klearn.preprocessing.PolynomialFeatures学习
多项式特征处理
class sklearn.preprocessing.PolynomialFeatures(degree=2, interaction_only=False, include_bias=True)
参数:
degree
interaction_only 默认为False
include_bias 表示生成0指数项
| Parameters: |
|
|---|
案例1:
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
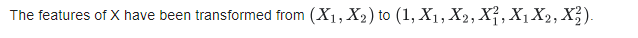
interaction_only=True
>>> X = np.arange(9).reshape(3, 3)
>>> X
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> poly = PolynomialFeatures(degree=3, interaction_only=True)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 2., 0., 0., 2., 0.],
[ 1., 3., 4., 5., 12., 15., 20., 60.],
[ 1., 6., 7., 8., 42., 48., 56., 336.]])
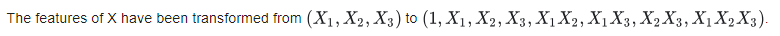
方法:
fit(X[, y]) Compute number of output features.
fit_transform(X[, y]) Fit to data, then transform it.
get_feature_names([input_features]) Return feature names for output features
get_params([deep]) Get parameters for this estimator.
set_params(**params) Set the parameters of this estimator.
transform(X) Transform data to polynomial features
klearn.preprocessing.PolynomialFeatures学习的更多相关文章
- 2.2sklearn.preprocessing.PolynomialFeatures生成交叉特征
sklearn.preprocessing.PolynomialFeatures原文 多项式生成函数:sklearn.preprocessing.PolynomialFeatures(degree=2 ...
- Scikit-Learn模块学习笔记——数据预处理模块preprocessing
preprocessing 模块提供了数据预处理函数和预处理类,预处理类主要是为了方便添加到 pipeline 过程中. 数据标准化 标准化预处理函数: preprocessing.scale(X, ...
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- sklearn 的 PolynomialFeatures 的用法
官方文档:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html ...
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- 使用sklearn进行数据挖掘
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 人工智能(Machine Learning)—— 机器学习
https://blog.csdn.net/luyao_cxy/article/details/82383091 转载:https://blog.csdn.net/qq_27297393/articl ...
- scikit-learn API
scikit-learn API 这是scikit-learn的类和函数参考.有关详细信息,请参阅完整的用户指南,因为类和功能原始规格可能不足以提供有关其用途的完整指南. sklearn.base:基 ...
随机推荐
- spl_autoload_register()怎样注册多个自动加载函数?
<?php /*function __autoload($class){ require("./class/".$class.".php"); }*/ f ...
- centos值cron-计划任务
一.crond简介 crond是Linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具.并且会自动启动cro ...
- Flask插件wtforms、Flask文件上传和Echarts柱状图
一.wtforms 类比Django的Form组件Form组件的主要应用是帮助我们自动生成HTML代码和做一些表单数据的验证 flask的wtforms用法跟Form组件大同小异参考文章:https: ...
- 洛谷P1262间谍网络
题目 我们首先考虑该题没有环应该怎么做,因为没有环所以是一个DAG,因此直接加上入度为0的罪犯,而有环则可以缩点,之后就成为了DAG,然后用一方法做就好了. \(Code\) #include < ...
- 【XSY3139】预言家 数位DP NFA
题目描述 有一个定义在 \(\{0,1,2,3,4,5,6,7,8,9\}\) 上的合规表达式,包含三种基本的操作: 结合:\(E_1E_2\) 分配:\((E_1|E_2|\ldots|E_n),n ...
- Django 框架基础
Python web框架 本质 收发socket消息 --> 按照HTTP协议消息格式去解析消息 路径和要执行的函数的对应关系 --> 主要的业务逻辑 字符串替换 --> 模板(特殊 ...
- <数据结构基础学习>(二)简单的时间复杂度分析
一.简单的复杂度分析 O(1) O(n) O(logn) O(logn) O(n^2) 大O描述的是算法的运行事件和输入数据之间的关系 Eg: 数组求和 public static int sum(i ...
- 栈&队列
队列部分 普通队列 举个形象的例子:排队买票. 有一列人在排队买票,前面来的人买完票就离开,后面来的人需要站在最后--依次类推. 在计算机中,数据结构队列有一个头指针和尾指针,头指针加一就代表有一个数 ...
- SQL---mysql新增字段
) DEFAULT NULL COMMENT '姓名' 修改表 people 增加字段 name 长度100 默认为null 备注:姓名
- redis源码解析(1):redisObject对象说明
Redis在实现键值对数据库时,并没有直接使用数据结构,而是基于已有的数据结构创建了一个对象系统,每种对象至少包含一种数据结构. redis3.0 中对象结构: typedef struct redi ...