hanlp和jieba等六大中文分工具的测试对比
本篇文章测试的哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP这六大中文分词工具是由 水...琥珀 完成的。相关测试的文章之前也看到过一些,但本篇阐述的可以说是比较详细的了。这里就分享一下给各位朋友!
安装调用
jieba“结巴”中文分词:做最好的 Python 中文分词组件
THULAC清华大学:一个高效的中文词法分析工具包
FoolNLTK可能不是最快的开源中文分词,但很可能是最准的开源中文分词
教程:FoolNLTK 及 HanLP使用
HanLP最高分词速度2,000万字/秒
**中科院 Ictclas 分词系统 - NLPIR汉语分词系统
哈工大 LTP
LTP安装教程[python 哈工大NTP分词 安装pyltp 及配置模型(新)]
如下是测试代码及结果

下面测试的文本上是极易分词错误的文本,分词的效果在很大程度上就可以提现分词器的分词情况。接下来验证一下,分词器的宣传语是否得当吧。
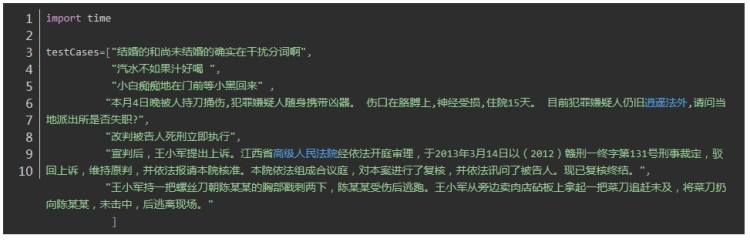
jieba 中文分词
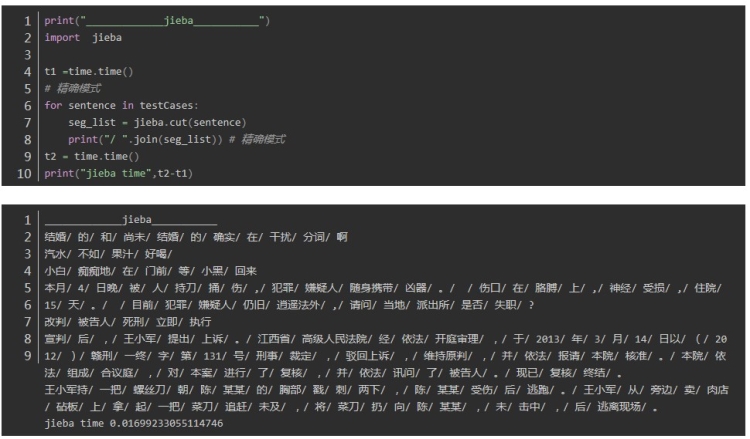
thulac 中文分词
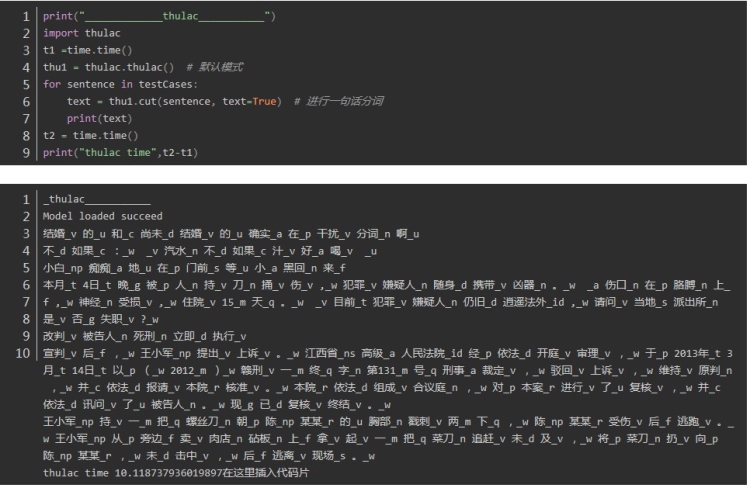
fool 中文分词
HanLP 中文分词
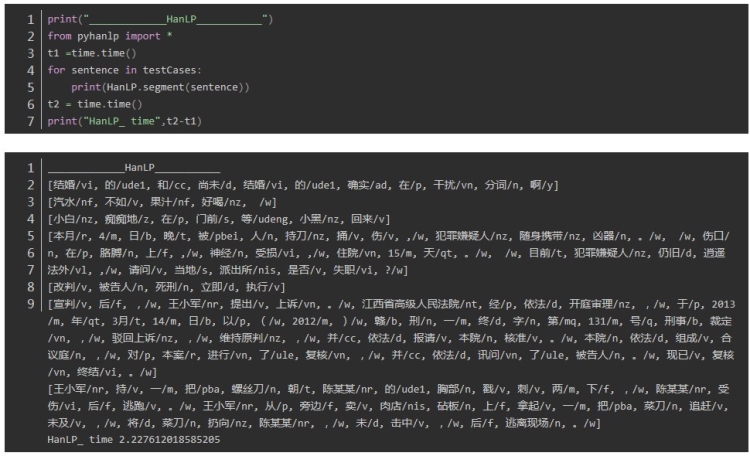
中科院分词 nlpir
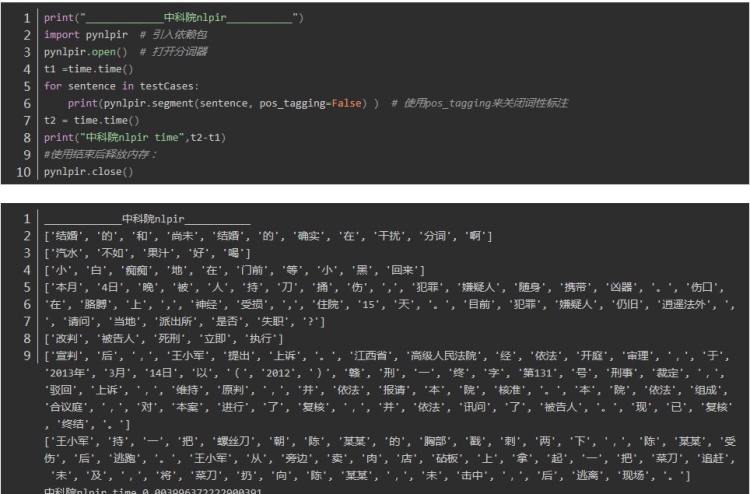
哈工大ltp 分词
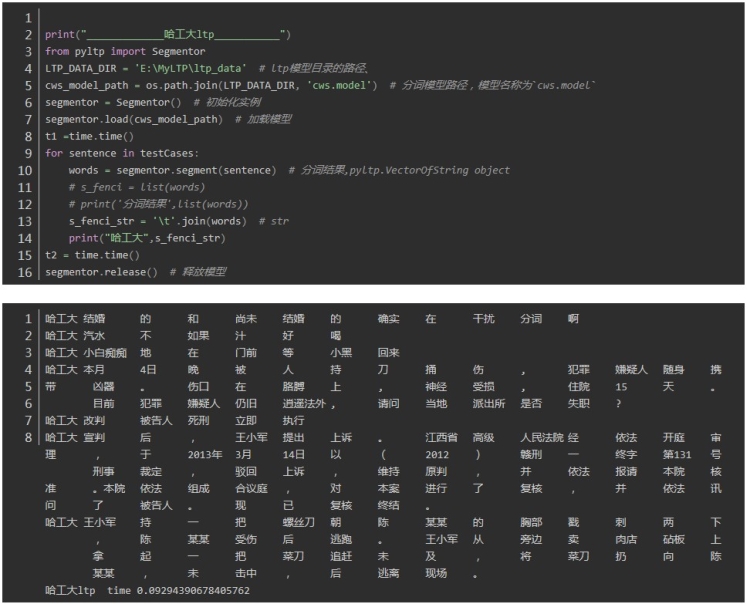
以上可以看出分词的时间,为了方便比较进行如下操作:
分词效果对比
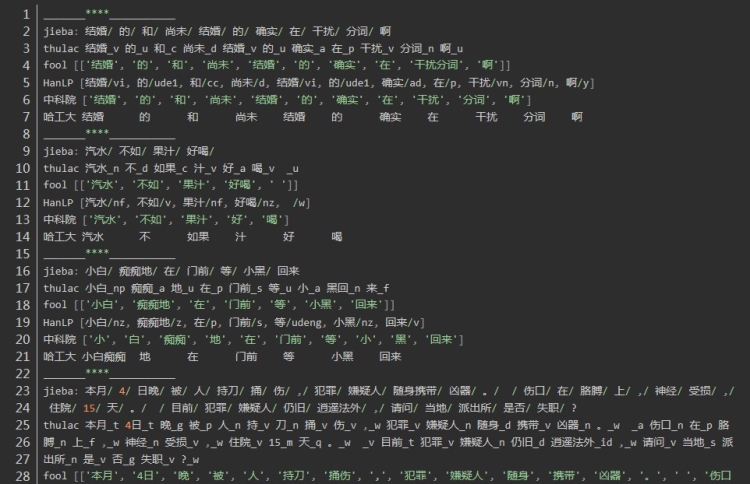
结果为:
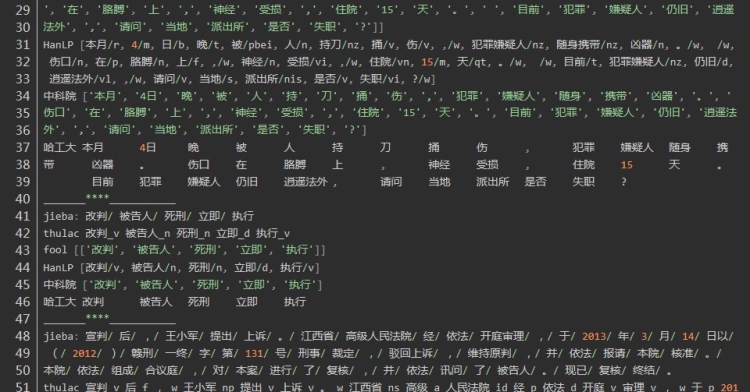
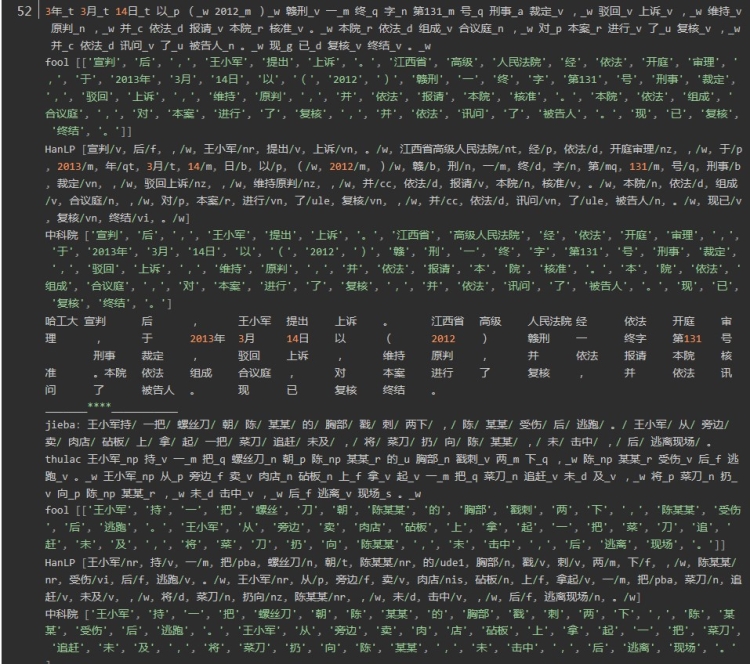

总结:
1.时间上(不包括加载包的时间),对于相同的文本测试两次,四个分词器时间分别为:
jieba: 0.01699233055114746 1.8318662643432617
thulac : 10.118737936019897 8.155954599380493
fool: 2.227612018585205 2.892209053039551
HanLP: 3.6987085342407227 1.443108320236206
中科院nlpir:0.002994060516357422
哈工大ltp_ :0.09294390678405762
可以看出平均耗时最短的是中科院nlpir分词,最长的是thulac,时间的差异还是比较大的。
2.分词准确率上,通过分词效果操作可以看出
第一句:结婚的和尚未结婚的确实在干扰分词啊
四个分词器都表现良好,唯一不同的是fool将“干扰分词”合为一个词
第二句:汽水不如果汁好喝,重点在“不如果”,“”不如“” 和“”如果“” 在中文中都可以成词,但是在这个句子里是不如 与果汁 正确分词
jieba thulac fool HanLP
jieba、 fool 、HanLP正确 thulac错误
第三句: 小白痴痴地在门前等小黑回来,体现在人名的合理分词上
正确是:
小白/ 痴痴地/ 在/ 门前/ 等/ 小黑/ 回来
jieba、 fool 、HanLP正确,thulac在两处分词错误: 小白_np 痴痴_a 地_u 在_p 门前_s 等_u 小_a 黑回_n 来_f
第四句:是有关司法领域文本分词
发现HanLP的分词粒度比较大,fool分词粒度较小,导致fool分词在上有较大的误差。在人名识别上没有太大的差异,在组织机构名上分词,分词的颗粒度有一些差异,Hanlp在机构名的分词上略胜一筹。
六种分词器使用建议:
对命名实体识别要求较高的可以选择HanLP,根据说明其训练的语料比较多,载入了很多实体库,通过测试在实体边界的识别上有一定的优势。
中科院的分词,是学术界比较权威的,对比来看哈工大的分词器也具有比较高的优势。同时这两款分词器的安装虽然不难,但比较jieba的安装显得繁琐一点,代码迁移性会相对弱一点。哈工大分词器pyltp安装配置模型教程
结巴因为其安装简单,有三种模式和其他功能,支持语言广泛,流行度比较高,且在操作文件上有比较好的方法好用python -m jieba news.txt > cut_result.txt
对于分词器的其他功能就可以在文章开头的链接查看,比如说哈工大的pyltp在命名实体识别方面,可以输出标注的词向量,是非常方便基础研究的命名实体的标注工作。
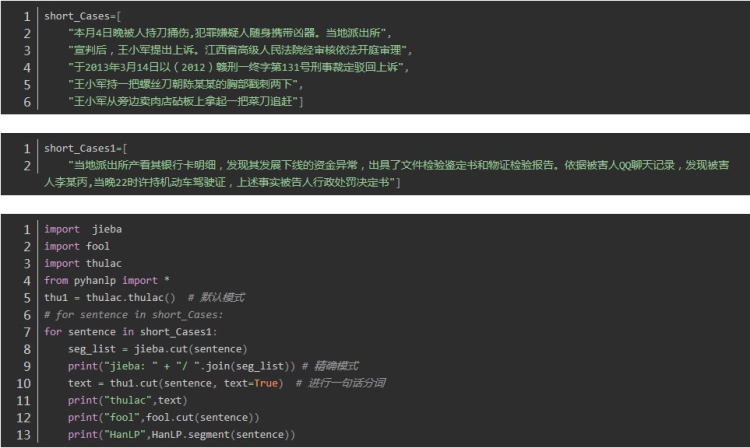
精简文本 效果对比

hanlp和jieba等六大中文分工具的测试对比的更多相关文章
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- 分词工具比较及使用(ansj、hanlp、jieba)
一.分词工具 ansj.hanlp.jieba 二.优缺点 1.ansj 优点: 提供多种分词方式 可直接根据内部词库分出人名.机构等信息 可构造多个词库,在分词时可动态选择所要使用的词库缺点: 自定 ...
- 中文分词工具——jieba
汉字是智慧和想象力的宝库. --索尼公司创始人井深大 简介 在英语中,单词就是"词"的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的 ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
随机推荐
- Python库,让你相见恨晚的第三方库
环境管理 管理 Python 版本和环境的工具 p – 非常简单的交互式 python 版本管理工具.pyenv – 简单的 Python 版本管理工具.Vex – 可以在虚拟环境中执行命令.virt ...
- java学习笔记17(Calendarl类)
Calendar类:(日历) 用法:Calendar是一个抽象类:不能实例化(不能new),使用时通过子类完成实现,不过这个类不需要创建子类对象,而是通过静态方法直接获取: 获取对象方法:getIns ...
- git解决not a git repository
意思是说没有库,需要你创建 git init zzz zzz文件夹就会出现在你的项目中,里面就会有.git文件,将里面的.git剪切到与项目同一级中 关注微信小程序
- python学习笔记第二周
目录 一.基础概念 1.模块 1)os模块 2)sys模块 2.pyc文件 3.数据类型 1)数字 2)布尔值 3)字符串 4.数据运算 5.运算符 6.赋值运算 7.逻辑运算 8.成员运算 9.身份 ...
- websocket js 代码样例
function StartWebSocket(wsUri) { websocket = new WebSocket(wsUri); websocket.onopen = function(evt) ...
- In Compiler.php line 36: Please provide a valid cache path.
/********************************************************************************* * In Compiler.php ...
- MySQL篇,第一章:数据库知识1
MySQL 数据库 1 一.MySQL概述 1.什么是数据库 数据库是一个存储数据的仓库 2.哪些公司在用数据库 金融机构.购物网站.游戏网站.论坛网站... ... 3.提供 ...
- tf.contrib.rnn.core_rnn_cell.BasicLSTMCell should be replaced by tf.contrib.rnn.BasicLSTMCell.
For Tensorflow 1.2 and Keras 2.0, the line tf.contrib.rnn.core_rnn_cell.BasicLSTMCell should be repl ...
- Web form ajax请求
1.添加web应用程序 2.添加web窗体 web窗体Demo <%@ Page Language="C#" AutoEventWireup="true" ...
- 修改select样式
CSS就可以解决,原理是将浏览器默认的下拉框样式清除,然后应用上自己的,再附一张向右对齐小箭头的图片即可. select { /*Chrome和Firefox里面的边框是不一样的,所以复写了一下*/ ...