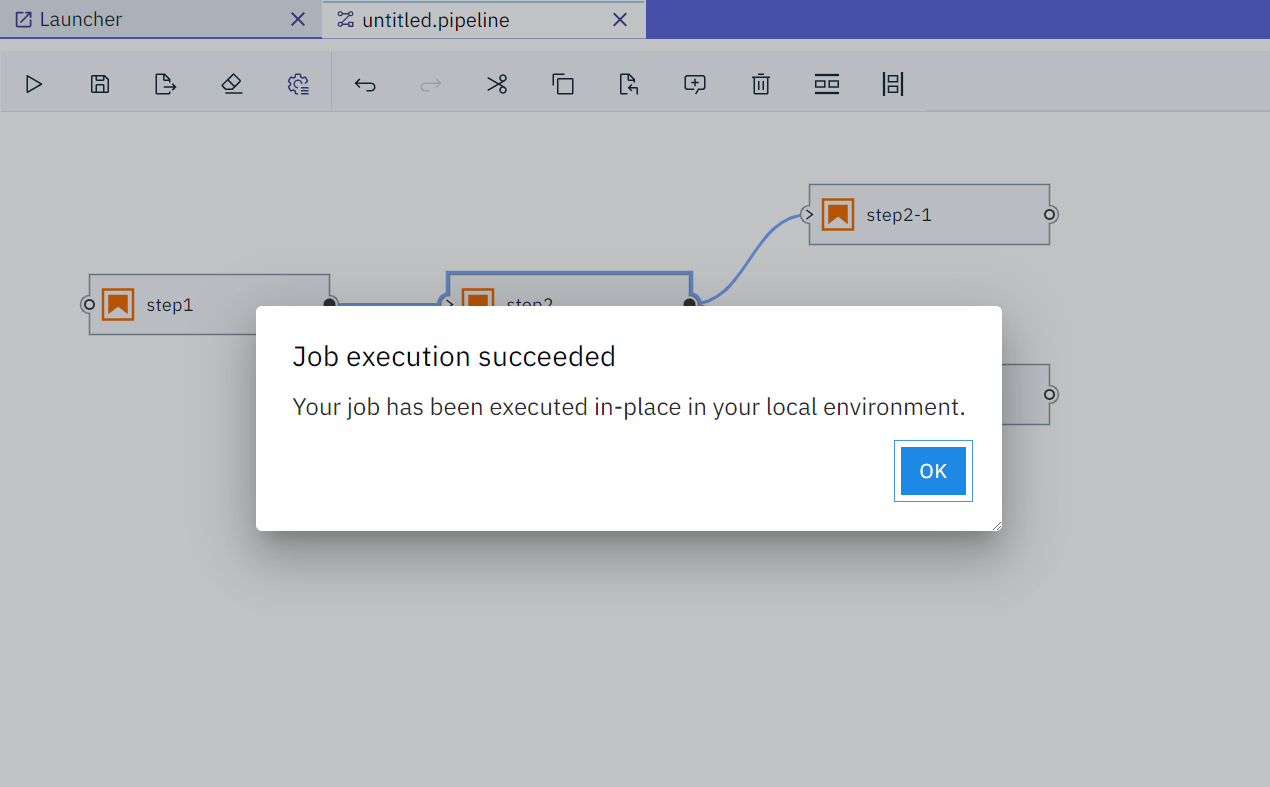 图15
图15
如果工作流执行到某个节点发生程序错误,也会有非常人性化的提示:
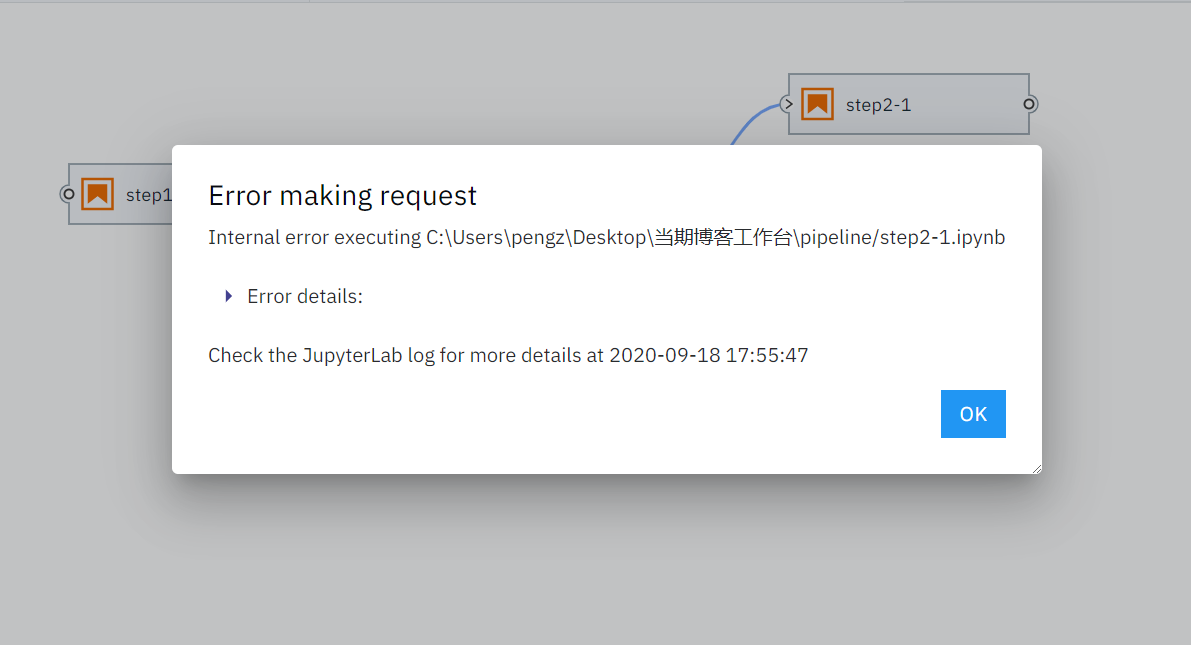 图16
图16
对应出错的ipynb错误代码块上方,elyra也会帮我们创建记录错误信息的markdown单元格:
 图17
图17
最好用的是,配合魔术命令%store,我们就可以跨notebook传递全局变量,而不需要再往外写出先前节点的结果文件:
利用%store 变量名将某个变量转化为跨kernel的全局变量:
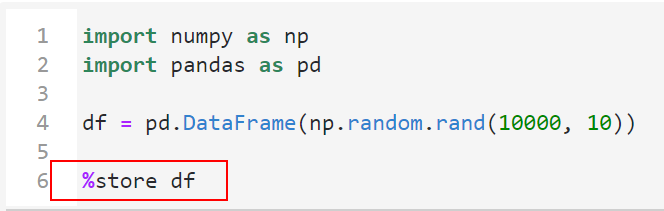 图18
图18
利用%store -r 变量名将跨kernel全局变量中的指定变量加载到当前kernel中:
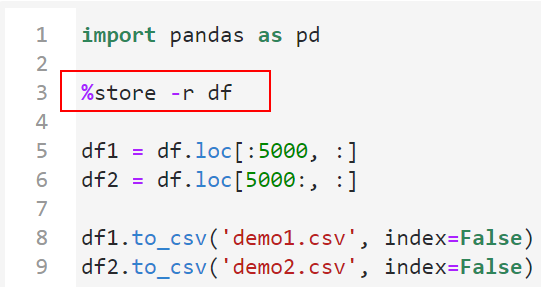 图19
图19
而除了搭建工作流这个核心功能外,elyra还有很多其他的实用功能,感兴趣的朋友可以前往官方文档(https://elyra.readthedocs.io/en/latest/)自行阅读学习。
 图20
图20
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札95)elyra——jupyter lab最强插件的更多相关文章
- (数据科学学习手札95)elyra——jupyter lab平台最强插件集
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 jupyter lab是我最喜欢的编辑器,在过往 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
随机推荐
- 理解正向代理&反向代理
通常的代理服务器,只用于代理内部网络对Internet的连接请求,客户机必须指定代理服务器,并将本来要直接发送到Web服务器上的http请求发送到代理服务器中.由于外部网络上的主机并不会配置并使用这个 ...
- NOIP2007 树网的核 [提高组]
题目:树网的核 网址:https://www.luogu.com.cn/problem/P1099 题目描述 设 T=(V,E,W)T=(V,E,W) 是一个无圈且连通的无向图(也称为无根树),每条边 ...
- SpringBoot项目 使用Jenkins进行自动化部署 (gitLab管理项目)_
1.部署服务器创建好对应文件夹和启动脚本 创建文件夹 mkdir /wdcloud/app/rps/rps-module-category 创建启动脚本 cd /wdcloud/app/rps/rps ...
- ACM study day3
今天练了二分和快速幂,题目挺难的,挑几个我做上的说一下吧. 先给出几个二分和快速幂的模板函数: 二分 void BS(int m) { int x=,y=a[m-]-a[]; while(y-x> ...
- Lombok插件有望被Intellij IDEA收编以改善兼容性问题
1. 前言 最近两个版本的Intellij IDEA没有办法使用lombok插件了,这种问题已经出现了多次,导致胖哥依然使用2020.1的旧版本.其实很多人和我一样也回滚到了旧版本.我一直认为是lom ...
- 类的加载,链接和初始化——1运行时常量池(来自于java虚拟机规范英文版本+本人的翻译和理解)
加载(loading):通过一个特定的名字,找到类或接口的二进制表示,并通过这个二进制表示创建一个类或接口的过程. 链接:是获取类或接口并把它结合到JVM的运行时状态中,以让类或接口可以被执行 初始化 ...
- 网站seo优化有什么优缺点
http://www.wocaoseo.com/thread-94-1-1.html seo是什么?这个可能是刚刚知道网络营销或搜索引擎营销的朋友们问的话,笔者在这里装一下,呵呵.说真的现 ...
- go语言之函数及闭包
一:函数 1 概述: 函数是 Go 程序源代码的基本构造单位,一个函数的定义包括如下几个部分,函数声明关键字 也町. 函数名.参数列表.返回列表和函数体.函数名遵循标识符的命名规则, 首字母的大小写决 ...
- Java 获取一段时间内的每一天
有时候我们会遇到一些业务场景,需要去获取一段时间内的每一天日期 public static List<Date> findDates(Date dBegin, Date dEnd) { L ...
- Photon PUN 二 大厅 & 房间
一, 简介 玩过 LOL , dota2, 王者荣耀 等MOBA类的游戏,就很容易理解大厅和房间了. LOL中一个服务器就相当与一个大厅; 什么电一,电二 ,,, 联通一区等 每一个区就相当于一个大厅 ...