hive的join
第一:在map端产生join
- set hive.auto.convert.join=true;
这样设置,hive就会自动的识别比较小的表,继而用mapJoin来实现两个表的联合。看看下面的两个表格的连接。这里的dept相对来讲是比较小的。我们看看会发生什么,如图所示:

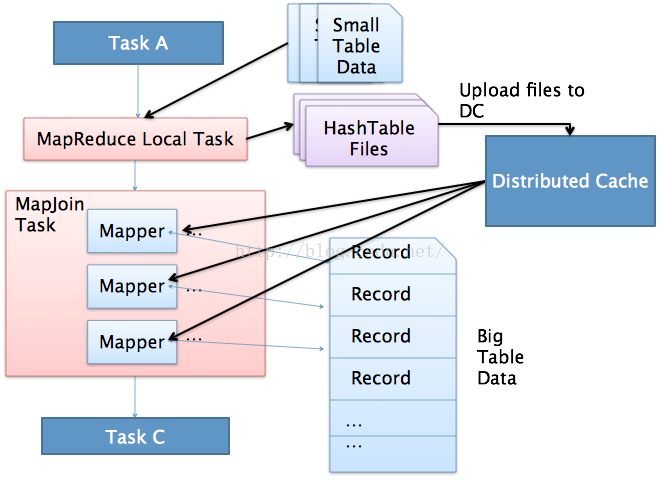
第二:common join

- set hive.auto.convert.sortmerge.join=true;
- set hive.optimize.bucketmapjoin = true;
- set hive.optimize.bucketmapjoin.sortedmerge = true;
- set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- create table emp_info_bucket(ename string,deptno int)
- partitioned by (empno string)
- clustered by(deptno) into 4 buckets;
- insert overwrite table emp_info_bucket
- partition (empno=7369)
- select ename ,deptno from emp
- create table dept_info_bucket(deptno string,dname string,loc string)
- clustered by (deptno) into 4 buckets;
- insert overwrite table dept_info_bucket
- select * from dept;
- select * from emp_info_bucket emp join dept_info_bucket dept
- on(emp.deptno==dept.deptno);//正常的情况下,应该是启动smbjoin的但是这里的数据量太小啦,还是启动了mapjoin
hive的join的更多相关文章
- HIVE: Map Join Vs Common Join, and SMB
HIVE Map Join is nothing but the extended version of Hash Join of SQL Server - just extending Hash ...
- hive:join操作
hive的多表连接,都会转换成多个MR job,每一个MR job在hive中均称为Join阶段.按照join程序最后一个表应该尽量是大表,因为join前一阶段生成的数据会存在于Reducer 的bu ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Hive的join表连接查询的一些注意事项
Hive支持的表连接查询的语法: join_table: table_reference JOIN table_factor [join_condition] | table_reference {L ...
- hive的join查询
hive的join查询 语法 join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_refere ...
- Hive 中Join的专题---Join详解
1.什么是等值连接? 2.hive转换多表join时,如果每个表在join字句中,使用的都是同一个列,该如何处理? 3.LEFT,RIGHT,FULL OUTER连接的作用是什么? 4.LEFT或RI ...
- Hive中Join的类型和用法
关键字:Hive Join.Hive LEFT|RIGTH|FULL OUTER JOIN.Hive LEFT SEMI JOIN.Hive Cross Join Hive中除了支持和传统数据库中一样 ...
- Hive 基本语法操练(五):Hive 的 JOIN 用法
Hive 的 JOIN 用法 hive只支持等连接,外连接,左半连接.hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce中实现这 ...
- hive的join优化
“国际大学生节”又称“世界大学生节”.“世界学生日”.“国际学生日”.1946年,世界各国学生代表于布拉格召开全世界学生大会,宣布把每年的11月17日定为“世界大学生节”,以加强全世界大学生的团结和友 ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
随机推荐
- The Ethereum devp2p and discv4 protocol Part II
描述 本文章主上下两篇 上篇:讲述以太坊devp2p与disc4节点发现协议 下篇:实践篇,实现如何获取以太坊所有节点信息(ip,port,nodeId,client) 正文 本片为下篇:实践篇,主要 ...
- SpringBoot 上传文件夹
前端代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- goland 文件头自动注释
1 代码 /** * @Author: ${USER} * @Description: * @File: ${NAME} * @Version: 1.0.0 * @Date: ${DATE} ${TI ...
- python基础--absl.flags
之前在tensorflow的mnist例程中看到了使用 absl.flags的方法来载入和解析参数的,出于学习的目的,就自己试验了一下, 代码如下: # *_*coding:utf-8 *_* # a ...
- 先进过程控制之一:浅说APC
先进过程控制(APC)技术作为在生产装置级的信息化应用,在优化装置的控制水平和提高生产过程的管理水平的同时,还为企业创造了可观的经济效益. 1.什么是APC 先进过程控制,简称APC,并不是什么新概念 ...
- C语言中return 0和return 1和return -1
转载声明:本文系转载文章 原文作者:十一月zz 原文地址:https://blog.csdn.net/baidu_35679960/article/details/77542787 1.返回值int ...
- Scyther 论文相关资料整理
1.Scyther 的特点使用方法 Scyther可以提供轨迹的简单描述,方便分析协议可能出现的攻击和表现,使用Athena算法,该软件表现如下特点: 该软件有明确的终止,能工提供无限会话协议安全性的 ...
- 解决 DBMS_AW_EXP: BIN$*****==$0 not AW$
在Oracle 11.2.0.4 版本的数据库中,使用数据泵导出数据时,有可能会遇到这样的提示: 示例1 Connected to: Oracle Database 11g Enterprise Ed ...
- spring boot 集成axis1.4 java.lang.NoClassDefFoundError: Could not initialize class org.apache.axis.client.AxisClient
pom配置: <dependencies> <dependency> <groupId>org.springframework.boot</groupId&g ...
- thinkphp5简单使用redis缓存
<?php namespace app\index\controller; use think\Controller; use think\Cache\Driver\Redis; class I ...