Hive DDL及DML操作
一.修改表
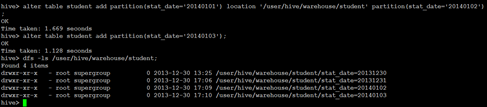
增加/删除分区
语法结构
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
ALTER TABLE table_name DROP partition_spec, partition_spec,...
ü 具体实例
|
alter table student_p add partition(part='a') partition(part='b'); |
重命名表
ü 语法结构
ALTER TABLE table_name RENAME TO new_table_name
ü 具体实例

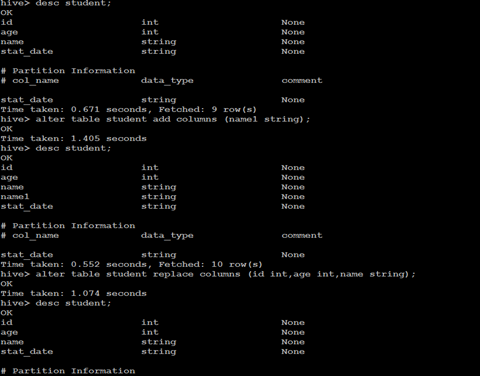
增加/更新列
ü 语法结构
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
ü 具体实例
二.显示命令
show tables
show databases
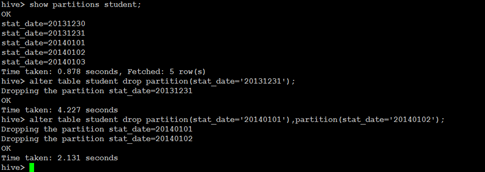
show partitions
show functions
desc extended t_name;
desc formatted table_name;
三. Load命令
Load基础语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
Load语法关键字
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
有如下关键字:
Filepath
LOCAL关键字
OVERWRITE 关键字
filepath
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode:9000/user/hive/project/data1
LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。如果没有指定 LOCAL 关键字,则根据inpath中的uri查找文件
OVERWRITE 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
加载数据
直接将数据文本复制到/user/hive/warehouse/目录
通过load data指令
Hive(版本0.14以前)不支持一条一条的用insert语句进行插入操作,也不支持update的操作。数据是以load的方式,加载到建立好的表中。
数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。
LOAD DATA格式
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
关键字[OVERWRITE]意思是是覆盖原表里的数据,不写则不会覆盖。 关键字[LOCAL]是指你加载文件的来源为本地文件,不写则为hdfs的文件。
实例:
load data local inpath '/home/hadoop/user_info_data.txt' into table t_user_info;
load data inpath '/home/hadoop/student.txt' into table t_user;
LOAD DATA实例
load data local inpath '/home/hadoop/student.txt' into table t_user;
load data inpath '/home/hadoop/student.txt' into table t_user;
load到指定表的分区
直接将file,加载到指定表的指定分区。表本身必须是分区表,如果是普通表,导入会成功,但是数据实际不会被导入。具体sql如下:
LOAD DATA LOCAL INPATH '/home/admin/test/test.txt' OVERWRITE INTO TABLE test_1 PARTITION(pt=’xxxx)
四.Insert语句
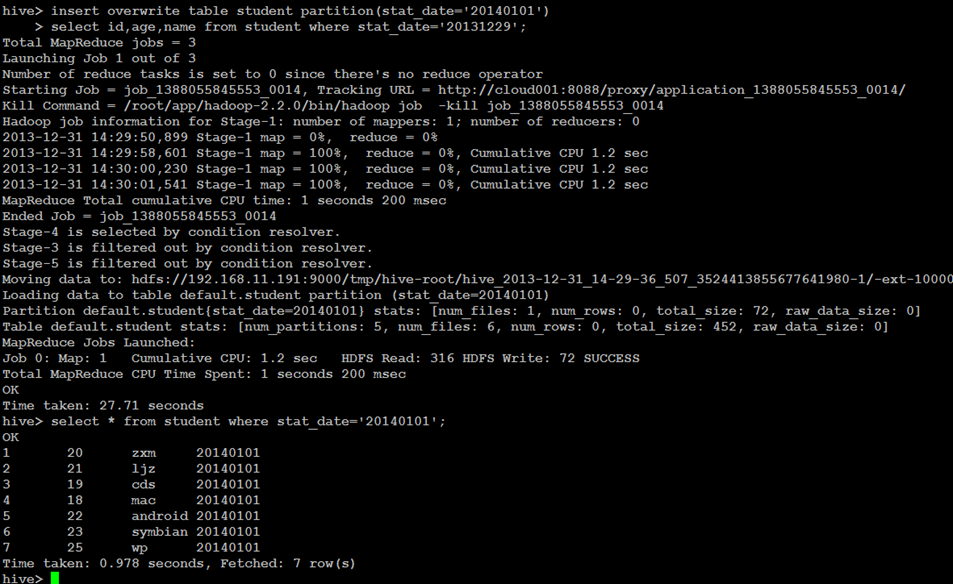
查询结果插入Hive表
INSERT OVERWRITE [INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
Multi Inserts多重插入
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...]
Select statement2] ...
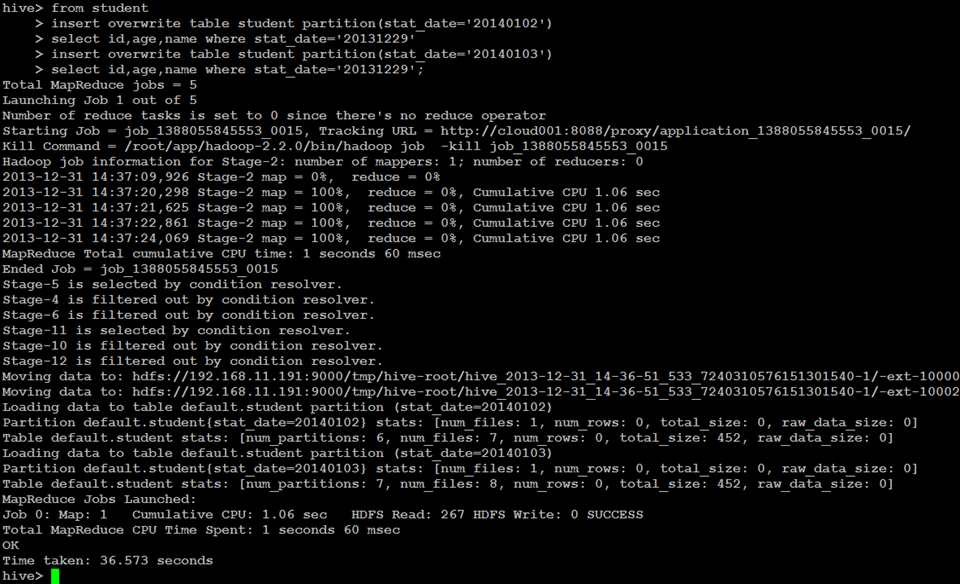
动态分区插入
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
使用了非严格模式
set hive.exec.dynamic.partition.mode=nonstrict

导出表数据
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...
multiple inserts:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
导出文件到本地
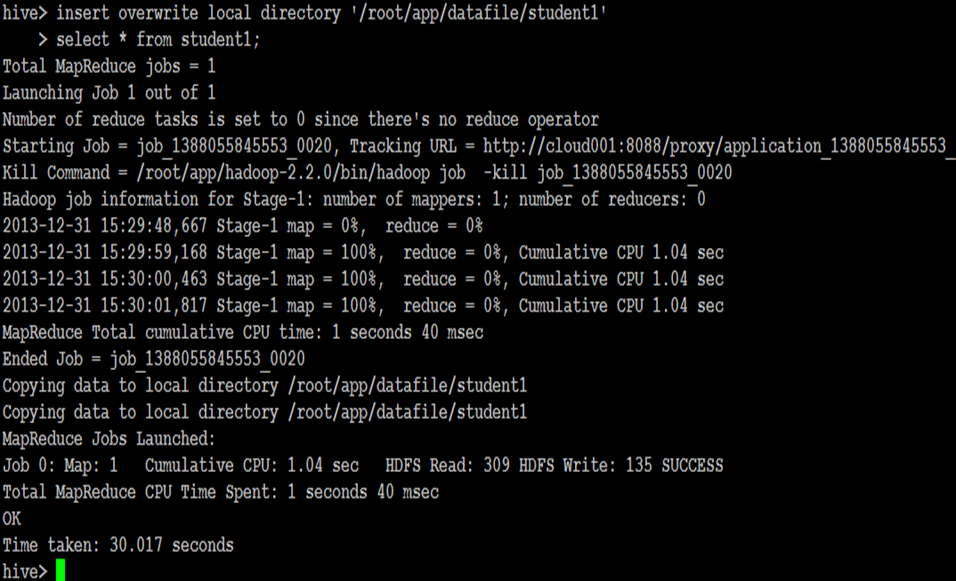
导出文件到HDFS

Hive DDL及DML操作的更多相关文章
- Hive DDL、DML操作
• 一.DDL操作(数据定义语言)包括:Create.Alter.Show.Drop等. • create database- 创建新数据库 • alter database - 修改数据库 • dr ...
- 23-hadoop-hive的DDL和DML操作
跟mysql类似, hive也有 DDL, 和 DML操作 数据类型: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ ...
- Oracle DBLINK 抽数以及DDL、DML操作
DB : 11.2.0.3.0 原库实例orcl:SQL> select instance_name from v$instance; INSTANCE_NAME--------------- ...
- Oracle ddl 和 dml 操作
ddl 操作 窗口设置用户权限的方法 Oracle的数据类型 按住Ctrl点击表名 ,可以鼠标操作 插入的数据需要满足创建表的检查 主表clazz删除数据从表设置级联也会一同删除 有约束也 ...
- Hive 编程之DDL、DML、UDF、Select总结
Hive的基本理论与安装可参看作者上一篇博文<Apache Hive 基本理论与安装指南>. 一.Hive命令行 所有的hive命令都可以通过hive命令行去执行,hive命令行中仍有许多 ...
- 大数据开发实战:Hive表DDL和DML
1.Hive 表 DDL 1.1.创建表 Hive中创建表的完整语法如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [ (col_nam ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
- hbase的常用的shell命令&hbase的DDL操作&hbase的DML操作
前言 笔者在分类中的hbase栏目之前已经分享了hbase的安装以及一些常用的shell命令的使用,这里不仅仅重新复习一下shell命令,还会介绍hbase的DDL以及DML的相关操作. hbase的 ...
- Hbase_02、Hbase的常用的shell命令&Hbase的DDL操作&Hbase的DML操作(转)
阅读目录 前言 一.hbase的shell操作 1.1启动hbase shell 1.2执行hbase shell的帮助文档 1.3退出hbase shell 1.4使用status命令查看hbase ...
随机推荐
- snmp 简单网管协议
snmpget是取具体的OID的值.(适用于OID值是一个叶子节点的情况) snmpwalk snmpwalk — Fetch all the SNMP objects from an agent & ...
- JFrame,JPanel,JLabel详解
JFrame是一个顶层的框架类,好比一个窗户的框子.也是一个容器类.这个框子可以嵌入几个玻璃窗. JPanel是一个容器类,相当于一大玻璃窗. JLabel等是一些基础组件,它必须置于某个容器里,类似 ...
- HDU 6063 17多校3 RXD and math(暴力打表题)
Problem Description RXD is a good mathematician.One day he wants to calculate: ∑i=1nkμ2(i)×⌊nki−−−√⌋ ...
- 【Python】requests.post请求注册实例
#encoding=utf-8 import requests import json import time import random import multiprocessing from mu ...
- Linux 下各个目录的作用及内容
在 Linux 下,我们看到的是文件夹(目录): 在早期的 UNIX 系统中,各个厂家各自定义了自己的 UNIX 系统文件目录,比较混乱.Linux 面世不久后,对文件目录进行了标准化,于1994年对 ...
- SQL注入之Sqli-labs系列第二十八关(过滤空格、注释符、union select)和第二十八A关
开始挑战第二十八关(Trick with SELECT & UNION) 第二十八A关(Trick with SELECT & UNION) 0x1看看源代码 (1)与27关一样,只是 ...
- menson 使用方法
参考:http://mesonbuild.com/Running-Meson.html#configuring-the-source https://github.com/google/googlet ...
- unity ugui Toggle Group详解(Chinar出品、简单易懂)
UGUI Toggle Group用法教程 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar ...
- 深入java final关键字
Java final关键字详解:https://blog.csdn.net/kuangay/article/details/81509164 深入java final关键字 用法注意点和JVM对其进行 ...
- NetCore平台下使用RPC框架Hprose
NetCore下使用RPC框架Hprose https://www.jianshu.com/p/c903fca44d5d Hprose是国内非常优秀的RPC框架,和其它RPC框架比较起来,其它框架一般 ...