ML.NET技术研究系列-2聚类算法KMeans
上一篇博文我们介绍了ML.NET 的入门:
本文我们继续,研究分享一下聚类算法k-means.
一、k-means算法简介
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。
1. k-means算法的原理是什么样的?参考:https://baijiahao.baidu.com/s?id=1622412414004300046&wfr=spider&for=pc
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。
k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。
数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。算法详细的流程描述如下:

2. k-means算法的优缺点:
优点: 算法简单易实现;
缺点: 需要用户事先指定类簇个数; 聚类结果对初始类簇中心的选取较为敏感; 容易陷入局部最优; 只能发现球形类簇;
接下来我们说一下k-means算法的经典应用场景:鸢尾花
二、鸢尾花
首先,鸢尾花是一种植物,有四个典型的属性:
- 花瓣长度
- 花瓣宽度
- 花萼长度
- 花萼宽度

鸢尾花有三大品种setosa、versicolor 或 virginica ,每个品种对应的以上四个属性各不相同。
鸢尾花数据集中一共包含了150条记录,每个样本的包含它的萼片长度和宽度,花瓣的长度和宽度以及这个样本所属的具体品种。每个品种的样本量为50条。
鸢尾花样本数据格式:
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
上述数据中,第一列是鸢尾花花萼长度,第二列是鸢尾花花萼宽度,第三列是鸢尾花花瓣长度,第四列是鸢尾花花瓣宽度。
基于上述数据做机器学习、训练,形成一个模型。
三、ML.NET k-means
基于上述的场景,我们先准备样本数据,https://github.com/dotnet/machinelearning/blob/master/test/data/iris.data
另存为iris.data文件,每个属性逗号间隔。
然后,大致梳理了一下实现步骤:
- 新建一个.Net Core Console Project
- 添加Microsoft.ML nuget 1.2.0版本
- 添加鸢尾花数据、预测类实体类IrisData、ClusterPrediction
- 构造MLContext、从iris.data构造IDataView,采用Trainers.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
- 输入一个测试数据,进行预测。
好,让我们开始搞吧:
1. 新建一个.Net Core Console Project
先看下用的VS的版本:

新建一个.Net Core Console的Project KMeansDemo
2. 添加Microsoft.ML nuget 1.2.0版本

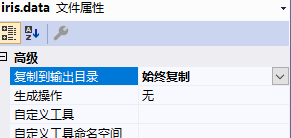
将iris.data文件放到Project下的Data目录中,同时右键iris.data,设置为:始终复制

3. 添加鸢尾花数据、预测类实体类IrisData、ClusterPrediction
using System;
using System.Collections.Generic;
using System.Text; namespace KMeansDemo
{
using Microsoft.ML.Data; /// <summary>
/// 鸢尾花数据
/// </summary>
class IrisData
{
/// <summary>
/// 鸢尾花花萼长度
/// </summary>
[LoadColumn(0)]
public float SepalLength; /// <summary>
/// 鸢尾花花萼宽度
/// </summary>
[LoadColumn(1)]
public float SepalWidth; /// <summary>
/// 鸢尾花花瓣长度
/// </summary>
[LoadColumn(2)]
public float PetalLength; /// <summary>
/// 鸢尾花花瓣宽度
/// </summary>
[LoadColumn(3)]
public float PetalWidth;
}
}
using System;
using System.Collections.Generic;
using System.Text; namespace KMeansDemo
{
using Microsoft.ML.Data; public class ClusterPrediction
{
/// <summary>
/// 预测的族群
/// </summary>
[ColumnName("PredictedLabel")]
public uint PredictedClusterId; [ColumnName("Score")]
public float[] Distances;
}
}
4. 构造MLContext、从iris.data构造IDataView,采用Trainers.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
在Main函数中,开始编码 ,首先添加引用
using Microsoft.ML;
声明样本数据文件和模型文件的文件路径
static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "iris.data");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "IrisClusteringModel.zip");
构造MLContext、IDataView,采用Trainer.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
var mlContext = new MLContext(seed: 0);
IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ',');
string featuresColumnName = "Features";
var pipeline = mlContext.Transforms
.Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, numberOfClusters: 3));
var model = pipeline.Fit(dataView);
using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
{
mlContext.Model.Save(model, dataView.Schema, fileStream);
}
Console.WriteLine("完成模型训练!");
Console.WriteLine("模型文件:"+ _modelPath);
5. 输入一个测试数据,进行预测。
输入一个测试数据,使用生成的模型,进行预测:
var predictor = mlContext.Model.CreatePredictionEngine<IrisData, ClusterPrediction>(model);
var Setosa = new IrisData
{
SepalLength = 5.1f,
SepalWidth = 3.5f,
PetalLength = 1.4f,
PetalWidth = 0.2f
}; var prediction = predictor.Predict(Setosa);
Console.WriteLine($"Cluster: {prediction.PredictedClusterId}");
Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}");
Console.WriteLine("Press any key!");
全部的代码:
using Microsoft.ML;
using System;
using System.IO; namespace KMeansDemo
{
class Program
{
static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "iris.data");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "IrisClusteringModel.zip"); static void Main(string[] args)
{
var mlContext = new MLContext(seed: );
IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ',');
string featuresColumnName = "Features";
var pipeline = mlContext.Transforms
.Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, numberOfClusters: ));
var model = pipeline.Fit(dataView);
using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
{
mlContext.Model.Save(model, dataView.Schema, fileStream);
}
Console.WriteLine("完成模型训练!");
Console.WriteLine("模型文件:"+ _modelPath); //预测
var predictor = mlContext.Model.CreatePredictionEngine<IrisData, ClusterPrediction>(model); var Setosa = new IrisData
{
SepalLength = 5.1f,
SepalWidth = 3.5f,
PetalLength = 1.4f,
PetalWidth = 0.2f
}; var prediction = predictor.Predict(Setosa);
Console.WriteLine($"Cluster: {prediction.PredictedClusterId}");
Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}");
Console.WriteLine("Press any key!");
}
}
}
Run,看一下输出:

以上就是通过ML.NET 的KMeans算法,实现聚类。
上面的数据是一个监督学习的样本,同时是一个数值类型的数据,比较好奇的是,能不能对文本数据+值数据进行聚类,下一篇,我们将继续完成文本数据+值数据的聚类分析。
以上,分享给大家。
周国庆
2019/7/14
ML.NET技术研究系列-2聚类算法KMeans的更多相关文章
- ML.NET技术研究系列1-入门篇
近期团队在研究机器学习,希望通过机器学习实现补丁发布评估,系统异常检测.业务场景归纳一下: 收集整理数据(发布相关的异常日志.告警数据),标识出补丁发布情况(成功.失败) 选择一个机器学习的Model ...
- Nginx技术研究系列5-动态路由升级版
前几篇文章我们介绍了Nginx的配置.OpenResty安装配置.基于Redis的动态路由以及Nginx的监控. Nginx-OpenResty安装配置 Nginx配置详解 Nginx技术研究系列1- ...
- Azure IoT 技术研究系列2-起步示例之设备注册到Azure IoT Hub
上篇博文中,我们主要介绍了Azure IoT Hub的基本概念.架构.特性: Azure IoT 技术研究系列1-入门篇 本文中,我们继续深入研究,做一个起步示例程序:模拟设备注册到Azure IoT ...
- Azure IoT 技术研究系列3-设备到云、云到设备通信
上篇博文中我们将模拟设备注册到Azure IoT Hub中:我们得到了设备的唯一标识. Azure IoT 技术研究系列2-设备注册到Azure IoT Hub 本文中我们继续深入研究,设备到云.云到 ...
- Azure IoT 技术研究系列4-Azure IoT Hub的配额及缩放级别
上两篇博文中,我们介绍了将设备注册到Azure IoT Hub,设备到云.云到设备之间的通信: Azure IoT 技术研究系列2-设备注册到Azure IoT Hub Azure IoT 技术研究系 ...
- Azure IoT 技术研究系列5-Azure IoT Hub与Event Hub比较
上篇博文中,我们介绍了Azure IoT Hub的使用配额和缩放级别: Azure IoT 技术研究系列4-Azure IoT Hub的配额及缩放级别 本文中,我们比较一下Azure IoT Hub和 ...
- Azure Event Hub 技术研究系列2-发送事件到Event Hub
上篇博文中,我们介绍了Azure Event Hub的一些基本概念和架构: Azure Event Hub 技术研究系列1-Event Hub入门篇 本篇文章中,我们继续深入研究,了解Azure Ev ...
- Azure Event Hub 技术研究系列3-Event Hub接收事件
上篇博文中,我们通过编程的方式介绍了如何将事件消息发送到Azure Event Hub: Azure Event Hub 技术研究系列2-发送事件到Event Hub 本篇文章中,我们继续:从Even ...
- Ngnix技术研究系列2-基于Redis实现动态路由
上篇博文我们写了个引子: Ngnix技术研究系列1-通过应用场景看Nginx的反向代理 发现了新大陆,OpenResty OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台 ...
随机推荐
- c#中的GetUpperBound,GetLowerBound方法
今天使用数组的时候,用到了几个数组的属性,总结如下: Array的Rank 属性:语法:public int Rank { get; } 得到Array的秩(维数).Array的GetUpperBou ...
- linux的自动化操作相关使用方法汇总 专题
Crontab中的除号(slash)到底怎么用? crontab 是Linux中配置定时任务的工具,在各种配置中,我们经常会看到除号(Slash)的使用,那么这个除号到底标示什么意思,使用中有哪些需要 ...
- 快速搭建多线程Windows服务解决方案
一.引言 在软件开发过程中windows服务有的时候非常有用,用于同步数据,发送邮件,宿主WF引擎服务等,但是快速搭建一个好用多线程进行多任务处理的程序往往是一个项目必须考虑的问题.自己在项目中也经常 ...
- CSS3 GENERATOR可以同时为一个元素完成border-radius、box-shadow、gradient和opacity多项属性的设置
CSS3 GENERATOR可以同时为一个元素完成border-radius.box-shadow.gradient和opacity多项属性的设置 CSS3 GENERATOR 彩蛋爆料直击现场 CS ...
- Codlility---MinPerimeterRectangle
Task description An integer N is given, representing the area of some rectangle. The area of a recta ...
- 创建服务消费者(Feign)
概述 Feign 是一个声明式的伪 Http 客户端,它使得写 Http 客户端变得更简单.使用 Feign,只需要创建一个接口并注解.它具有可插拔的注解特性,可使用 Feign 注解和 JAX-RS ...
- Spring Boot从入门到实战:集成AOPLog来记录接口访问日志
日志是一个Web项目中必不可少的部分,借助它我们可以做许多事情,比如问题排查.访问统计.监控告警等.一般通过引入slf4j的一些实现框架来做日志功能,如log4j,logback,log4j2,其性能 ...
- nvm淘宝源升级安装最新稳定版nodejs
为了在服务器上面升级nodejs,用nvm下载实在太慢了,推荐淘宝源安装命令,非常快能安装好: 第一步: NVM_NODEJS_ORG_MIRROR=https://npm.taobao.org/mi ...
- CS代码代写, 程序代写, java代写, python代写, c/c++代写,csdaixie,daixie,作业代写,代写
互联网一线工程师程序代写 微信联系 当天完成特色: 互联网一线工程师 24-48小时完成.用心代写/辅导/帮助客户CS作业. 客户反馈与评价 服务质量:保证honor code,代码原创.参考课程sl ...
- 死磕 java同步系列之CyclicBarrier源码解析——有图有真相
问题 (1)CyclicBarrier是什么? (2)CyclicBarrier具有什么特性? (3)CyclicBarrier与CountDownLatch的对比? 简介 CyclicBarrier ...