kafka(三)原理剖析
一、生产者消息分区机制原理剖析
在使用Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分钟产生的日志量都能以 GB 数,因此如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题。
1.1、kafka为什么分区?
kafka有主题(Topic)的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,kafka的消息组织方式是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份。

分区的作用就是提供负载均衡的能力,就是为了实现系统的高伸缩性。不同的分区能够被放置在不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自的分区的读写请求处理。还可以添加新的节点机器来增加整体系统的吞吐量。
利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
1.2、kafka生产者分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。kafka为我们提供了默认的分区策略,同时也支持自定义分区策略。自定义分区策略需要显式地配置生产者端的参数partitioner.class。
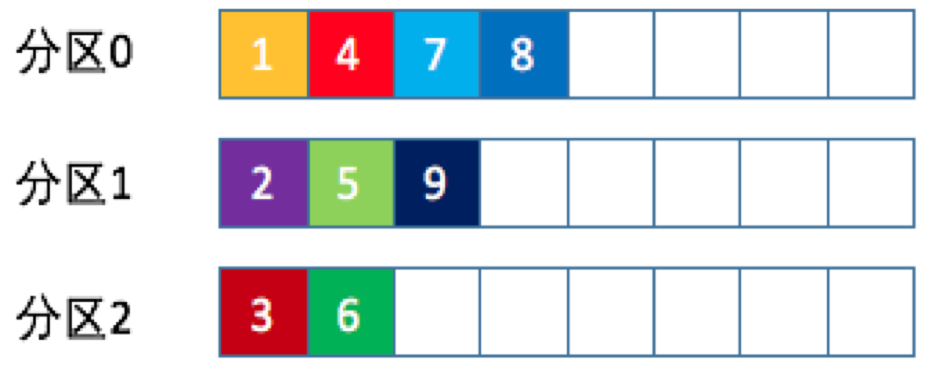
1.2.1、轮询策略
也称Round-robin策略,即顺序分配。比如一个主题下有3个分区,那么第一条消息被发送到分区0,第二条消息被发送到分区1,第三条被发送到分区2,以此类推。当第四条消息时又会重新开始,即分配到分区0。

轮询策略是kafka java生产者API默认提供的分区策略。如果未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区均匀地“码放”消息。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是最常用的分区策略之一。
1.2.2、随机策略
也称Randomness策略。所谓随机就是随意地将消息放置到任意一个分区上。
要实现随机策略只需要:先计算出该主题总分区数,然后随机返回一个小于它的整数值。从实际表现看,随机策略要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版中已经改为轮询。
1.2.3、按消息键保序策略
kafka允许为每条消息定义消息键,简称Key。它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务ID等;也可以用来表征消息元数据,特别是在kafka不支持时间戳的年代,在一些场景中,直接将消息创建时间封装进Key里面。
一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,每个分区下的消息处理都是有顺序的,如下图所示:
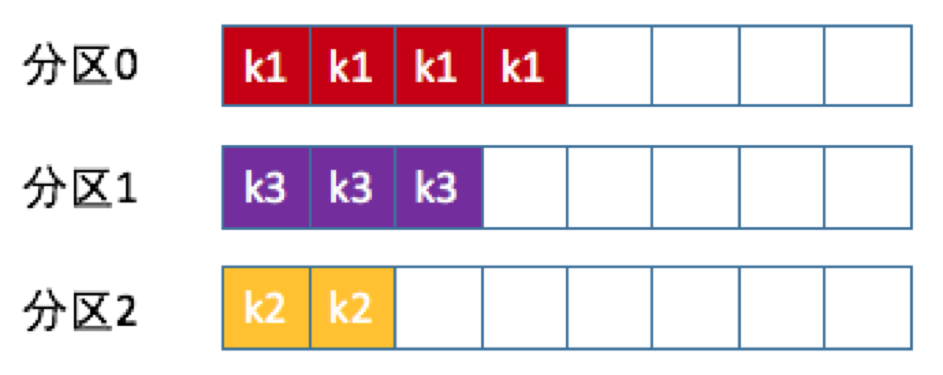
前面提到的kafka默认分区策略实际上同时实现了两种策略:如果指定了Key,那么默认实现按消息键保序策略;如果没有指定Key,则使用轮询策略。
kafka(三)原理剖析的更多相关文章
- Kafka底层原理剖析(近万字建议收藏)
Kafka 简介 Apache Kafka 是一个分布式发布-订阅消息系统.是大数据领域消息队列中唯一的王者.最初由 linkedin 公司使用 scala 语言开发,在2010年贡献给了Apache ...
- 《java学习三》并发编程 -------线程池原理剖析
阻塞队列与非阻塞队 阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞.试图从空的阻塞队列中获取元素的线程将会被阻塞,直到 ...
- 开源 serverless 产品原理剖析 - Kubeless
背景 Serverless 架构的出现让开发者不用过多地考虑传统的服务器采购.硬件运维.网络拓扑.资源扩容等问题,可以将更多的精力放在业务的拓展和创新上. 随着 serverless 概念的深入人心, ...
- ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行
ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行 核心框架 ASP.NET Core APP 创建与运行 总结 之前两篇文章简析.NET Core 以及与 .NET Framew ...
- 【Xamarin挖墙脚系列:Xamarin.IOS机制原理剖析】
原文:[Xamarin挖墙脚系列:Xamarin.IOS机制原理剖析] [注意:]团队里总是有人反映卸载Xamarin,清理不完全.之前写过如何完全卸载清理剩余的文件.今天写了Windows下的批命令 ...
- 【Xamarin 跨平台机制原理剖析】
原文:[Xamarin 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原 ...
- iPhone/Mac Objective-C内存管理教程和原理剖析
http://www.cocoachina.com/bbs/read.php?tid-15963.html 版权声明 此文版权归作者Vince Yuan (vince.yuan#gmail.com)所 ...
- 【Xamain 跨平台机制原理剖析】
原文:[Xamain 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原生 ...
- ASP.NET Core 运行原理剖析
1. ASP.NET Core 运行原理剖析 1.1. 概述 1.2. 文件配置 1.2.1. Starup文件配置 Configure ConfigureServices 1.2.2. appset ...
随机推荐
- 前端:css3的过渡与动画
一.css3过渡知识 (一).概述 1.CSS3过渡是元素从一种样式逐渐改变为另一种的效果. 2.实现过渡效果的两个要件: 规定把效果添加到那个css属性上. 规定效果时长 定义 ...
- 02-Dockerfile的基本使用
1. FROM 作用:指定基础镜像 使用:FROM 镜像名 demo: FROM mysql FROM mysql:5.6 2. RUN 作用:指令是用来执行命令行命令的 使用: shell格式:RU ...
- css 08-CSS属性:定位属性
08-CSS属性:定位属性 CSS的定位属性有三种,分别是绝对定位.相对定位.固定定位. position: absolute; <!-- 绝对定位 --> position: relat ...
- APEX-数据导出/打印
前言: 由于公司使用了Oracle APEX构建应用,且在APEX新版本v20.2版本中增强了相关报表导出数据相关功能:正好现在做的事情也需要类似的功能,就先来学习一下Oracle的APEX相关功能及 ...
- Django入门实战一
前言 Django是高水准的Python编程语言驱动的一个开源模型.视图,控制器风格的Web应用程序框架,它起源于开源社区.使用这种架构,程序员可以方便.快捷地创建高品质.易维护.数据库驱动的应用程序 ...
- 如何优雅地使用云原生 Prometheus 监控集群
作者陈凯烨,腾讯云前端开发工程师.负责 TKE 集群,弹性集群和云原生监控等模块控制台开发. 概述 Prometheus 是一套开源的系统监控报警框架.2016 年,Prometheus 正式加入 C ...
- python线性回归
一.理论基础 1.回归公式 对于单元的线性回归,我们有:f(x) = kx + b 的方程(k代表权重,b代表截距). 对于多元线性回归,我们有: 或者为了简化,干脆将b视为k0·x0,,其中k0为1 ...
- JXL封装不能使用static关键字问题
最近要做一个Excel导出的功能,由于文件不大,涉及到了很多Excel表格样式和公式计算,我采用了JXL的方式导出.由于逻辑大多是金额,所以我在封装JXL的时候写了两个静态final变量,代码如下: ...
- Python之selenium创建多个标签页
最近在做一个项目,需要用到cookies登录,想法是,在同一个浏览器下,打开两个标签页进行.让其自动获取cookies,先记录,不行的话,到时候再手动加载cookies. 1 ''' 2 #selen ...
- ASP.NET Web API运行提示:找到了与该请求匹配的多个操作的解决方法