Spark Mllib里的向量标签概念、构成(图文详解)
不多说,直接上干货!
Labeled point: 向量标签
向量标签用于对Spark Mllib中机器学习算法的不同值做标记。
例如分类问题中,可以将不同的数据集分成若干份,以整数0、1、2,....进行标记,即我们程序开发者可以根据自己业务需要对数据进行标记。
向量标签和向量是一起的,简单来说,可以理解为一个向量对应的一个特殊值,这个值的具体内容可以由用户指定,比如你开发了一个算法A,这个算法对每个向量处理之后会得出一个特殊的标记值p,你就可以把p作为向量标签。同样的,更为直观的话,你可以把向量标签作为行索引,从而用多个本地向量构成一个矩阵(当然,MLlib中已经实现了多种矩阵)。
LabeledPoint是建立向量标签的静态类。
features用于显示打印标记点所代表的数据内容。
label用于显示标记数。
testLabeledPoint.scala

package zhouls.bigdata.chapter4
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.regression.LabeledPoint
object testLabeledPoint {
def main(args: Array[String]) {
val vd: Vector = Vectors.dense(2, 0, 6) //建立密集向量
val pos = LabeledPoint(1, vd) //对密集向量建立标记点
println(pos.features) //打印标记点内容数据
println(pos.label) //打印既定标记
val vs: Vector = Vectors.sparse(4, Array(0,1,2,3), Array(9,5,2,7)) //建立稀疏向量
val neg = LabeledPoint(2, vs) //对密集向量建立标记点
println(neg.features) //打印标记点内容数据
println(neg.label) //打印既定标记
}
}

注意:
val pos = LabeledPoint(1, vd)
val neg = LabeledPoint(2, vs)
除了这两种建立向量标签。还可以从数据库中获取固定格式的数据集方法。 数据格式如下:
label index1:value1 index2:value2
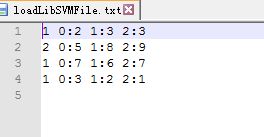
label是此数据集中每一行给定的标签,而后的index是标签所标注的这一行的不同的索引值,而紧跟在各自index后的value是不同索引所形成的数据值。 testLabeledPoint2.scala
package zhouls.bigdata.chapter4
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark._
import org.apache.spark.mllib.util.MLUtils
object testLabeledPoint2 {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("testLabeledPoint2")//建立本地环境变量
val sc = new SparkContext(conf) //建立Spark处理
val mu = MLUtils.loadLibSVMFile(sc, "data/input/chapter4/loadLibSVMFile.txt") //读取文件
mu.foreach(println) //打印内容
}
}
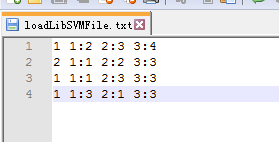
以下是数据
输出结果是
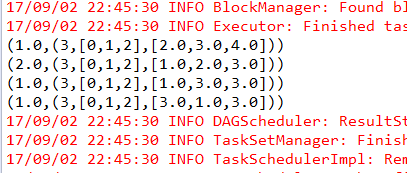
(1.0,(3,[0,1,2],[2.0,3.0,4.0]))
(2.0,(3,[0,1,2],[1.0,2.0,3.0]))
(1.0,(3,[0,1,2],[1.0,3.0,3.0]))
(1.0,(3,[0,1,2],[3.0,1.0,3.0]))

具体,见
Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mllib数理统计
Spark Mllib里的向量标签概念、构成(图文详解)的更多相关文章
- Spark Mllib里的本地矩阵概念、构成(图文详解)
不多说,直接上干货! Local matrix:本地矩阵 数组Array(1,2,3,4,5,6)被重组成一个新的2行3列的矩阵. testMatrix.scala package zhouls.bi ...
- Windows里下载并安装phpstudy(图文详解)
不多说,直接上干货! 帮助站长快速搭建网站服务器平台! phpstudy软件简介 此是基于phpStudy 2016.01.01. 该程序包集成最新的Apache+Nginx+LightTPD+PHP ...
- 再谈Hive元数据如hive_metadata与Linux里MySQL的深入区别(图文详解)
不多说,直接上干货! [bigdata@s201 conf]$ vim hive-site.xml [bigdata@s201 conf]$ pwd /soft/hive/conf [bigdata@ ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装Theano(图文详解)
不多说,直接上干货! Theano的安装教程目前网上一搜很多,前几天折腾了好久,终于安装成功了Anaconda3(Python3)的Theano,嗯~发博客总结并分享下经验教训吧. 渣电脑,显卡用的是 ...
- Spark Mllib里的本地向量集(密集型数据集和稀疏型数据集概念、构成)(图文详解)
不多说,直接上干货! Local vector : 本地向量集 由两类构成:稀疏型数据集(spares)和密集型数据集(dense) (1).密集型数据集 例如一个向量数据(9,5,2,7),可以设 ...
- Spark Mllib里的分布式矩阵(行矩阵、带有行索引的行矩阵、坐标矩阵和块矩阵概念、构成)(图文详解)
不多说,直接上干货! Distributed matrix : 分布式矩阵 一般能采用分布式矩阵,说明这数据存储下来,量还是有一定的.在Spark Mllib里,提供了四种分布式矩阵存储形式,均由支 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
- Spark Mllib里决策树回归分析如何对numClasses无控制和将部分参数设置为variance(图文详解)
不多说,直接上干货! 在决策树二元或决策树多元分类参数设置中: 使用DecisionTree.trainClassifier 见 Spark Mllib里如何对决策树二元分类和决策树多元分类的分类 ...
- Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的 ...
随机推荐
- listen 59
Different Brain Regions Handle Different Music Types (Vivaldi) versus (the Beatles) . Both great. Bu ...
- Linux网络编程socket错误分析
socket错误码: EINTR: 阻塞的操作被取消阻塞的调用打断.如设置了发送接收超时,就会遇到这种错误. 只能针对阻塞模式的socket.读,写阻塞的socket时,-1返回,错误号为INTR.另 ...
- OpenCV——PS 滤镜算法之极坐标变换到平面坐标
// define head function #ifndef PS_ALGORITHM_H_INCLUDED #define PS_ALGORITHM_H_INCLUDED #include < ...
- zepto.fullpage
内容来自:颜海镜 <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- CodeForcesdiv1:995C - Leaving the Bar(随机算法+贪心)
For a vector →v=(x,y)v→=(x,y), define |v|=√x2+y2|v|=x2+y2. Allen had a bit too much to drink at the ...
- 1135 Is It A Red-Black Tree(30 分)
There is a kind of balanced binary search tree named red-black tree in the data structure. It has th ...
- 查看MySql数据库物理文件存放位置
查找数据库文件位置使用命令 show global variables like "%datadir%";
- 1、scala安装和基本语法
一.安装Scala 1.安装 因为Scala是基于Java虚拟机,也就是JVM的一门编程语言. 所有Scala的代码,都需要经过编译为字节码,然后交由Java虚拟机来运行. 所以Scala和Java是 ...
- Java线程安全与多线程开发
互联网上充斥着对Java多线程编程的介绍,每篇文章都从不同的角度介绍并总结了该领域的内容.但大部分文章都没有说明多线程的实现本质,没能让开发者真正“过瘾”. 从Java的线程安全鼻祖内置锁介绍开始,让 ...
- 基于pthread实现读写锁
读写锁可用于在多线程访问map等数据结构时使用 #include <pthread.h> class ReadWriteLock { public: ReadWriteLock() { p ...