LSTM-自然语言建模
说到自然语言,我就会想到朴素贝叶斯,贝叶斯核心就是条件概率,而且大多数自然语言处理的思想也就是条件概率。
所以我用预测一个句子出现的概率为例,阐述一下自然语言处理的思想。
处理思想-概率
句子,就是单词的序列,句子出现的概率就是这个序列出现的概率
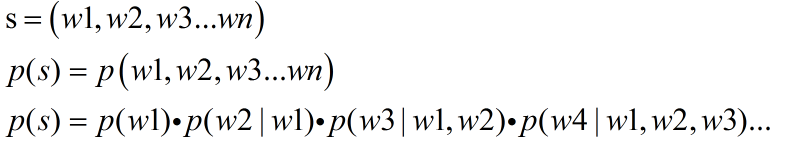
可以想象上面这个式子计算量有多大。
为了减少计算量,常常用一个估计值来代替上面的概率。估计该值常用的方法有
n-gram、决策树、最大熵模型、条件随机出、神经网络等。
以最简单的n-gram为例
n-gram模型有个假设:当前单词出现的概率仅与前面n-1个单词有关
于是,m个单词的句子出现的概率可以估计为
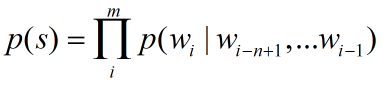
显然n取值越大,理论上这个估计越准确
但是因为计算量的问题,通常n取较小值,如 1,2,3,分别有对应的名字 unigram, bigram, trigram,最常用的是2
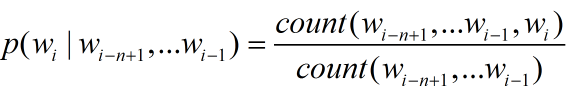
出现次数相比,很显然有个问题,如果没出现呢,比如语料库较小,那么这个单词出现的概率为0,,p(s)=0,
一个单词没出现导致整个句子出现概率为0,显然不合适
这也是自然语言处理中比较普遍的问题,常用的解决方法是拉普拉斯平滑,避免0的出现,比如

此时这个句子的概率就算出来了。
评价指标-复杂度
语言模型的好坏常用复杂度(perplexity)来评价。
如果一个句子在文档中确实出现了,那么我们的模型算出来的概率越大越好,
概率越大,就需要每个p的概率越大,
每个p越大,就意味着这某些单词出现的情况下,出现这个单词的概率很大,
也就是说,在某些单词出现时,下一个单词的可选择性很小,比如单词 “国”后面的单词很少,最常用的是“家”,此时“家”的概率就很大
这个可选择性就是复杂度。
其实可以理解为整个词语结构的复杂度,词语结构越简单,复杂度越低。图形表示如下
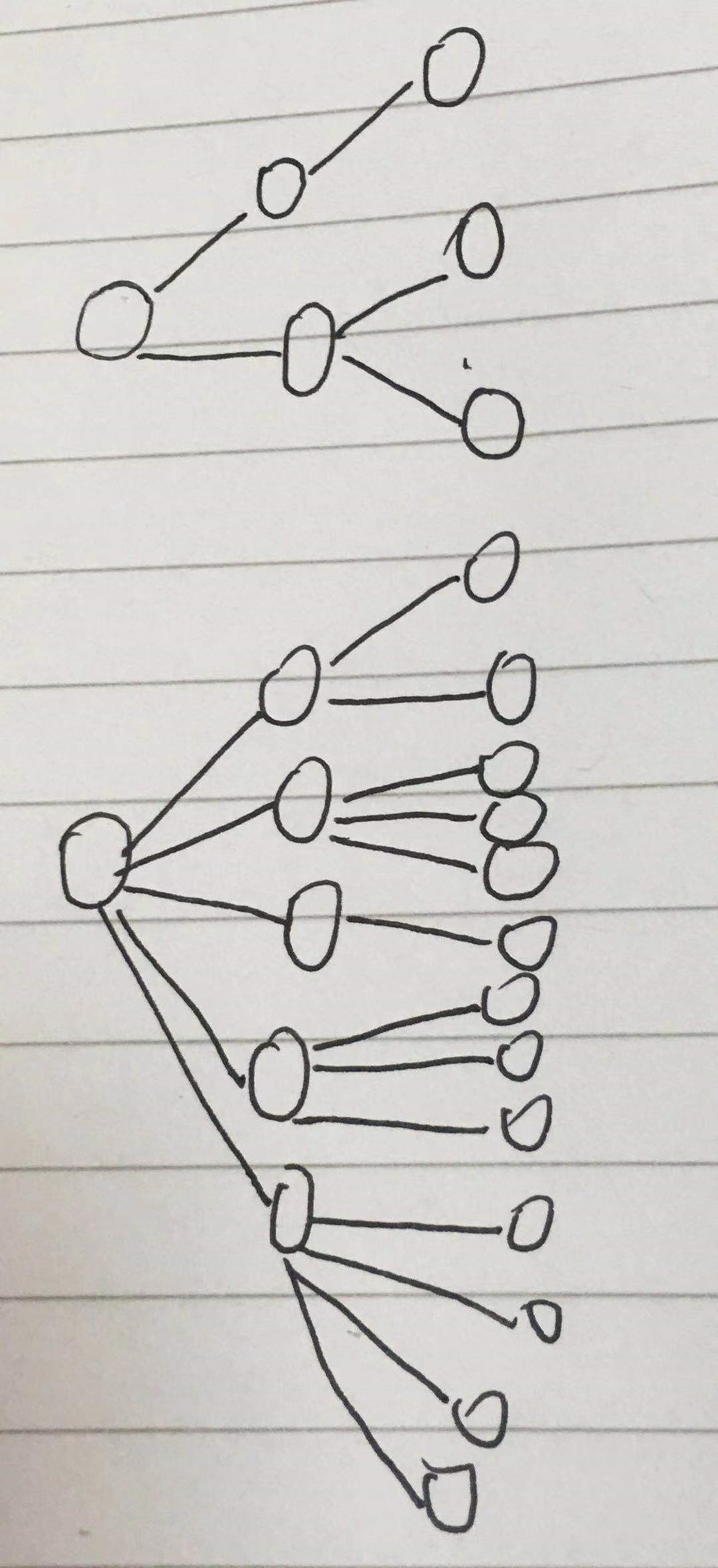
显然上面的结构简单。
可选择性可以用概率的倒数来表示。即概率越大,可选择性越小,复杂度越低。

可以两边取log简化运算。取log乘法变加法,也避免了一个为0结果为0的情况。
LSTM 语言模型
lstm 使得网络具有记忆功能,也就是记住了之前的词语,也就是在知道之前词语的情况下,训练或者预测下一个单词。这就是rnn处理自然语言的逻辑。
训练过程:输入x是单词,y是x的下一个单词,最终得到每个单词下一个单词的概率。
预测过程:取下一个单词中概率最大的单词。
图形表示如下
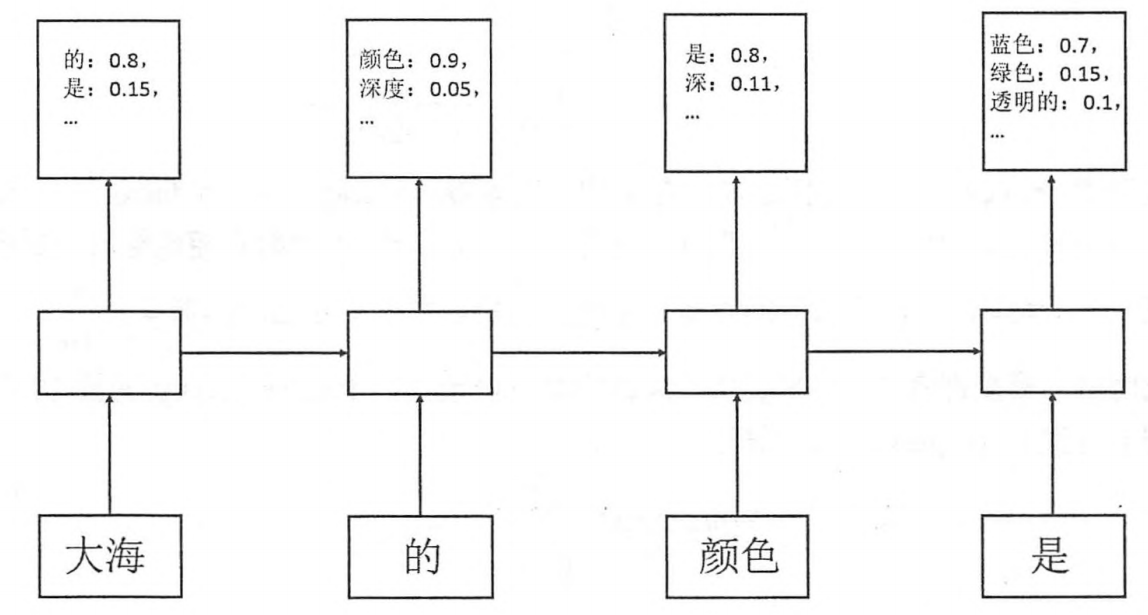
把训练样本 “大海的颜色是蓝色” 输入网络训练,可以得到在 “大海” 出现的情况下,后面是 “的” 的概率0.8,是 “是”的概率0.15,
在“大海的”出现的情况下,后面每个单词出现的概率,依次
最终预测时,在“大海的颜色是”出现的情况下,预测结果是“蓝色”的概率是0.7,预测正确。
LSTM-自然语言建模的更多相关文章
- LSTM UEBA异常检测——deeplog里其实提到了,就是多分类LSTM算法,结合LSTM预测误差来检测异常参数
结合CNN的可以参考:http://fcst.ceaj.org/CN/article/downloadArticleFile.do?attachType=PDF&id=1497 除了行为,其他 ...
- 学习笔记DL003:神经网络第二、三次浪潮,数据量、模型规模,精度、复杂度,对现实世界冲击
神经科学,依靠单一深度学习算法解决不同任务.视觉信号传送到听觉区域,大脑听学习处理区域学会“看”(Von Melchner et al., 2000).计算单元互相作用变智能.新认知机(Fukushi ...
- TensorFlow学习笔记(六)循环神经网络
一.循环神经网络简介 循环神经网络的主要用途是处理和预测序列数据.循环神经网络刻画了一个序列当前的输出与之前信息的关系.从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出. ...
- NVIDIA深度架构
NVIDIA深度架构 本文介绍A100 GPU,NVIDIA Ampere架构GPU的重要新功能. 现代云数据中心中运行的计算密集型应用程序的多样性推动了NVIDIA GPU加速的云计算的爆炸式增长. ...
- A100 Tensor核心可加速HPC
A100 Tensor核心可加速HPC HPC应用程序的性能需求正在迅速增长.众多科学研究领域的许多应用程序都依赖于双精度(FP64)计算. 为了满足HPC计算快速增长的计算需求,A100 GPU支持 ...
- NVIDIA安培架构
NVIDIA安培架构 NVIDIA Ampere Architecture In-Depth 在2020年英伟达GTC主题演讲中,英伟达创始人兼首席执行官黄仁勋介绍了基于新英伟达安培GPU架构的新英伟 ...
- 论文笔记:A Structured Self-Attentive Sentence Embedding
A Structured Self-Attentive Sentence Embedding ICLR 2017 2018-08-19 14:07:29 Paper:https://arxiv.org ...
- 《A Structured Self-Attentive Sentence Embedding》(注意力机制)
Background and Motivation: 现有的处理文本的常规流程第一步就是:Word embedding.也有一些 embedding 的方法是考虑了 phrase 和 sentence ...
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
A Review on Deep Learning Techniques Applied to Semantic Segmentation 2018-02-22 10:38:12 1. Intr ...
- SAP成都研究院飞机哥: SAP C4C中国本地化之微信聊天机器人的集成
今天的文章仍然来自Jerry的老同事,SAP成都研究院的张航(Zhang Harry).关于他的背景介绍,请参考张航之前的文章:SAP成都研究院飞机哥:程序猿和飞机的不解之缘.下面是他的正文. 大家好 ...
随机推荐
- EntityFramework的安装
关于EntityFramework在vs2012无法引用的问题 这段时间学习MVC,发现一个问题,我公司的电脑可以直接引用EntityFrameWork这个命名空间,但我家里面的电脑就不能直接引用,刚 ...
- LeetCode--014--最长公共前缀
问题描述: 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flo ...
- Fiddler拦截http请求修改数据
1.拦截http请求 使用Fiddler进行HTTP断点调试是fiddler一强大和实用的工具之一.通过设置断点,Fiddler可以做到: ①修改HTTP请求头信息.例如修改请求头的UA,Cookie ...
- 2-sat学习笔记
前后缀建图 例:要求n个变量满足至多有1个为true. 暴力:一个点的true向其它n-1个点的false连边,复杂度O(n^2). 正解:prei表示前i个点是否有真. prei的true向prei ...
- git clone项目
1. 生成公钥和私钥 ssh-keygen 2. 将公钥添加到github或者gitlab上,一般github或者gitlab允许添加多个公钥,可能是考虑到用户使用不同的机器了吧,还是很贴心的. 3. ...
- docker-compose 在线安装升级
参考:https://docs.docker.com/compose/install/ curl -L "https://github.com/docker/compose/releases ...
- commonJS,常用js工具方法
说明:平时项目用到的一些常见过滤方法,有些是vue过滤器,稍微修改下吧,我就不改了. js四舍五入不准确的解决(重写方法): Number.prototype.toFixed = function(l ...
- WDA基础六:字段,表等visiable,enable,read_only控制
今天主要讲一下布局控制:(visiable,enable,read_only) visiable:可见性,控制字段,组件,分组等是否现实在界面上.一般按条件来控制隐藏的可以在CONTEXT NODE里 ...
- CSS text-decoration 属性
定义和用法 text-decoration 属性规定添加到文本的修饰. 注释:修饰的颜色由 "color" 属性设置. 说明 这个属性允许对文本设置某种效果,如加下划线.如果后代元 ...
- 通过DBMS_REDEFINITION包对表在线重定义
基础介绍 Oracle Online Redefinition可以保证在数据表进行DDL类型操作,如插入.删除数据列,分区处理的时候,还能够支持DML操作,特别是insert/update/delet ...