上篇博文中已经谈到,有两个流程没有讲到。一个是MetaTableAccessor.getRegionLocations,另外一个是ConnectionImplementation.cacheLocation。这一节,就让我们单独来介绍这两个流程。
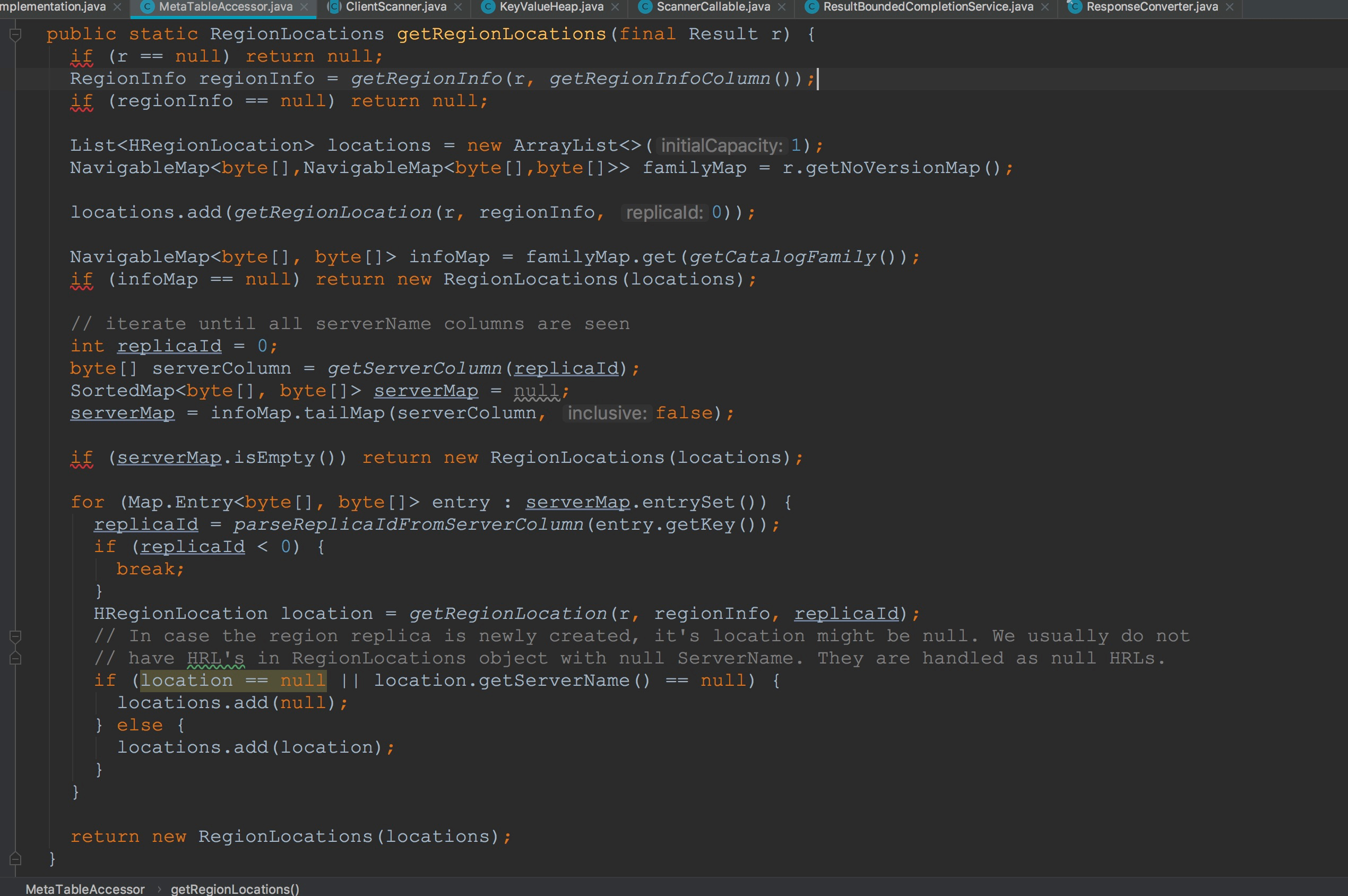
首先让我们来到MetaTableAccessor.getRegionLocations。
1.调用MetaTableAccessor.getRegionInfo,获取返回结果集中指定的列信息(info:regioninfo)的值。在这个方法的调用过程中,有一个知识点需要大家关注——Result.binarySearch。我将放在后面讲解。
2.然后调用了Result.getNoVersionMap。在这里,完成了对返回结果集的含version版本信息的封装与不含version版本信息的封装,同样,我将放在后面讲解。
首先让我们来到Result.binarySearch。大家可以看到这里使用的kvs[0]的rowKey,然后使用了传入的family(info)与qualifier(regioninfo)。大家可能比较迷惑,为什么这里的逻辑是这样的。原因很简单,因为这里传入的Cell数组的rowKey都是一样的,要利用Arrays.binarySearch搜索指定family:qualifier。因此首先使用这些信息构造了一个封装了以上信息的FirstOnRowColCell。这里需要注意的是,新建的cell.getTimestamp返回值为HConstants.LATEST_TIMESTAMP = Long.MAX_VALUE。这里,大家可能会对Arrays.binarySearch的返回值比较新奇,为什么结果是负值包括后面为什么有表达式(pos = (pos+1) * -1)。大家感兴趣的可以追一下源码,我只简单说一下结论。在调用Arrays.binarySearch方法时,如果所要搜索的数组中包含键,则返回键在该数组的位置,然而,如果数组中不包含键,那么就返回-(insertion point) - 1。这里的insertion point就是该数组中第一个元素大于键的索引位置(the index of the first element greater than the key)。如果大家还是不懂,在网上搜一下就明白了,我在这里就不详述了。后面通过表达式(pos = (pos+1) * -1)也就获取的Arrays.binarySearch后的insertion point。看到这里大家可能还有点迷惑,不过,相信我在介绍完CellComparatorImpl后,大家可能就恍然大悟了。

接下来让我们来到CellComparatorImpl.compare方法。这里主要调用了compareRows与compareWithoutRow。compareRows比较简单,就是比较传入Cell的rowKey。真正重要的是compareWithoutRow。

接下来让我们来到CellComparatorImpl.compareWithoutRow方法。这里比较容易误会的是compareTimestamps。
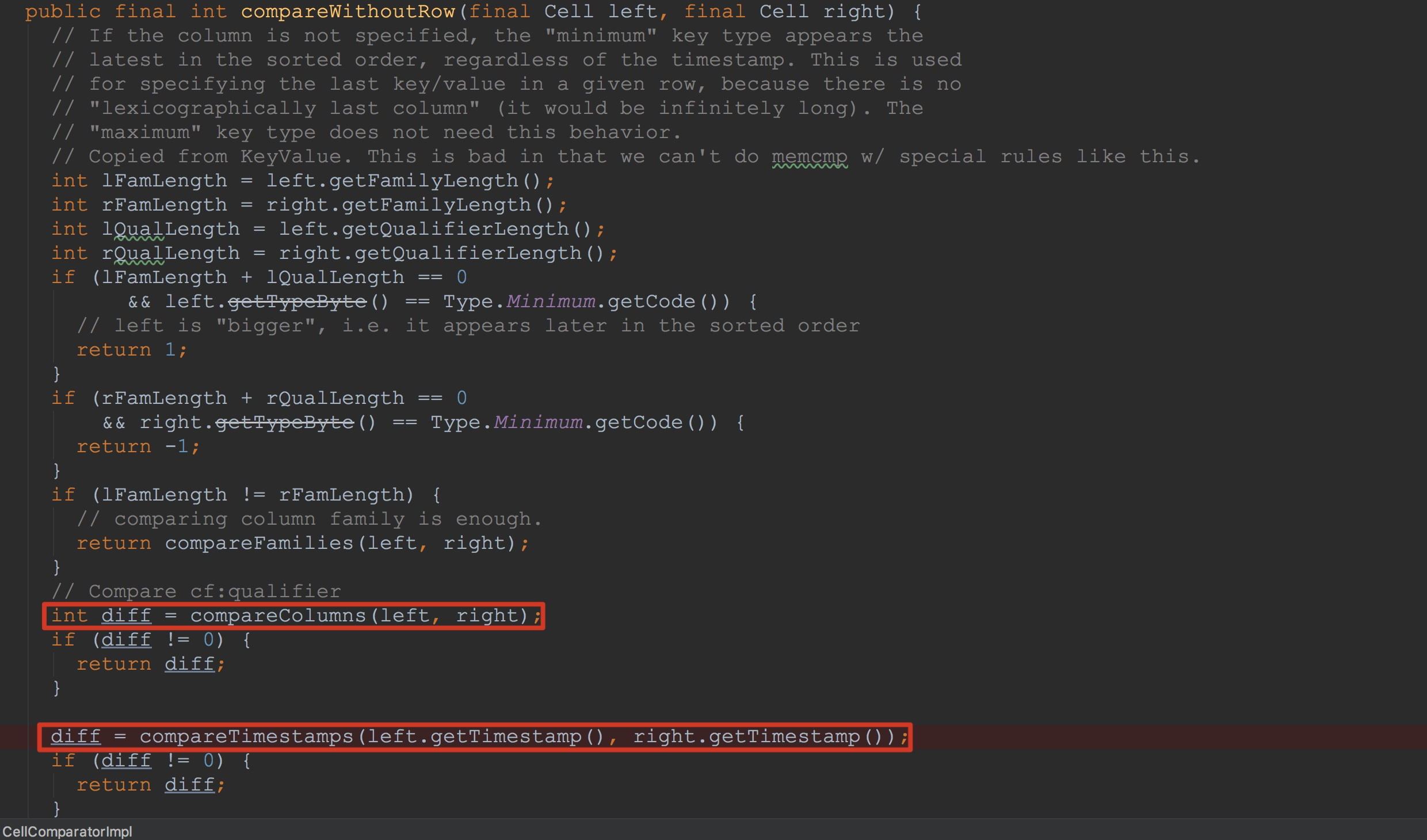
接下来让我们来到CellComparatorImpl.compareTimestamps。正如截图中注释所说,交换顺序以实现将相同的family:qualifier按照时间戳的降序来排列(family与qualifier都是按照升序来排列的)。看到这里,相信大家就能够明白为什么构建的Cell时间戳为Long.MAX_VALUE。
不过,我还是在这里再简单介绍一下。上面我已经提到Arrays.binarySearch中insertion point是该数组中第一个元素大于键的索引位置(the index of the first element greater than the key)。假如,如果说这里的CellComparatorImpl.compareTimestamps为升序排列,那么,上面构造的key的insertion point为数组中相同family:qualifier的index + 1。而这里改为降序之后,构造的key的insertion point为数组中相同family:qualifier的index。而这个结果正是我们需要的。

到这里,大家可能就明白了Result.getColumnLatestCell方法的含义——获取指定family:qualifier中时间戳最接近Long.MAX_VALUE的cell。
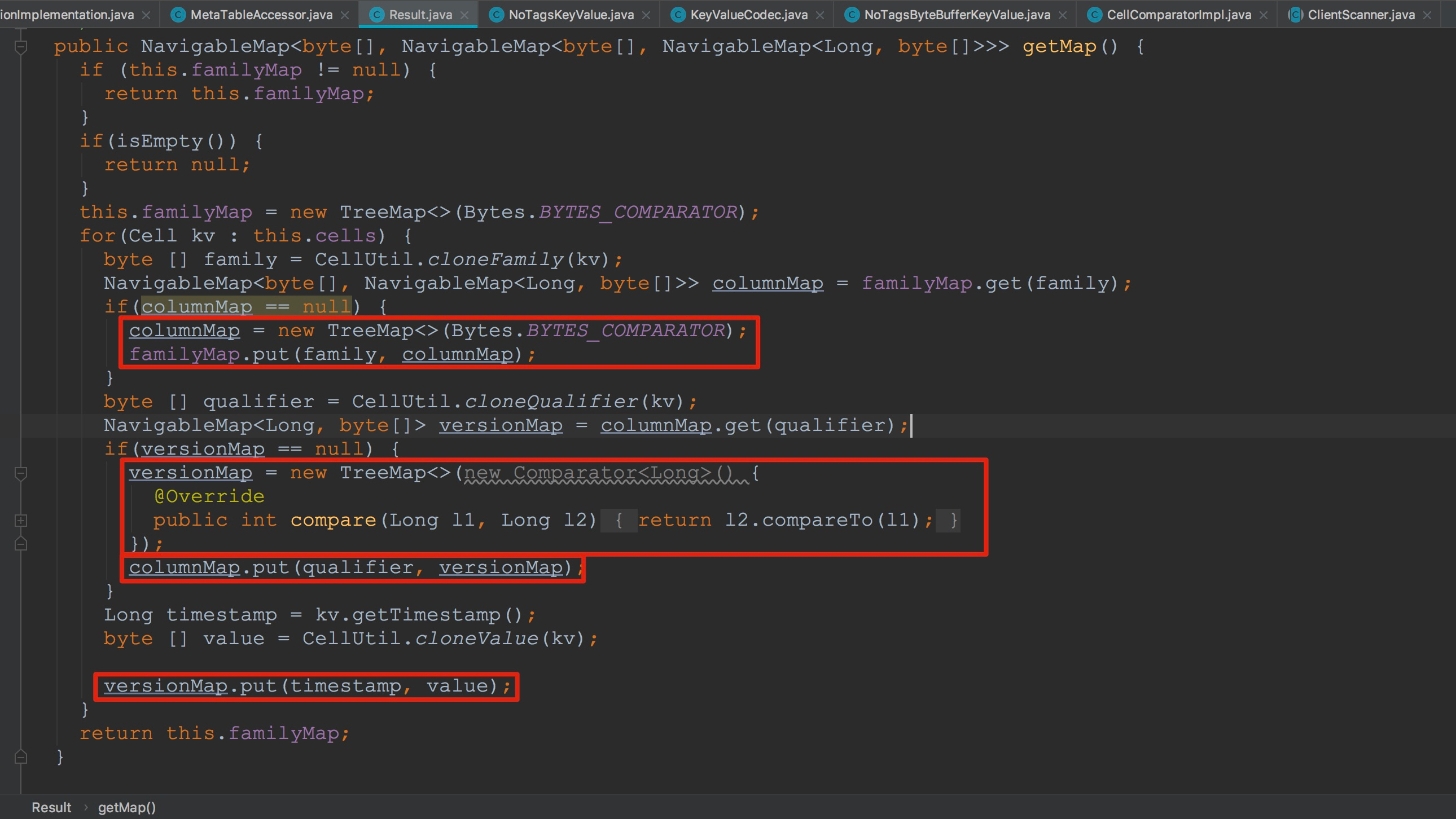
接下来我插入一个知识点——Result.getMap与Result.getNoVersionMap。这里获取的是含version信息的列。通过其中的versionMap.put方法我们就可以知道,这里将不同version的value值保存在map中了。
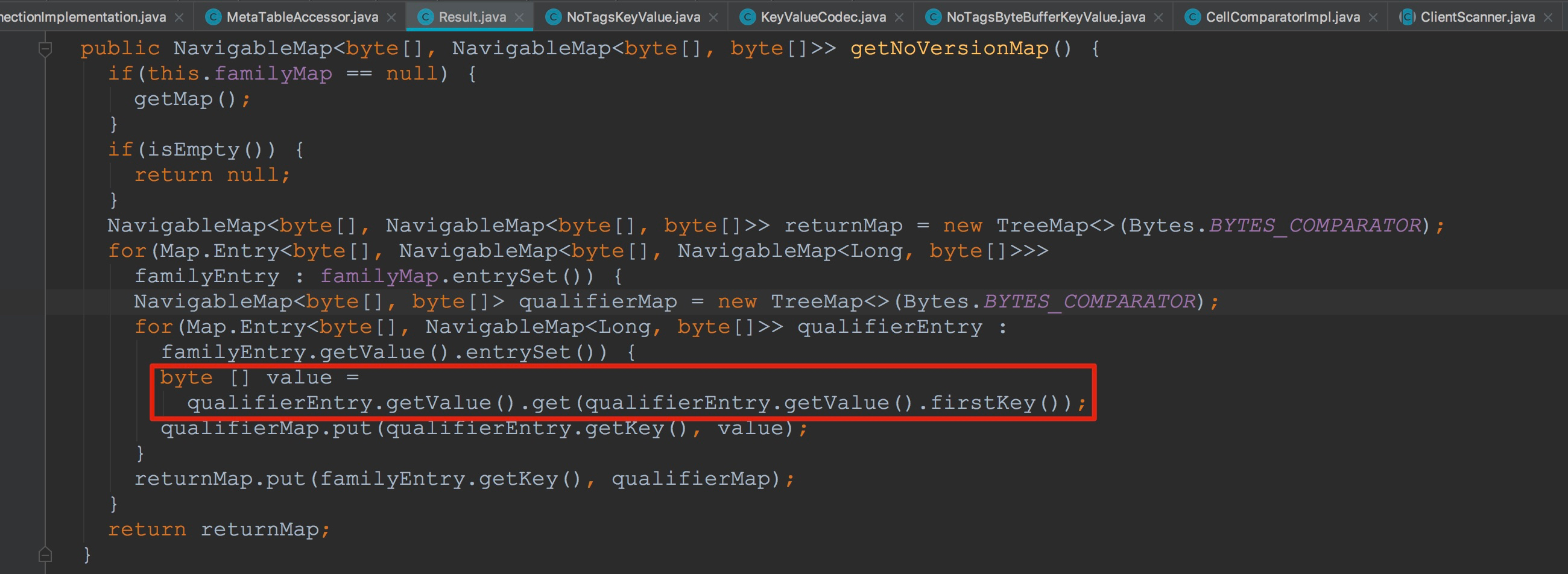
然后来到Result.getNoVersionMap。在这里获取的是不含version的列。由于上面在构造versionMap时传入的Comparator为倒序排序,因此,这里通过qualifierEntry.getValue().firstKey()获得的是最新版本的value。
接下来,让我们来到本节中另外一个也是最后一个重要的方法ConnectionImplementation.cacheLocation。由于其主要调用了MetaCache.getCachedLocation,因此,我在这里贴出MetaCache.getCachedLocation源码,如下图所示。其中比较重要的方法是MetaCache.getTableLocations。

接下来让我们来到MetaCache.getTableLocations,如下图所示。如果看过我的上篇博文《HBase之Table.put客户端流程》,大家可能知道,我埋了一个伏笔,也就是这里的最后一个入参。上一篇中的与这里的入参类型不同,但是方法的调用流程是一样的,我就在这里详细讲解。

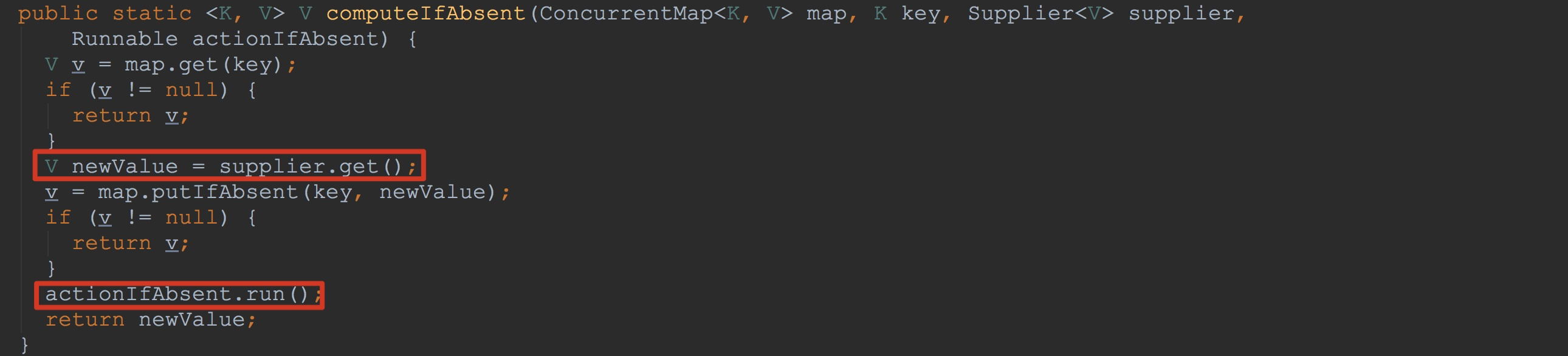
上图中最后一个入参是java.util.function.Supplier。如下图所示。

上图中的最后一个入参类型是Runnable。看到这里,大家可能就明白了。如果在MetaCache.cachedRegionLocations中并没有相应的key,value对,那么就会调用supplier.get方法,也就是getTableLocations的最后一个入参,重新构建一个CopyOnWriteArrayMap,并且将内部的比较器设置为Bytes.BYTES_COMPARATOR。然后将其放到MetaCache.cachedRegionLocations。
到此为止,完整的《HBase之Table.put客户端流程》就结束了。大家如果有什么疑问或者大数据相关的问题可以发送至我的邮箱15935152719@163. com。
从下一节起,也就是本周末,我将为大家带来HBase的第二章内容——Hbase之Client协议。届时,Client协议中的服务端与客户端的完整流程将为大家一一奉上。如果比较关注其中的内容可以关注我,或者成为我的粉丝,都是就可以及时收到更新啦。
- HBase之Table.put客户端流程
首先,让我们从HTable.put方法开始.由于这一节有很多方法只是简单的参数传递,我就简单略过,但是,关键的方法我还是会截图讲解,所以希望大家尽可能对照源码进行流程分析.另外,在这一节,我单单介绍p ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- paip.提升效率--数据绑定到table原理和流程Angular js jquery实现
paip.提升效率--数据绑定到table原理和流程Angular js jquery实现 html #--keyword 1 #---原理和流程 1 #----jq实现的代码 1 #-----An ...
- hbase删除table时,显示table不存在
hbase删除table时,显示table不存在,但是创建table时,显示table存在. 解决方案: 清空zookeeper数据.(重新安装zookeeper)
- Netty 源码学习——客户端流程分析
Netty 源码学习--客户端流程分析 友情提醒: 需要观看者具备一些 NIO 的知识,否则看起来有的地方可能会不明白. 使用版本依赖 <dependency> <groupId&g ...
- HBase介绍(3)---框架结构及流程
HBASE依托于Hadoop的HDFS作为存储基础,因此结构也很类似于Hadoop的Master-Slave模式,Hbase Master Server 负责管理所有的HRegion Server,但 ...
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- Hbase 基础 - shell 与 客户端
版权说明: 本文章版权归本人及博客园共同所有,转载请标明原文出处(http://www.cnblogs.com/mikevictor07/),以下内容为个人理解,仅供参考. 一.简介 Hbase是在 ...
- HBase读写数据的详细流程及ROOT表/META表介绍
一.HBase读数据流程 1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置: 2.Cli ...
随机推荐
- Taro父子组件通信
父组件 testEvent = () =>{ console.log('abc123') } <Test test={1231323} onTestEvent={this.testEven ...
- java文件过滤器的使用
前言: java.io.FileFilter(过滤器接口)boolean accept(File pathname) File类提供了如下方法使用过滤器:public File[] listFiles ...
- typora画图
https://steemit.com/utopian-io/@jubi/typora-typora-tutorial-exquisite-graph https://support.typora.i ...
- SSM项目目录结构
- linux去除\r(window中编辑的文本)
vim -b file 二进制贷款文件:%s/^M//g # 注意这里使用Ctrl+V+M输入^M 上面的方法我就不行,但是下面的可以: 如果不行可以使用 :%s/\r//
- BZOJ 2169
$f_{ij}$ 表示加入 $i$ 条边, $j$ 个点的度数是奇数的方案数,然后暴力 #include<bits/stdc++.h> using namespace std; #defi ...
- nsqadmin
nsqadmin 结构体定义 type Options struct { LogLevel string `flag:"log-level"` LogPrefix string ` ...
- mysql基本命令总结
1.在Ubuntu上安装MYSQL sudo apt-get install mysql-server sudo apt-get install mysql-client 2.安装结束后,用命令验证是 ...
- Java课堂笔记(一):Java基础
本篇博客将对Java中的数据类型.操作符,常量与变量和数组进行介绍.这些内容都是Java中最基本的知识,也是初学Java时最开始就需要了解的东西. Java数据类型 Java是一种强类型的语言,这就意 ...
- thinkphp 单图上传组建成数组然后追加到一个字段
//上传的数组字段 $note1 = input('note1'); $note2 = input('note2'); $note3 = input('note3'); $note4 = input( ...