高斯混合模型 GMM
本文将涉及到用 EM 算法来求解 GMM 模型,文中会涉及几个统计学的概念,这里先罗列出来:
- 方差:用来描述数据的离散或波动程度.
\[var(X) = \frac{\sum_{i=1}^N( X_i-\bar{X})^2}{N-1}\]
- 协方差:协方差表示了变量线性相关的方向,取值范围是 $[-\infty, +\infty]$,一般来说协方差为正值,说明一个变量变大另一个变量也变大;取负值说明一个变量变大另一个变量变小,取0说明两个变量没有相关关系.
\[cov(X,Y) = \frac{\sum_{i=1}^N( X_i-\bar{X})(Y_i-\bar{Y}) }{N-1}\]
- 相关系数:协方差可反映两个变量之间的相互关系及相关方向,但无法表达其相关的程度,皮尔逊相关系数不仅表示线性相关的方向,还表示线性相关的程度,取值$[-1,1]$,也就是说,相关系数为正值,说明一个变量变大另一个变量也变大;取负值说明一个变量变大另一个变量变小,取0说明两个变量没有相关关系,同时,相关系数的绝对值越接近1,线性关系越显著。
\[\rho_{XY} = \frac{cov(X,Y)}{\sqrt{DX}\sqrt{DX}}\]
- 协方差矩阵: 当 $X \in \mathbb{R}^n$ 为高维数据时,协方差矩阵可以很好的反映数据的性质,在协方差矩阵中,对角线元素反映了数据在各个维度上的离散程度,协方差矩阵为对角阵,非对角线元素反映了数据各个维度的相关性,其形式如下:
\[\mathbf{\Sigma} = \begin{bmatrix}
cov(x_1,x_1) & cov(x_1,x_2)&\cdots &cov(x_1,x_n) \\ cov(x_2,x_1) & cov(x_1,x_1)&\cdots &cov(x_1,x_1) \\
\vdots & \vdots & & \vdots & \\ cov(x_n,x_1) & cov(x_n,x_1)&\cdots &cov(x_n,x_n)
\end{bmatrix}\]
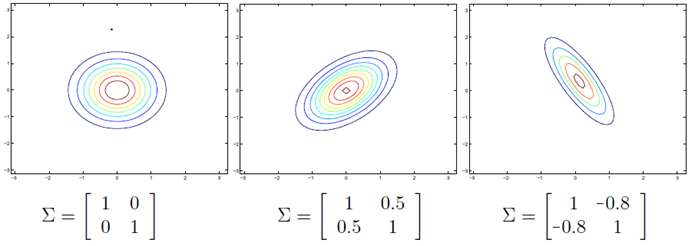
上图展示了二维情况下,使用不同的协方差矩阵时高斯分布的变化,左边代表不相关,中间为正相关,右边为负相关。
高斯分布
假设数据 $\mathbf{x} \in \mathbb{R}^n$ 服从参数为 $\mathbf{\mu},\mathbf{\Sigma}$ 的高斯分布:
\[ \mathcal{N}(\mathbf{x};\mu,\mathbf{\Sigma}) = \frac{1}{(2\pi)^{n/2}|\mathbf{\Sigma}|^{1/2}}\exp\left \{ -\frac{1}{2} (\mathbf{x}-\mu)^T\mathbf{\Sigma}^{-1}(\mathbf{x}-\mu) \right \}\]
这里 $\mu$ 为均值, $\Sigma$ 为协方差矩阵,对于单个高斯分布,当给定数据集之后,直接进行 MLE 即可估计高斯分布的参数;但是有些数据集是多个高斯分布叠加在一起形成的,也就数据集是由多个高斯分布产生的,如下图所示三个高斯分布叠加在一起:
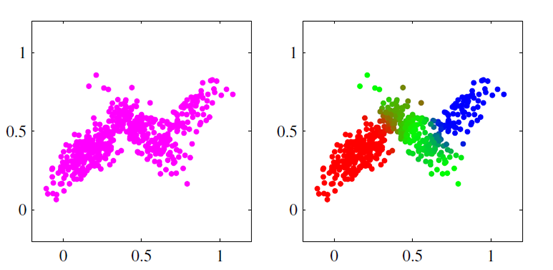
多个高斯分布叠加在一起便是混合高斯模型 GMM,GMM 的定义如下:
\[p(\mathbf{\mbox{x}}) = \sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{\mbox{x}} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\]
这里 $K$ 表示高斯分布的个数, $\pi_k$ 代表 mixing coefficient ,且满足 $0 \le \pi_k \le 1,\sum_k\pi_k = 1$,其实这里 $p(\mathbf{x})$ 表示为 $K$ 个高斯分布的加权, $\pi_k$ 就是权重系数,如果把 GMM 用在聚类中,则样本 $\mathbf{x}$ 的类别即为 $\arg\max_k\pi_k$.
在 GMM 中,需要估计的参数为 $\pi_k, \mu_k, \mathbf{\Sigma}_k$,模型里每个观测数据 $\mathbf{x}$ 都对应着一个隐变量 $\mathbf{z} \in \mathbb{R}^K$,代表的即为类别变量, 且 $\mathbf{z}_k \in \left \{ 0,1\right \}$ ,一个样本可以属于多个类别,叠加起来概率为 1 ,这里显而易见有:
\[p(\mathbf{z}_k = 1) = \pi_k \]
则第 $k$ 个高斯分布可以表示为:
\[p(\mathbf{\mbox{x}}|z_k = 1) = \mathcal{N}(\mathbf{\mbox{x}} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\]
如果已知 $\mathbf{x}$ 所属的分布 $k$ ,则可把上式写成向量形式:
\[p(\mathbf{x}|\mathbf{z}) = \mathcal{N}(\mathbf{\mbox{x}} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\]
因此完全数据的密度函数为:
\[p(\mathbf{\mbox{x}}) = \sum_{\mathbf{\mbox{z}}} p(\mathbf{\mbox{z}}) p(\mathbf{\mbox{x}} | \mathbf{\mbox{z}}) = \sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{\mbox{x}} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\]
单个样本推倒完成,接下来给定观测数据集 $X$,对应的完全数据集为 $\left\{ X,Z\right\}$ ,此时 $Z$ 是不可见的,形式如下:
\[X = \begin{bmatrix} - \mathbf{x}_1^T-\\ -\mathbf{x}_2^T -\\ \vdots \\ -\mathbf{x}_N^T -\\\end{bmatrix} \ \ Z = \begin{bmatrix} - \mathbf{z}_1^T-\\ -\mathbf{z}_2^T -\\ \vdots \\ -\mathbf{z}_N^T -\\\end{bmatrix}\]
对于该 GMM 的参数就采用 EM 算法来求解了,完全数据的联合分布为:
\[p(\mathbf{X,Z} | \mathbf{\mu, \Sigma, \pi}) = \prod_{n=1}^N \left \{ \sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{\mbox{x}}_n \vert \mathbf{\mu}_k, \mathbf{\Sigma}_k) \right \}\]
写成对数似然函数的形式:
\[\ln p(\mathbf{\mbox{X,Z}} | \mathbf{\mu, \Sigma, \pi}) = \sum_{n=1}^N \ln \left \{ \sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{\mbox{x}}_n | \mathbf{\mu}_k, \mathbf{\Sigma}_k) \right \}\]
下面便是EM 算法求解 GMM 的过程:
E步: 使用参数 $\theta^{old}=(\pi^{old},\mu^{old},\mathbf{\Sigma}^{old})$ ,计算每个样本 $x_n$ 对应隐变量 $z_n$ 的后验分布:
\begin{aligned}
\gamma(z_{nk})=p(z_n = k|\mathbf{x}_n;\mathbf{\mu}^{old},\mathbf{\Sigma}^{old})
&=\frac{p(z_{nk} = 1)p(\mathbf{x_{nk}}|z_{nk} = 1)}{\sum_{j=1}^Kp(z_{nj} = 1)p(\mathbf{x_n}|z_{nj} = 1)}\\
&= \frac{ \pi_k^{old} \mathcal{N}(\mathbf{\mbox{x}}_n | \mathbf{\mu}_k^{old}, \mathbf{\Sigma}_k^{old})} {\Sigma_{j=1}^K\pi_j^{old} \mathcal{N}(\mathbf{\mbox{x}}_n | \mathbf{\mu}_j^{old}, \mathbf{\Sigma}^{old}_j)}
\end{aligned}M步:便是极大化 Q 函数的计算,这里 Q 函数有非常漂亮的形式:
\begin{aligned}
\mathcal{Q} (\mathbf{\theta}, \mathbf{\theta}^{\mbox{old}})
&= \sum_{Z} p(Z | X,\theta^{old}) \ln p(X, Z | \theta)\\
&= \sum_{Z} p(Z | X,\theta^{old}) \ln p(X| Z ,\theta)P(Z|\theta)\\
&=\sum_{n= 1}^N \sum_{k=1}^K\gamma(z_{nk})\left \{ \ln \pi_k +\ln\mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_k ,\mathbf{\Sigma}_k) \right \}\\
\end{aligned}得到下一步迭代的参数:
\[\theta^{new}=\arg\max_{\theta}\mathcal{Q} (\mathbf{\theta}, \mathbf{\theta}^{\mbox{old}}) \]
对 Q 函数求导,另倒数得 0 ,即可求得下一次迭代的参数值,这里省去计算过程,只给出结果:
\begin{aligned}
\mathbf{\mu}_k^{new} &= \frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})\mathbf{x}_n\\
\mathbf{\Sigma}_k^{new} &= \frac{1}{N_k}\sum_{n=1}^N\gamma(z_{nk})(\mathbf{x}_n-\mathbf{\mu}_k^{new})(\mathbf{x}_n-\mathbf{\mu}_k^{new})^T \\
\mathbf{\pi}_k^{new} &= \frac{N_k}{N}
\end{aligned}
其中:
\[N_k = \sum_{n=1}^N \gamma(z_{nk})\]
这便是完整的 GMM 推倒过程,理解的不是很好,有机会继续深入。
参考:
Pattern Reconginition and Machine Learning
http://www.zhihu.com/question/20852004
http://www.cnblogs.com/nsnow/p/4758202.html
http://alexkong.net/2014/07/GMM-and-EM/
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://www.cnblogs.com/ooon/p/5787995.html
高斯混合模型 GMM的更多相关文章
- 贝叶斯来理解高斯混合模型GMM
最近学习基础算法<统计学习方法>,看到利用EM算法估计高斯混合模型(GMM)的时候,发现利用贝叶斯的来理解高斯混合模型的应用其实非常合适. 首先,假设对于贝叶斯比较熟悉,对高斯分布也熟悉. ...
- 6. EM算法-高斯混合模型GMM+Lasso详细代码实现
1. 前言 我们之前有介绍过4. EM算法-高斯混合模型GMM详细代码实现,在那片博文里面把GMM说涉及到的过程,可能会遇到的问题,基本讲了.今天我们升级下,主要一起解析下EM算法中GMM(搞事混合模 ...
- 5. EM算法-高斯混合模型GMM+Lasso
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-GMM代码实现 5. EM算法-高斯混合模型+Lasso 1. 前言 前面几篇博文对EM算法和G ...
- 4. EM算法-高斯混合模型GMM详细代码实现
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-高斯混合模型GMM详细代码实现 5. EM算法-高斯混合模型GMM+Lasso 1. 前言 EM ...
- 3. EM算法-高斯混合模型GMM
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-高斯混合模型GMM详细代码实现 5. EM算法-高斯混合模型GMM+Lasso 1. 前言 GM ...
- EM算法和高斯混合模型GMM介绍
EM算法 EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{ ...
- 高斯混合模型GMM与EM算法的Python实现
GMM与EM算法的Python实现 高斯混合模型(GMM)是一种常用的聚类模型,通常我们利用最大期望算法(EM)对高斯混合模型中的参数进行估计. 1. 高斯混合模型(Gaussian Mixture ...
- Spark2.0机器学习系列之10: 聚类(高斯混合模型 GMM)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- 高斯混合模型(GMM) - 混合高斯回归(GMR)
http://www.zhihuishi.com/source/2073.html 高斯模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数(正态分布曲 ...
随机推荐
- JSON数据之使用Fastjson进行解析(一)
据说FastJson是目前最快的解析Json数据的库,而且是国人开发出来的开源库.顶一下,付上官方网址:http://code.alibabatech.com/wiki/pages/viewpage. ...
- React页面隐藏#
将 hashHistory 改为 browserHistory 路由用到的,可以在routes.jsx上把hashHistory 改成browserHistory https://github.com ...
- 一文看懂 Dubbo 的集成与使用
前言 今年年初时,阿里巴巴开源的高性能服务框架dubbo又开始了新一轮的更新,还加入了Apache孵化器.原先项目使用了spring cloud之后,已经比较少用dubbo.目前又抽调回原来的行业应用 ...
- sublime text3中文文件名显示为框框,怎么解决
点击Preferences选项——settings { "font_size": 20, "ignored_packages": [ ...
- C++11 并发指南九(综合运用: C++11 多线程下生产者消费者模型详解)
前面八章介绍了 C++11 并发编程的基础(抱歉哈,第五章-第八章还在草稿中),本文将综合运用 C++11 中的新的基础设施(主要是多线程.锁.条件变量)来阐述一个经典问题——生产者消费者模型,并给出 ...
- 使用ExpandableListView以及如何优化view的显示减少内存占用
上篇博客讲到如何获取手机中所有歌曲的信息.本文就把上篇获取到的歌曲按照歌手名字分类.用一个ExpandableListView显示出来. MainActivity .java public cla ...
- Atitit 数据库视图与表的wrap与层级查询规范
Atitit 数据库视图与表的wrap与层级查询规范 1.1. Join层..连接各个表,以及显示各个底层字段1 1.2. 统计层1 1.3. 格式化层1 1.1. Join层..连接各个表,以及显示 ...
- linux tcp相关参数
/etc/sysctl.conf文件 /etc/sysctl.conf是一个允许你改变正在运行中的Linux系统的接口.它包含一些TCP/IP堆栈和虚拟内存系统的高级选项,可用来控制Linux网络配置 ...
- [教程]-三种空格unicode(\u00A0,\u0020,\u3000)表示的区别
1.不间断空格\u00A0,主要用在office中,让一个单词在结尾处不会换行显示,快捷键ctrl+shift+space ; 2.半角空格(英文符号)\u0020,代码中常用的; 3.全角空格(中文 ...
- 业界常用的和不常用cad快捷键
AutoCAD 是目前世界各国工程设计人员的首选设计软件,简便易学.精确无误是AutoCAD成功的两个重要原因.AutoCAD提供的命令有很多,绘图时最常用的命令只有其中的百分之二十. 在CAD软件操 ...