ubuntu16.04上Eclipse和hadoop配置
1.安装Eclipse
1》下载Eclipse
可以以多种方式下载Eclipse,下面介绍直接从eplise官网下载和从中国镜像站点下载,下载把eclipse上传到Hadoop环境中。
第一种方式从elipse官网下载:
http://www.eclipse.org/downloads/?osType=linux
我们运行的环境为CentOS 64位系统,需要选择eclipse类型为linux,然后点击linux 64bit链接下载
会根据用户所在地,推荐最佳的下载地址
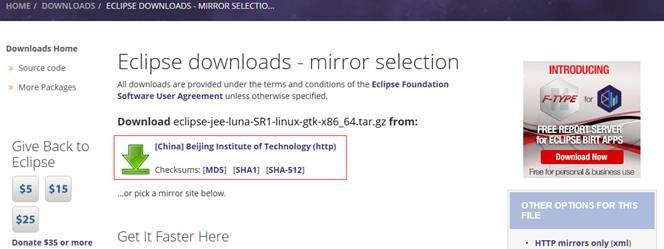
在该页面的下部分也可以根据自己的情况选择合适的镜像站点进行下载

第二种方式从镜像站点直接下载elipse:
http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/
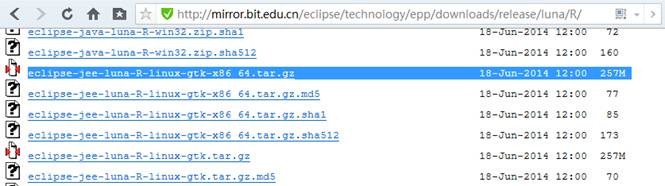
在镜像站点选择 eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz进行下载
(http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz)
2》解压elipse
在/home/hadoop/Downloads/目录中,使用如下命令解压elipse并移动到/usr/local目录下:
cd /home/hadoop/Downloads
tar -zxvf eclipse-jee-luna-SR1-linux-gtk-x86_64.tar.gz
sudo mv eclipse /usr/local/
cd /usr/local
ls


3》启动eclipse
登录到虚拟机桌面,进入/usr/local/eclipse目录,通过如下命令启动eclipse:
cd /usr/local/eclipse
./eclipse
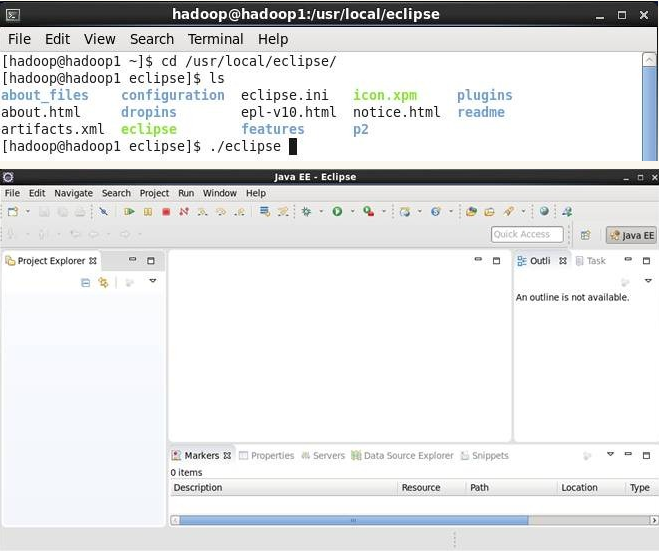
为了方便操作,可以在虚拟机的桌面上建立elipse的快捷操作
2.在Eclipse中安装hadoop插件
Hadoop2.7.1插件下载:http://download.csdn.net/download/gaoyunbo007/9973198
1、将下载好的插件移动到eclipse安装目录下的plugins文件夹下。
2、重新启动eclispe,配置hadoop安装目录和hdfs端口。
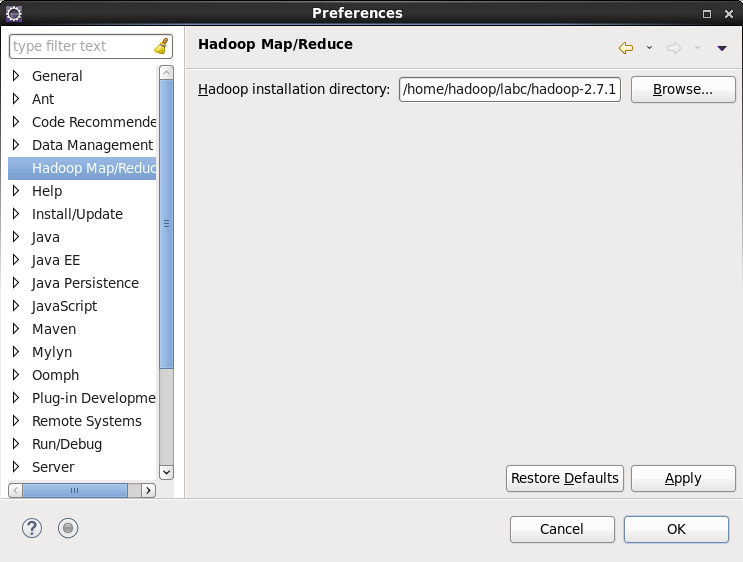
如果插件安装成功,打开【Windows】—>【Preferences】后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置hadoop安装路径,然后点击【OK】。
打开【Windows】–>【Perspective】–>【Open perspective】–>【Other】,选择【Map/Reduce】,点击【OK】。

点击【Map/Reduce Location】选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
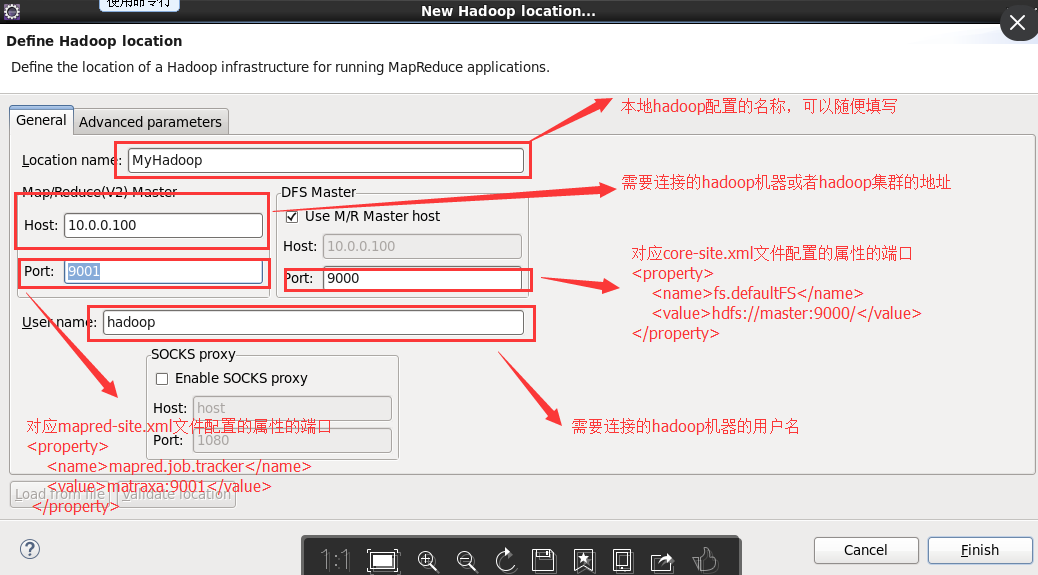
输入Location Name,任意名称即可。配置Map/Reduce Master,Host和Port配置成与mapred-site.xml的设置一致和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致,点击【Finish】。
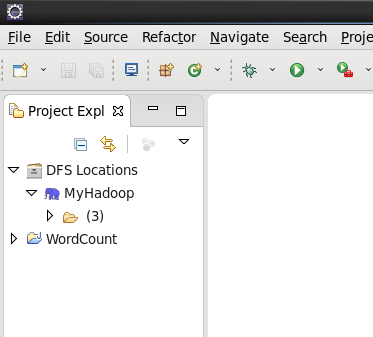
点击左侧的DFSLocations—>MyHadoop(上一步配置的location name),如果不报错,表示安装成功。
注意:这里和Hadoop1.x不一样,1.x版本这里会有user文件夹,2.x以后没有,如果你是新装的hadoop,这里显示的文件数为0,此时并不是报错。
3.测试插件是否配置成功
新建WordCount项目
1、点击【File】—>【Project】,选择【Map/Reduce Project】,输入项目名称WordCount,一直回车。
在WordCount项目里新建class,名称为WordCount,代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}2、在HDFS上创建目录input
hadoop fs -mkdir /input
3、拷贝本地README.txt到HDFS的input里
hadoop fs -copyFromLocal /home/hadoop/labc/hadoop/README.txt /input
4、点击WordCount.java,右键,点击【Run As】—>【Run Configurations】,配置运行参数,即输入和输出文件夹
hdfs://Master:9000/input hdfs://Master:9000/output
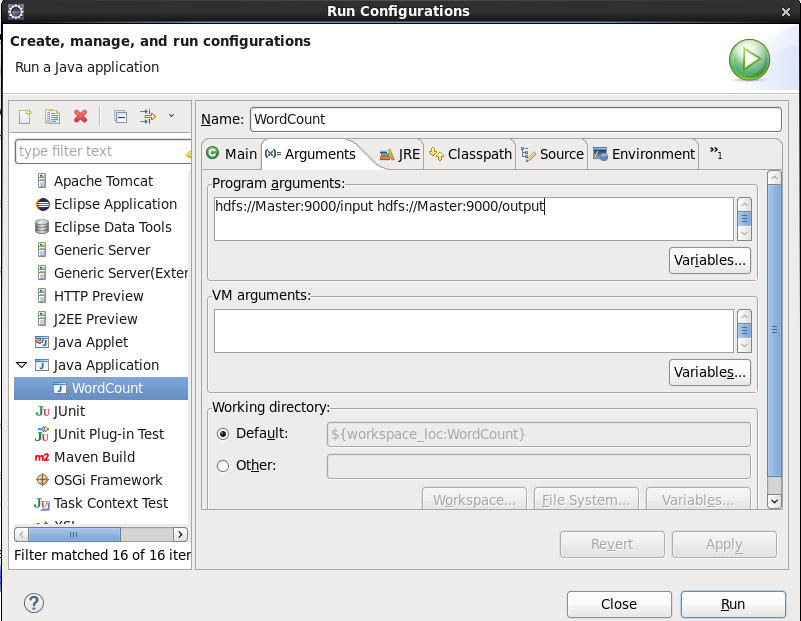
5、点击【Run】,运行程序。
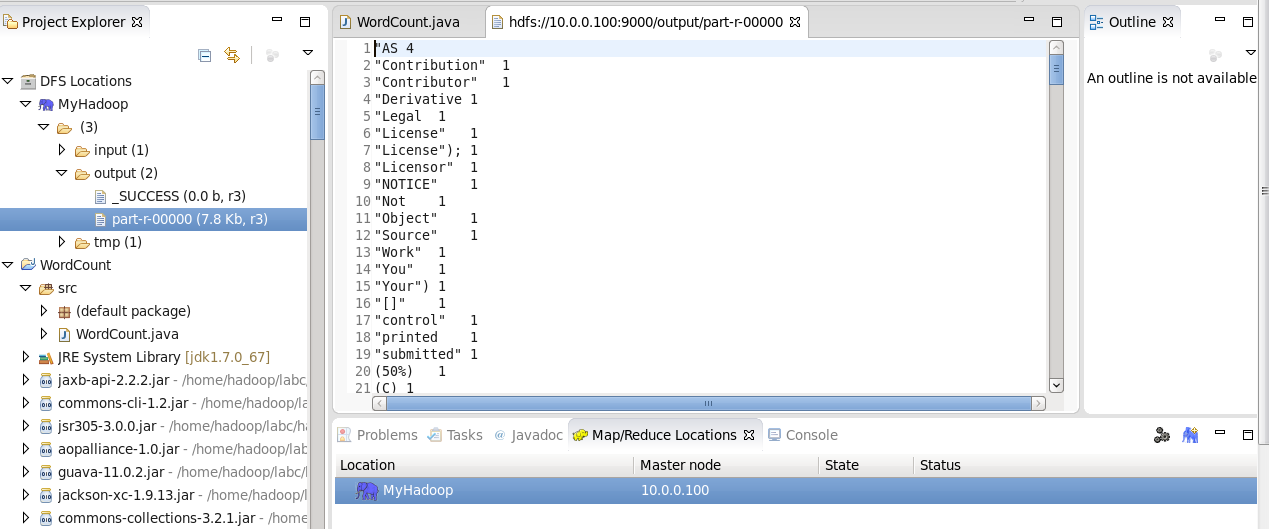
查看运行结果:
1> 在控制台输入:
hadoop fs -cat /output/part-r-00000
2>展开【DFS Locations】
ubuntu16.04上Eclipse和hadoop配置的更多相关文章
- 在ubuntu16.04上安装eclipse
在ubuntu16.04上安装eclipse 一.下载 首先我们需要安装jdk1.8及其以上,然后从官网:https://www.eclipse.org/downloads/上下载,需要注意 ...
- 在ubuntu16.04上编译android源码【转】
本文转载自:http://blog.csdn.net/fuchaosz/article/details/51487585 1 前言 经过3天奋战,终于在Ubuntu 16.04上把Android 6. ...
- ubuntu16.04上在使用搜狗输入法时,按shift不能正常切换中英文
问题描述: ubuntu16.04上在使用搜狗输入法时,不知道把什么组合键给错按了,导致了按shift不能正常切换中英文,这是一件很烦恼的事儿! 解决步骤: 1,终端输入打开: fcitx-confi ...
- primecoin在ubuntu16.04上部署服务:
primecoin在ubuntu16.04上部署服务: 一.下载Tomcat,Jdk,primecoin(公司内部文件) 注意Tomcat版本需要高于Jdk的,不然会报错. 二.把它们都解压到你要的安 ...
- Ubuntu16.04上安装cudnn教程和opencv
https://blog.csdn.net/wang15061955806/article/details/80791112 Ubuntu16.04上安装cudnn教程 2018年06月24日 14: ...
- Ubuntu11.04上tftp服务的配置
Ubuntu11.04上tftp服务的配置 2011-06-17 15:01 以前ubuntu版本上的tftp已经配置很多遍了,详情可以参见:www.mcuos.com/thread-646-1-2. ...
- Ubuntu16.04上用源代码安装ICE
ubuntu16.04上用源代码安装ICE
- Ubuntu16.04上安装neo4j数据库
什么是neo4j数据库? neo4j数据库是图数据库的一种,属于nosql的一种,常见的nosql数据库还有redis.memcached.mongDB等,不同于传统的关系型数据库,nosql数据也有 ...
- 【MindSpore】Ubuntu16.04上成功安装GPU版MindSpore1.0.1
本文是在宿主机Ubuntu16.04上拉取cuda10.1-cudnn7-ubuntu18.04的镜像,在容器中通过Miniconda3创建python3.7.5的环境并成功安装mindspore_g ...
随机推荐
- jdbcmysql
做java开发难免会用到数据库,操作数据库也是java开发的核心技术.那我们现在就来谈谈javajdbc来操作mysql数据库吧 第一步:我们需要把mysql的驱动引进来这里引驱动就是把mysql-c ...
- Spring 、 CXF 整合 swagger 【试炼】
官网:http://swagger.io/ http://swagger.io/specification/ 上面就是描述了什么是 SWAGGER OBJECT 2. 如何用jax-rs 注解方式产生 ...
- (转) MVC 中 @help 用法
ASP.NET MVC 3支持一项名为“Razor”的新视图引擎选项(除了继续支持/加强现有的.aspx视图引擎外).当编写一个视图模板时,Razor将所需的字符和击键数减少到最小,并保证一个快速.通 ...
- 层层递进Struts1(三)之Struts组成
这篇博客我们来说一下Struts的主要组成我们,通过前几篇博客,我们知道这个框架最重要的几个步骤:获取路径.封装表单.获取转向列表.转向逻辑处理.转向,与此对应的是:ActionServlet.Act ...
- NOR Flash的学习
NOR Flash简介 NOR FLASH是INTEL在1988年推出的一款商业性闪存芯片,它需要很长的时间进行抹写,大半生它能够提供完整的寻址与数据总线,并允许随机存取存储器上的任何区域,而且 ...
- Javascript设计模式理论与实战:状态模式
在软件开发中,很大部分时候就是操作数据,而不同数据下展示的结果我们将其抽象出来称为状态,我们平时开发时本质上就是对应用程序的各种状态进行切换并作出相应处理.状态模式就是一种适合多种状态场景下的设计模式 ...
- linux新定时器:timefd及相关操作函数
timerfd是Linux为用户程序提供的一个定时器接口.这个接口基于文件描述符,通过文件描述符的可读事件进行超时通知,所以能够被用于select/poll的应用场景. 一,相关操作函数 #inclu ...
- python3字符集之间--encode与decode之间的转码详解
encode是编码,里面传入的参数是需要转成的字符集,decode是解码,里面传入的参数是本身的字符集,用本身的字符集解码为unicode字符集再转码 字符集之间的爱恨纠缠 # -*- coding: ...
- NetCore入门篇:(四)Net Core项目启动文件Startup
一.Startup介绍 1.Startup文件是Net Core应用程的启动程序,实现全局配置. 2.Net Core默认情况下,静态文件及Session都未启动,需要在Startup文件配置启动,否 ...
- 使用chosen插件实现多级联动和置位
使用chosen插件实现多级联动和置位 首先写好第一个select,加上onchage属性之后,写onchange方法. <select data-placeholder="选择省份. ...