jmeter 实时搜索结果
因为JMeter 2.13你可以得到实时搜索结果发送到后端通过 后端侦听器 使用潜在的任何后端(JDBC、JMS网络服务,Š) 通过提供一个实现类 AbstractBackendListenerClient 。
JMeter附带GraphiteBackendListenerClient它允许您发送指标石墨后端。
这个特性提供了:
- 生活的结果
- 漂亮的图表为指标
- 比较2个或更多的负载测试的能力
- 监控数据存储在同一后端只要JMeter结果
- 一个Š
在本文档中,我们将配置设置图和historize 2中的数据不同的后端:
- InfluxDB
- 石墨
指标暴露
线程/虚拟用户指标
线程指标如下:
- < rootMetricsPrefix > test.minAT
- 分钟活动线程
- < rootMetricsPrefix > test.maxAT
- 马克斯活动线程
- < rootMetricsPrefix > test.meanAT
- 活动线程的意思
- < rootMetricsPrefix > test.startedT
- 启动线程
- < rootMetricsPrefix > test.endedT
- 完成线程
响应时间指标
响应相关指标如下:
- < rootMetricsPrefix > < samplerName > .ok.count
- 许多成功的响应采样器的名字
- < rootMetricsPrefix > < samplerName > .h.count
- 服务器每秒钟,这个指标堆积样本结果和子结果(如果使用事务控制器,应该无节制的“生成父取样器”)
- < rootMetricsPrefix > < samplerName > .ok.min
- 最小响应时间成功响应采样器的名字
- < rootMetricsPrefix > < samplerName > .ok.max
- 最大响应时间成功响应采样器的名字
- < rootMetricsPrefix > < samplerName > .ok.pct < percentileValue >
- 百分比计算成功响应采样器的名字。 将有一个为每个计算值指标。
- < rootMetricsPrefix > < samplerName > .ko.count
- 失败的反应数量取样器的名字
- < rootMetricsPrefix > < samplerName > .ko.min
- 最小响应时间没有响应的采样器的名字
- < rootMetricsPrefix > < samplerName > .ko.max
- 最大响应时间没有响应的采样器的名字
- < rootMetricsPrefix > < samplerName > .ko.pct < percentileValue >
- 百分比计算失败的响应的采样器的名字。 将有一个为每个计算值指标。
- < rootMetricsPrefix > < samplerName > .a.count
- 取样器的反应数量名称(好吧。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.min
- 最小响应时间响应采样器的名字(最低的好。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.max
- 最大响应时间取样器名称(Max的反应好。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.pct < percentileValue >
- 百分比计算响应的采样器的名字。 将有一个为每个计算值指标。 (好和失败样本计算总数)
默认的 百分位数 设置在 后端侦听器 是“90;95;95”, 即3百分位数90%、95%和99%。
的 石墨命名层次结构 使用点(“。”)单独的元素。 这可能与十进制百分位值混淆。 JMeter转换任何这样的价值观,用下划线代替点(“。”)(“-”)。 例如,“ 99.9 “变成了” 99年_9 ”
默认JMeter发送采样指标累计samplerName” 所有 ”。 如果后端侦听器 samplersList 配置,然后JMeter也发送指标吗 除非匹配样本的名字 summaryOnly = true
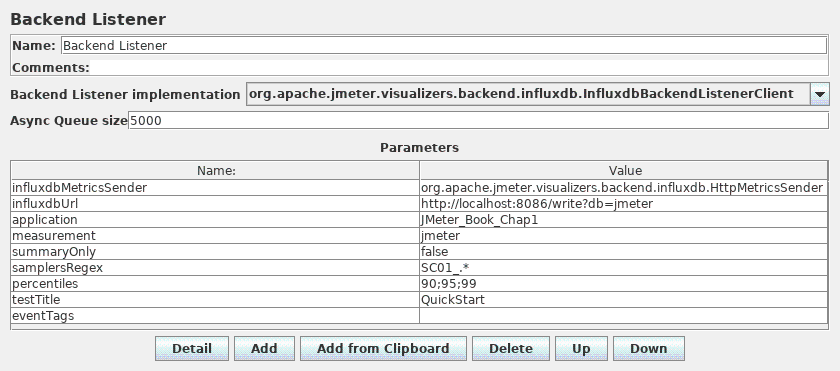
JMeter配置
JMeter指标发送给后端添加一个 BackendListener 使用GraphiteBackendListenerClient。
 石墨的配置
石墨的配置
InfluxDB
InfluxDB是一个开源的、分布式的、允许时间序列数据库 很容易存储度量。 安装和配置很简单,读了更多的细节 InfluxDB文档 。
InfluxDB数据可以很容易地在浏览器中查看 Influga 或 Grafana 。 在这种情况下,我们将使用Grafana。
InfluxDB石墨侦听器配置
使石墨InfluxDB侦听器,编辑文件 / opt / influxdb /共享/ config.toml 或 /usr/local/etc/influxdb.conf , 找到“ input_plugins.graphite ”并设置:
# Configure the graphite api
[input_plugins.graphite]
enabled = true
address = "0.0.0.0" # If not set, is actually set to bind-address.
port = 2003
database = "jmeter" # store graphite data in this database
# udp_enabled = true # enable udp interface on the same port as the tcp interface
为以后的版本InfluxDb(例如0.12),替换 (input_plugins.graphite) 与 [[石墨]]
InfluxDB数据库配置
连接到InfluxDB管理控制台并创建两个数据库:
- grafana:grafana用来存储我们将创建的仪表板
- jmeter:InfluxDB用来存储数据发送到石墨侦听器为每个数据库=“jmeter”配置 元素 influxdb.conf 或config.toml
Grafana配置
安装grafana只是把问题背后的解压包一个Apache HTTP服务器。
读 文档 为更多的细节。 开放 config.js 文件并找到 数据源 这样的元素,和编辑:
datasources: {
influxdb: {
type: 'influxdb',
url: "http://localhost:8086/db/jmeter",
username: 'root',
password: 'root',
},
grafana: {
type: 'influxdb',
url: "http://localhost:8086/db/grafana",
username: 'root',
password: 'root',
grafanaDB: true
},
},
这里的仪表板,您可以获得: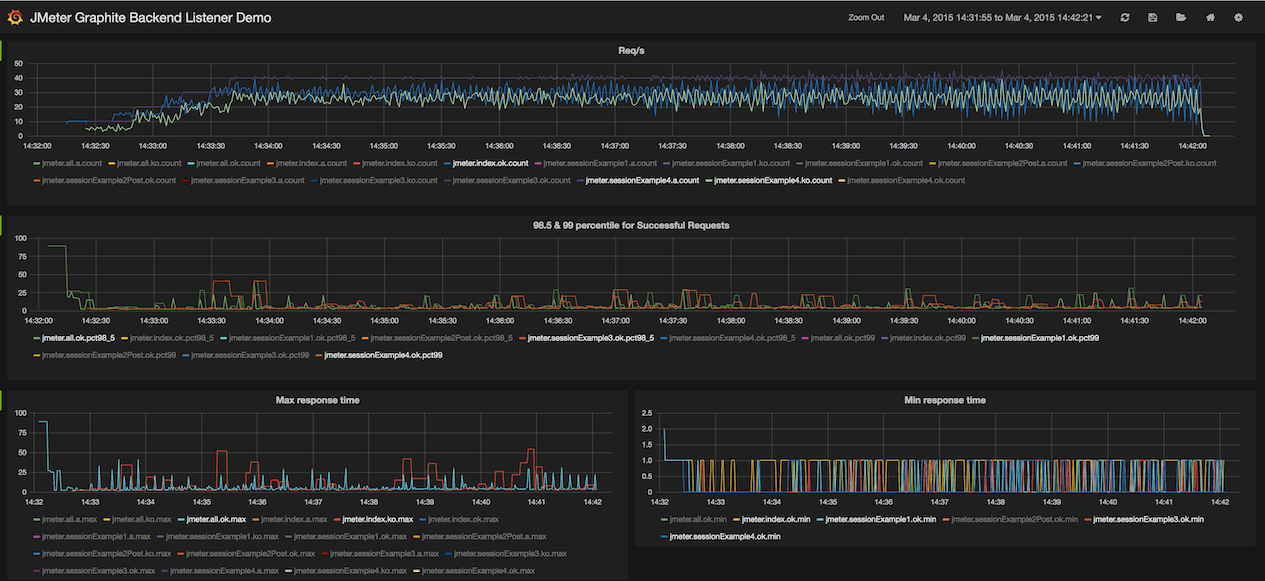 Grafana仪表板
Grafana仪表板
jmeter 实时搜索结果的更多相关文章
- Lucene.net 实现近实时搜索(NRT)和增量索引
Lucene做站内搜索的时候经常会遇到实时搜索的应用场景,比如用户搜索的功能.实现实时搜索,最普通的做法是,添加新的document之后,调用 IndexWriter 的 Commit 方法把内存中的 ...
- Lucene系列-近实时搜索(1)
近实时搜索(near-real-time)可以搜索IndexWriter还未commit的内容,介于immediate和eventual之间,在数据比较大.更新较频繁的情况下使用.本文主要来介绍下如何 ...
- Solr -- 实时搜索
在solr中,实时搜索有3种方案 ①soft commit,这其实是近实时搜索,不能完全实时. ②RealTimeGet,这是实时,但只支持根据文档ID的查询. ③和第一种类似,只是触发softcom ...
- Everything文件名实时搜索||解决局域网文件共享问题
内容概要:Everything中文版下载地址及使用.用Everything轻松解决局域网文件共享问题.Everything语言设置问题 另:Everything只支持NTFS格式的磁盘(工作原理的缘故 ...
- 【jmeter】基于InfluxDB&Grafana的JMeter实时性能测试数据的监控和展示
本文主要讲述如何利用JMeter监听器Backend Listener,配合使用InfluxDB+Grafana展示实时性能测试数据 关于JMeter实时测试数据 JMeter从2.11版本开始,命令 ...
- Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,elasticsearch安装配置及中文分词
http://fuxiaopang.gitbooks.io/learnelasticsearch/content/ (中文) 在Elasticsearch中,文档术语一种类型(type),各种各样的 ...
- lucene4.5近实时搜索
近实时搜索就是他能打开一个IndexWriter快速搜索索引变更的内容,而不必关闭writer,或者向writer提交,这个功能是在2.9版本以后引入的,在以前没有这个功能时,必须调用writer的c ...
- 关于lucene的IndexSearcher单实例,对于索引的实时搜索
Lucene版本:3.0 一般情况下,lucene的IndexSearcher都要写成单实例,因为每次创建IndexSearcher对象的时候,它都需要把索引文件加载进来,如果访问量比较大,而索引也比 ...
- 【Lucene】近实时搜索
近实时搜索:可以使用一个打开的IndexWriter快速搜索索引的变更内容,而不必首先关闭writer,或者向该writer提交:这是2.9版本之后推出的新功能. 代码示例(本例参考<Lucen ...
随机推荐
- 【Linux】linux常用基本命令
Linux中许多常用命令是必须掌握的,这里将我学linux入门时学的一些常用的基本命令分享给大家一下,希望可以帮助你们. 这个是我将鸟哥书上的进行了一下整理的,希望不要涉及到版权问题. 1.显示日 ...
- Python3基础 大于一个数的同时小于一个数
镇场诗:---大梦谁觉,水月中建博客.百千磨难,才知世事无常.---今持佛语,技术无量愿学.愿尽所学,铸一良心博客.------------------------------------------ ...
- [转]Socket send函数和recv函数详解
1.send 函数 int send( SOCKET s, const char FAR *buf, int len, int flags ); 不论是客户还是服务器应用程序都用send函数来向TCP ...
- CUBRID学习笔记 16 元数据支持
简化了很多 ,在sqlserver需要用语句实现的功能 接口如下 public DataTable GetDatabases(string[] filters) public DataTable Ge ...
- STORM_0006_第二个storm_topology:WordCountTopology的代码与运行
我先试试这个Open Live Writer能不能用. 再在ScribeFire中修改一下已经发布的文章试试看. 这两个写博客的地方都没有原始的编辑器方便,可以插入代码,选择文章的分类.所以以后还有这 ...
- table布局注意点
1.同行等高. 2.宽度自动调节(table-layout:fixed;). 3.处理垂直居中又是神器 参考链接: http://www.blueidea.com/tech/web/2008/6257 ...
- 强制性签出被人没有签入的文件(在.net开发vs中)
灵感,是天才的女神.她并不步履蹒跚地走过,而是在空中像乌鸦那么警觉地飞过的,她没有什么剽带给诗人抓握,她的头是一团烈火,她溜得快,像那些白里带红的鹤,教猎人见了无可奈何.——巴尔扎克(上海网站建设) ...
- JZs3c2440学习笔记一
1.连线 串口线usb-com,USB下载线 2.驱动安装 USB-serial, dnw的sec s3c2410x test驱动安装(win7下安装方法搜索:百问网WIN7,64,dnw) 3.烧 ...
- web设计经验<七>13步打造优雅的WEB字体
今天,大多数浏览器已经默认支持Web字体,日趋增多的字体特性被嵌入最新版HTML和CSS标准中,Web字体即将迎来一个趋于复杂的崭新时代.下面是一些基本的关于字体的规则,特别适用于Web字体. 原文地 ...
- 图片的copy,从一个目录复制到另一个目录
代码: public function index(){ $path='G:/相片/2014.9.8深圳莲花山/IMG_1282.JPG'; $path=iconv('utf-8','gb2312', ...