Random-Forest-Python
1. 近期目标,实现随机森林进行点云分类
1)学习阶段:
Kaggle Machine Learning Competition: Predicting Titanic Survivors
Kaggle Titanic 生存预测 -- 详细流程吐血梳理
https://www.codeproject.com/Articles/1197167/Random-Forest-Python
https://blog.csdn.net/hexingwei/article/details/50740404
2)实践阶段:
(1)原始点云字段(X,Y,Z,density,curvature,Classification),利用点云的高程Z,密度和曲率进行train和分类。分类结果很差就是了。
需要考虑哪些特征对分类结果的影响比较大?用什么样的点云特征更好,特征工程问题?
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 10 10:12:02 2018
@author: yhexie
"""
import numpy as np
import pandas as pd
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier df = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/train_pcloud2.csv', header=0)
x_train = df[['Z','Volume','Ncr']]
y_train = df.Classification df2 = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/test_pcloud2.csv', header=0)
x_test = df2[['Z','Volume','Ncr']] clf = RandomForestClassifier(n_estimators=10)
clf.fit(x_train, y_train)
clf_y_predict = clf.predict(x_test) data_arry=[]
data_arry.append(df2.X)
data_arry.append(df2.Y)
data_arry.append(df2.Z)
data_arry.append(clf_y_predict) np_data = np.array(data_arry)
np_data = np_data.T
np.array(np_data)
save = pd.DataFrame(np_data, columns = ['X','Y','Z','Classification'])
save.to_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/predict_pcloud2.csv',index=False,header=True) #index=False,header=False表示不保存行索引和列标题
(2)对训练集进行split,用75%的数据训练,25%的数据验证模型的拟合精度和泛化能力。
a. 增加定性特征,进行dummy处理。
目前采用Z值和8个特征相关的点云特征进行分类,点云近邻搜索半径2.5m
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 28 10:54:48 2018 @author: yhexie
""" import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier df = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/train_pc.csv', header=0)
x_train = df[['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy',
'EigenEntropy','eig_sum' ,'changeOfcurvature']]
y_train = df.Classification from sklearn.cross_validation import train_test_split
train_data_X,test_data_X,train_data_Y,test_data_Y = train_test_split(x_train, y_train, test_size=0.25, random_state=33) df2 = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/test_pc.csv', header=0)
x_test = df2[['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy',
'EigenEntropy','eig_sum' ,'changeOfcurvature']] clf = RandomForestClassifier(n_estimators=10)
clf.fit(train_data_X, train_data_Y) print('Accuracy on training set:{:.3f}:'.format(clf.score(train_data_X,train_data_Y)))
print('Accuracy on training set:{:.3f}:'.format(clf.score(test_data_X,test_data_Y)))
print('Feature inportances:{}'.format(clf.feature_importances_))
n_features=9
plt.barh(range(n_features),clf.feature_importances_,align='center')
plt.yticks(np.arange(n_features),['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy',
'EigenEntropy','eig_sum' ,'changeOfcurvature'])
plt.xlabel('Feature importance')
plt.ylabel('Feature') clf_y_predict = clf.predict(x_test) data_arry=[]
data_arry.append(df2.X)
data_arry.append(df2.Y)
data_arry.append(df2.Z)
data_arry.append(clf_y_predict) np_data = np.array(data_arry)
np_data = np_data.T
np.array(np_data)
save = pd.DataFrame(np_data, columns = ['X','Y','Z','Classification'])
save.to_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/predict_pcloud2.csv',index=False,header=True) #index=False,header=False表示不保存行索引和列标题
计算结果:可以看到在测试集上的结果还是很差
Accuracy on training set:0.984:
Accuracy on test set:0.776:
特征重要程度:
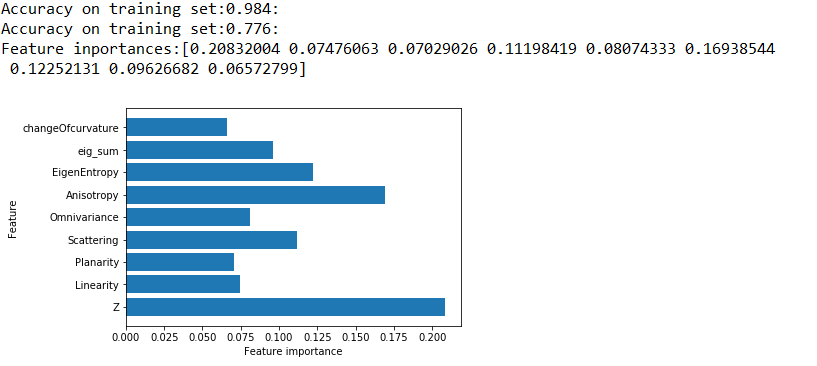
新的测试:
Accuracy on training set:0.994:
Accuracy on training set:0.891:
Feature inportances:[0.02188956 0.02742479 0.10124688 0.01996966 0.1253002 0.02563489
0.03265565 0.100919 0.15808224 0.01937961 0.02727676 0.05498342
0.0211147 0.02387439 0.01900164 0.023478 0.02833916 0.0302441
0.02249598 0.06629199 0.05039737]
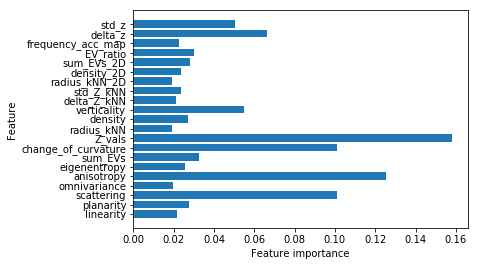

感觉Z值的重要程度太高了。房屋分类结果应该是很差,绿色的很多被错误分类了。
问题:目前训练集中的每个类别的样本数目并不相同,这个对训练结果有没有影响?
Random-Forest-Python的更多相关文章
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- [Machine Learning & Algorithm] 随机森林(Random Forest)
1 什么是随机森林? 作为新兴起的.高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来 ...
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 随机森林(Random Forest)
阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 袋外错误率(oob error) 6 随机森林工作原理解释的一个简单例子 7 随机森林的Pyth ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- [Machine Learning & Algorithm] 随机森林(Random Forest)-转载
作者:Poll的笔记 博客出处:http://www.cnblogs.com/maybe2030/ 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 ...
- 随机森林(Random Forest,简称RF)
阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 袋外错误率(oob error) 6 随机森林工作原理解释的一个简单例子 7 随机森林的Pyth ...
- 随机森林(Random Forest)详解(转)
来源: Poll的笔记 cnblogs.com/maybe2030/p/4585705.html 1 什么是随机森林? 作为新兴起的.高度灵活的一种机器学习算法,随机森林(Random Fores ...
- 随机森林分类器(Random Forest)
阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 袋外错误率(oob error) 6 随机森林工作原理解释的一个简单例子 7 随机森林的Pyth ...
- paper 85:机器统计学习方法——CART, Bagging, Random Forest, Boosting
本文从统计学角度讲解了CART(Classification And Regression Tree), Bagging(bootstrap aggregation), Random Forest B ...
随机推荐
- OrCAD Capture CIS 16.6 从PDF文档中提取引脚定义,实现快速地编辑Part的引脚名称
操作系统:Windows 10 x64 工具1:OrCAD Capture CIS 16.6-S062 (v16-6-112FF) 工具2:Excel 工具3:Solid Converter 打开需要 ...
- 使用CompletionService结合ExecutorService批处理调用存储过程任务实例
此实例为java多线程并发调用存储过程实例,只做代码记载,不做详细描述 1.线程池构造初始化类CommonExecutorService.java package com.pupeiyuan.go; ...
- node爬取html乱码
var http = require('http'), iconv = require('iconv-lite'); http.get("http://website.com/", ...
- Hadoop| YARN| 计数器| 压缩| 调优
1. 计数器应用 2. 数据清洗(ETL) 在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据.清理的过程往往只需要运行Mapper程序,不需要运行Reduc ...
- java中的try-catch-finally异常处理(学习笔记)
一.异常概述 异常:Exception,是在运行发生的不正常情况. 原始异常处理: if(条件) { 处理办法1 处理办法2 处理办法3 } if(条件) { 处理办法4 处理办法5 处理办法6 } ...
- JS对象的拷贝
1:对数据进行备份的时候,如果这个数据是基本的数据类型,那么很好办,通过赋值实现复制即可. 赋值与浅拷贝的区别 var obj1 = { 'name' : 'zhangsan', 'age' : '1 ...
- C# ENUM 字符串输出功能
public enum MeasurementType { Each, [DisplayText("Lineal Metres")] LinealMetre, [DisplayTe ...
- php实现根据字符串生成对应数组的方法
先看看如下示例: <?php $config = array( 'project|page|index' => 'content', 'project|page|nav' => ar ...
- jquery for循环判断是否重复
//使用for循环 判断是否有重名 var len=$("li").length;//获取页面中所有li的数量 for(var i=0; i<len; i++){ oldna ...
- [LeetCode] Generate Random Point in a Circle 生成圆中的随机点
Given the radius and x-y positions of the center of a circle, write a function randPoint which gener ...