使用scrapy爬虫,爬取17k小说网的案例-方法二
楼主准备爬取此页面的小说,此页面一共有125章
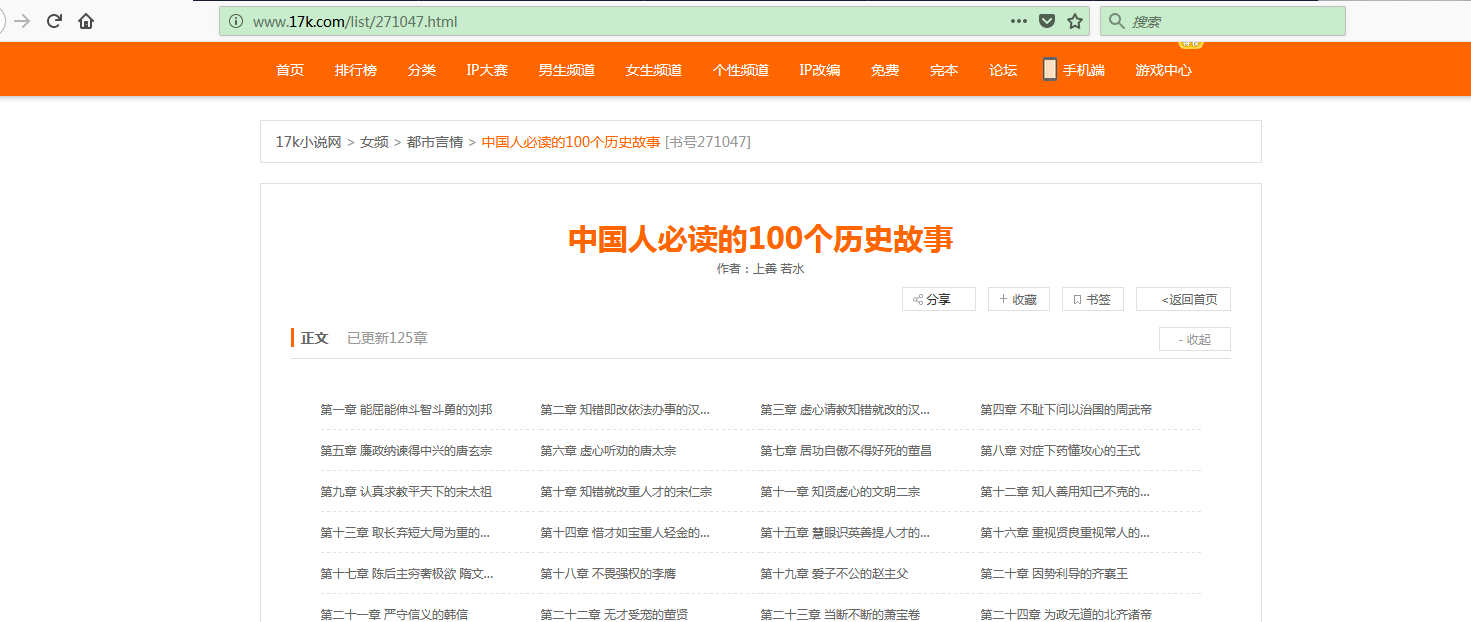
我们点击进去第一章和第一百二十五章发现了一个规律
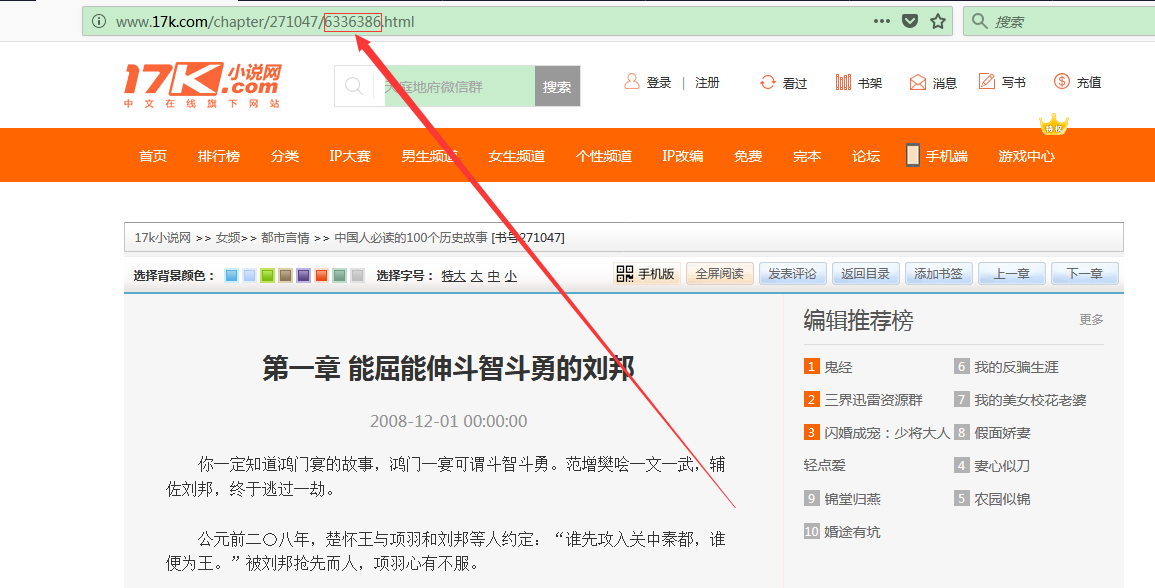
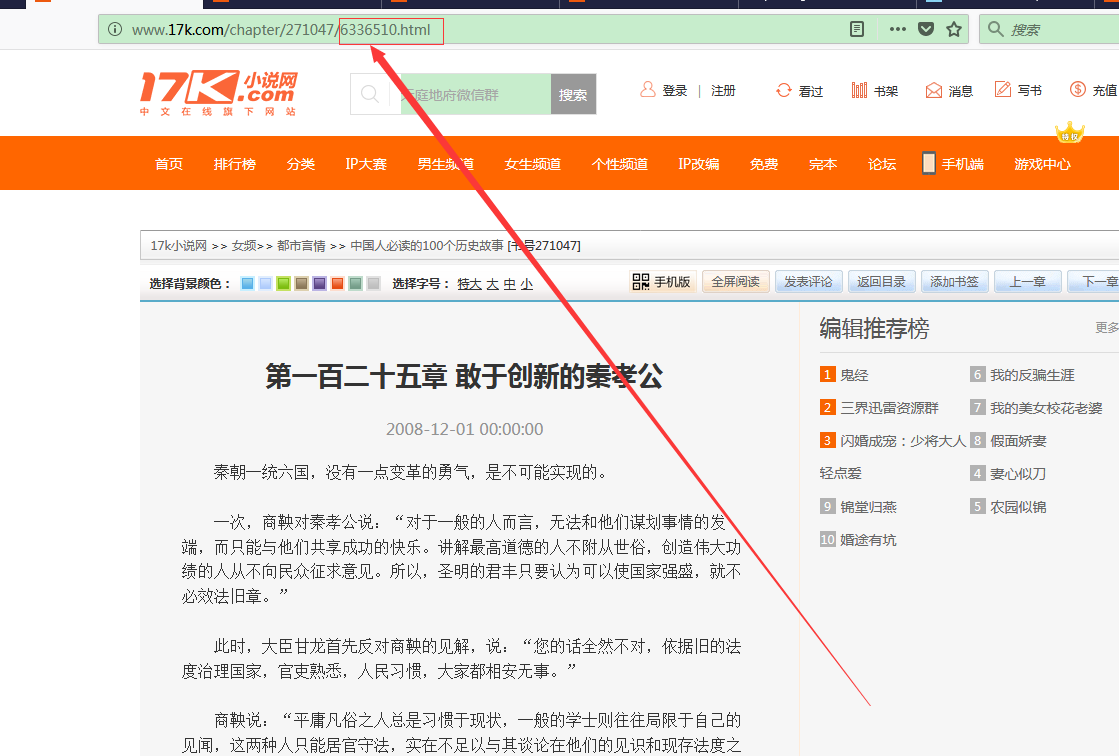
我们看到此链接的 http://www.17k.com/chapter/271047/6336386.html ->http://www.17k.com/chapter/271047/6336510.html
6336386依次递增到6336510 我们根据此灵感 得到下面的spiders核心的代码
# -*- coding: utf-8 -*-
import scrapy
from k17.items import K17Item
import json
class A17kSpider(scrapy.Spider):
name = '17k' allowed_domains = ['17k.com']
start_urls = ['http://www.17k.com/chapter/271047/6336386.html']
def parse(self, response):
for i in range(6336386, 6336510 + 1):
new_url="http://www.17k.com/chapter/271047/"+str(i)+".html"
yield scrapy.Request(new_url, callback=self.next_parse)
def next_parse(self,response):
for bb in response.xpath('//div[@class="readArea"]/div[@class="readAreaBox content"]'):
item=K17Item()
title=bb.xpath("h1/text()").extract()
new_title=(''.join(title).replace('\n','')).strip()
item['title']=new_title
dec= bb.xpath("div[@class='p']/text()").extract()
dec_new=((''.join(dec).replace('\n','')).replace('\u3000','')).strip() ###去除内容中的\n 和\u3000和空格的问题
item['describe'] = dec_new yield item
我们在pipelines.py最后得到最终结果
import json
class K17Pipeline(object):
def process_item(self, item, spider):
return item
#初始化时指定要操作的文件
def __init__(self):
self.file = open('item.json', 'w', encoding='utf-8')
# 存储数据,将 Item 实例作为 json 数据写入到文件中
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(lines)
return item
# 处理结束后关闭 文件 IO 流
def close_spider(self, spider):
self.file.close()

使用scrapy爬虫,爬取17k小说网的案例-方法二的更多相关文章
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- 使用scrapy爬虫,爬取起点小说网的案例
爬取的页面为https://book.qidian.com/info/1010734492#Catalog 爬取的小说为凡人修仙之仙界篇,这边小说很不错. 正文的章节如下图所示 其中下面的章节为加密部 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
随机推荐
- HTTP的一些基本概念
HTTP协议:HTTP(超文本传输协议)协议就是计算机在网络中进行通信所必须共同遵守的规则,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器,我们目前使用的是HTTP/1.1 ...
- [题解] Codeforces Round #549 (Div. 2) B. Nirvana
Codeforces Round #549 (Div. 2) B. Nirvana [题目描述] B. Nirvana time limit per test1 second memory limit ...
- vue路由传对象刷新会报错,数据丢失,用json字符串解决
变成json字符串,且加密 this.$router.push({name: response.body.PowerList[0].opPowerurl ,query :{ all: encodeUR ...
- 《为大量出现的KPI流快速部署异常检测模型》 笔记
以下我为这篇<Rapid Deployment of Anomaly Detection Models for Large Number of Emerging KPI Streams>做 ...
- 时间通用类 datetime
/// <summary> /// 时间通用类 /// </summary> public class DateTimeGeneral { /// <summary> ...
- codeforces8A
Train and Peter CodeForces - 8A Peter likes to travel by train. He likes it so much that on the trai ...
- 最长公共子序列(POJ1458)
给出两个字符串,求出这样的一个最长的公共子序列的长度:子序列中的每个字符都能在两个原串中找到,而且每个字符的先后顺序和原串中的先后顺序一致. Sample Input: abcfbc abfcabpr ...
- 对于CAN ID的理解
本文主要讲的是自己对于CAN ID的理解,希望对需要的人有帮助,本文以通俗的方式来理解,不涉及到具体CAN通信. 在接触CAN之前,应该接触过IIC通信,在IIC通信中,在同一条IIC通信总线上每个d ...
- 集合源码分析[1]-Collection 源码分析
目录 Collection 1. 介绍 2. 继承关系 3. 方法 4. JDK8新增的方法 removeIf(Predicate<? super E> filter) Spliterat ...
- 自定义select标签箭头样式
select::-ms-expand{ display: none; }//ie样式清除 select{ appearance:none; -moz-appearance:none; -webkit- ...