基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
目录
1 准备工作
什么是Redis?
Redis:一个高性能的key-value数据库。支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用;提供string、list、set、zset、hash等数据结构的存储,并支持数据的备份。
本文适合使用的场景:当一个项目中Redis缓存的数据量逐渐增大,Redis缓存的数据占用内存也会越来越大,而且其中有很多很可能是价值不大的数据。由于Redis是一个key-value数据库,所以对其中的数据进行分析没有mysql数据库那么直观。那么此时,我们需要寻找工具来分析Redis缓存中的哪些数据占用内存比较大,并结合项目实际的情况来分析这些数据存储的价值如何?从而作出具体删减数据的方案,来解放服务器端宝贵的内存资源。
本文需要采用的工具:Rdbtools和MySQL。
Rdbtools:使用Python语言编写的,可以解析Redis的dump.rdb文件。此外,提供以下工具:
(1)跨所有数据库和密钥生成数据的内存报告
(2)将dump文件转换为JSON
(3)使用标准diff工具比较两个dump文件
具体源码GitHub链接:https://github.com/sripathikrishnan/redis-rdb-tools/
MySQL:一种开源且比较轻量级的关系型数据库。本文使用Rdbtools解析出Redis的dump.rdb文件并生成内存报告*.csv文件(PS:下文操作文件为result_facelive_hot.csv),然后把该文件导入到MySQL数据库中,最后通过编写具体的SQL语句脚本生成想要的数据分析结果的*.csv文件(PS:下文SQL脚本中生成的文件名为redis_key_storage.csv)。
2 具体实施
Rdbtools工具在以下操作,需要Python2.7或者Python3.6等版本环境的支持。
(1)找到本机项目使用Redis生成的dump.rdb文件具体所在地址。(PS:本文操作的项目是一个基于Django框架,部署在Ubuntu系统上,所以相关命令都是该系统下的实际操作,其它环境基本类似,就不作介绍)
sudo find / -name '*.rdb'
运行上述命令后,即可看到本机上所有以.rdb为后缀文件的所有具体地址,然后根据项目实际情况,找到具体地址。例如,本文找到的地址:
/home/facelive/redis/data/hot/dump.rdb
PS:有的项目,使用Redis时,会把默认的dump.rdb文件进行了重新命名,例如命名为db-dump.rdb文件。那么此时如何判定具体命名呢?
可以查看项目使用Redis数据库的redis.conf文件内容,并结合以下命令:
cat -n redis.conf |grep "dbfilename"
即可查看具体的文件名。
(2)使用Rdbtools生成项目中使用Redis的内存使用的*.csv文件
此处需要项目先安装Rdbtools工具,项目且是基于Python环境。激活项目的虚拟环境,输入命令:
pip install rdbtools python-lzf
(3)安装完成后,即可在项目的虚拟环境中使用rdb命令。此处本文生成内存报告的命令如下:
rdb -c memory /home/facelive/redis/data/hot/dump.rdb > ~/result_facelive_hot.csv
生成的result_facelive_hot.csv文件会存放在服务器环境根目录。此时,可以从服务器把生成的文件复制到本地,具体操作命令参考:
sudo scp facelive@188.100.10.10:/home/facelive/result_facelive_hot.csv . # 从服务器复制远程文件到本地当前所在根目录,这里的ip是我自己随便写的噢
然后在本地打开result_facelive_hot.csv文件,结果如下(以下截图结果是在Windows环境下打开的噢):
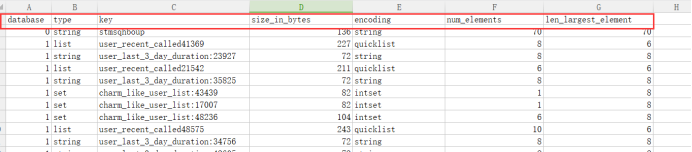
可以看到该表中有database(对应的数据库)、type(缓存的类型)、key(缓存的key名称)、size_in_bytes(该key具体占用内存大小,这是本文数据分析的核心数据)、encoding(缓存key的编码)、num_elements和len_larget_element六列数据。
(4)把result_facelive_hot.csv导入到MySQL数据库,进行数据分析
首先,选定本地MySQL数据库中某一已经创建好的数据库,并在该数据库中创建一个名称为redis_hot的表(PS:具体表名可随意定)
创建表的SQL语句:
DROP TABLE IF EXISTS `redis_hot`; CREATE TABLE `redis_hot` ( `database` int(11) DEFAULT NULL, `type` varchar(100) DEFAULT NULL, `key` varchar(200) DEFAULT NULL, `size_in_bytes` int(11) DEFAULT NULL, `encoding` varchar(255) DEFAULT NULL, `num_elements` int(11) DEFAULT NULL, `len_largest_element` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建好redis_hot表后,我们开始使用Navicat工具来进行数据导入工作。
PS:此处也可以使用脚本来完成具体数据写入,使用脚本命令的好处是,当导入的CSV文件过大,即数据量很大的时候,使用Navicat客户端会假死,导致数据压根就无法导入,但是脚本可以正常一键导入,不会出现问题。不过以下的使用Navaicat的方法还是可以参考一下。具体脚本代码如下:
create database if not exists facelive_redis default character set 'utf8'; use facelive_redis; DROP TABLE IF EXISTS `redis_hot`;
CREATE TABLE `redis_hot` (
`database` int(11) DEFAULT NULL,
`type` varchar(100) DEFAULT NULL,
`key` varchar(200) DEFAULT NULL,
`size_in_bytes` int(11) DEFAULT NULL,
`encoding` varchar(255) DEFAULT NULL,
`num_elements` int(11) DEFAULT NULL,
`len_largest_element` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8; load data local infile '~/facelive_redis/result_facelive_hot.csv' # 此处修改为自己文件保存的具体实际地址即可
into table redis_hot character set gb2312
fields terminated by ',' optionally enclosed by '"' escaped by '"'
lines terminated by '\n';
以下操作是在Windows环境下进行,其它环境使用Navicat可视化工具,操作步骤基本类似。
首先,使用Navicat打开本地数据库,找到刚刚创建的redis_hot表,鼠标点击右键,选择导入向导,具体流程如下:
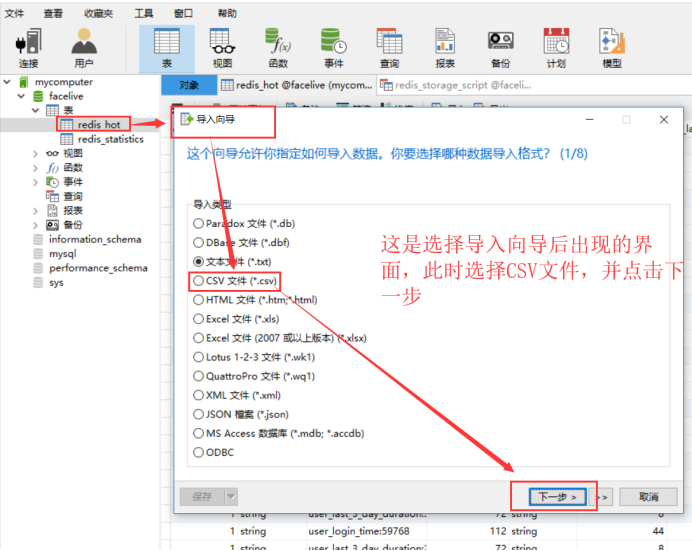
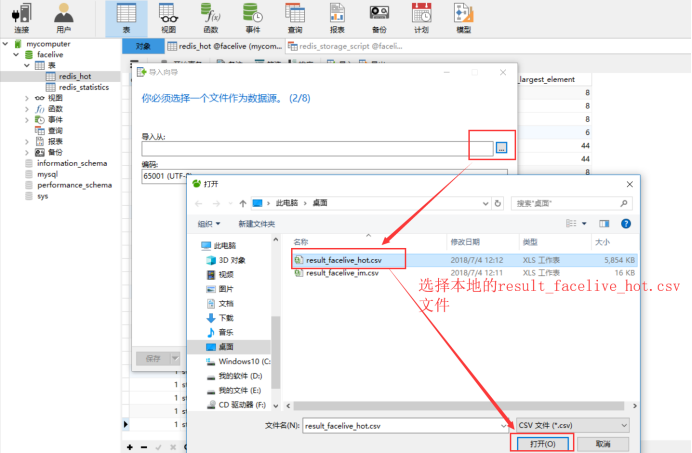


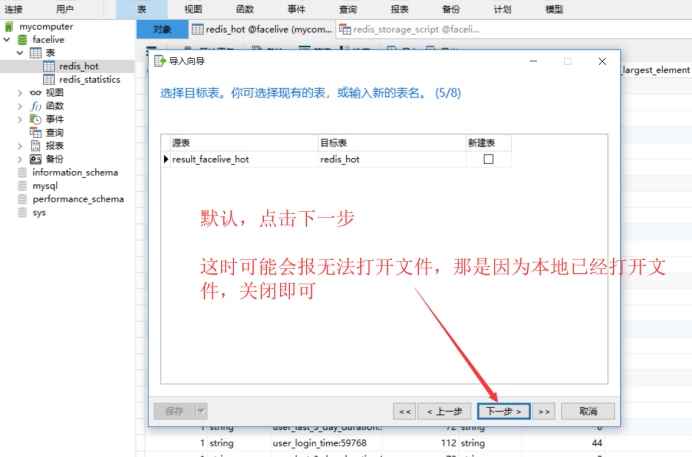


数据导入完成后,下面正式开始编写SQL查询脚本,生成具体所需分析结果数据。
此处需要分析的数据:
(1)每一种key所在用的总内存大小(size_in_bytes_sum)
(2)每一种key的总数(PS:因为有的key设计是前缀+用户id,这样的情况都属于一种key)(record_count)
(3)每一种key所在数据库(database)
(4)每一种key的数据类型(type)
(5)每一种key的编码类型(encoding)
(6)每一种key的名称(key)
(7)每一种key占用的平均内存大小(size_in_bytes_avg)
使用的SQL脚本代码如下:
# core_user
SELECT ANY_VALUE(`database`) as `database`, ANY_VALUE(type) as type, ANY_VALUE(`key`) as `key`, ANY_VALUE(encoding) as encoding,
count(`database`) as record_count, SUM(size_in_bytes) as size_in_bytes_sum,
AVG(size_in_bytes) as size_in_bytes_avg FROM redis_hot WHERE `key` LIKE 'user_verify_code_%'
UNION
SELECT ANY_VALUE(`database`) as `database`, ANY_VALUE(type) as type, ANY_VALUE(`key`) as `key`, ANY_VALUE(encoding) as encoding,
count(`database`) as record_count, SUM(size_in_bytes) as size_in_bytes_sum,
AVG(size_in_bytes) as size_in_bytes_avg FROM redis_hot WHERE `key` LIKE 'robot_id_list%'
UNION
... # 此处是使用连接(UNION)查询,每一个`SELECT`查询代表一个`key`信息,所以后续项目中`key`跟新时,也需要在本文件中写入一个新的连接查询
... # 指定的数据中查询`key`不存在,则最后统一返回一条全是0的数据,相当于过滤作用
/* 此处可以继续使用UNION来并查其他名称的key具体分析数据,下面一行代码是生成redis_key_storage.csv文件,如果注释掉,就可以直接在Navicat查询界面查看具体查询结果 */ into outfile 'E:/redis_key_storage.csv' fields terminated by ','
optionally enclosed by '"' lines terminated by '\r\n';
# 其中可以修改具体文件保存地址(此处文件保存地址:'E:/redis_key_storage.csv')
最终得到的结果数据如下:

好啦,介绍这里就结束了,希望能对观看本文的同学有所帮助~
参考资料:
1.使用代码完成csv文件导入Mysql(https://blog.csdn.net/quiet_girl/article/details/71436108)
2.使用rdbtools工具来解析redis dump.rdb文件及内存使用量(http://www.ywnds.com/?p=8441)
3.MySQL必知必会:组合查询(Union)(https://segmentfault.com/a/1190000007926959)
基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)的更多相关文章
- [转]在nodejs使用Redis缓存和查询数据及Session持久化(Express)
本文转自:https://blog.csdn.net/wellway/article/details/76176760 在之前的这篇文章 在ExpressJS(NodeJS)中设置二级域名跨域共享Co ...
- 在nodejs使用Redis缓存和查询数据及Session持久化(Express)
在nodejs使用Redis缓存和查询数据及Session持久化(Express) https://segmentfault.com/a/1190000002488971
- 基于python的Elasticsearch索引的建立和数据的上传
这是我的第一篇博客,还请大家多多指点 Thanks ♪(・ω・)ノ 今天我想讲一讲关于Elasticsearch的索引建立,当然提前是你已经安装部署好Elasticsearch. ok ...
- springboot中如何向redis缓存中存入数据
package com.hope;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jack ...
- python笔记-12 redis缓存
一.redis引入 1.简要概括redis 1.1 redis默认端口:6379 1.2 redis实现的效果:资源共享 1.3 redis实现的基本原理:不同的进程和一个公共的进程之间建立socke ...
- redis持久化AOF详细操作步骤
1.切换到redis目录下面,创建文件 s3-redis.conf 2.编辑文件s3-redis.conf 3.终止当前redis服务端 4.登录redis客户端失败,说明服务端已停止 5.重启red ...
- webrtc笔记(1): 基于coturn项目的stun/turn服务器搭建
webrtc是google推出的基于浏览器的实时语音-视频通讯架构.其典型的应用场景为:浏览器之间端到端(p2p)实时视频对话,但由于网络环境的复杂性(比如:路由器/交换机/防火墙等),浏览器与浏览器 ...
- springboot-不同名称项目的 redis session共享
引入JAR <dependency> <groupId>org.springframework.session</groupId> <artifactId&g ...
- 基于apktool项目的android批量打包工具,多平台支持
好久木有写博客了,今天有点兴致就写一下,献上一个没怎么用的批量打包工具,python实现的,虽然说现在android的批量打包有一个很好的工具可以使用gradle,这个灰常牛叉的工具和android ...
随机推荐
- JQUery利用Uploadify插件实现文件异步上传(十一)
一:简介: Uploadify是JQuery的一个上传插件,实现的效果非常好,带进度显示 ,且Ajax异步,能一次性上传多个文件,功能强大,使用简单 1.支持单文件或多文件上传,可控制并发上传的文件数 ...
- rabbitmq安装及基本操作(含集群配置)
一.rabbitmq的安装 因为rabbitmq是基于 erlang语言开发,所有要先安装erlang 1.安装erlang 这里我下载的是19.2的版本,地址为https://www.erlang. ...
- Redis数据结构之字符串
学习阶段分成两个部分,一个是redis客户端,一个是java客户端操作 一:在redis客户端操作 1.先删除里面的几个key 2.set与get与getset 3.数值的增减 值递增1,或者减一 如 ...
- Python4 - 文件操作
对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 文件的内存对象-包含 文件名.字符集.大小.在硬盘上的起止位置... 通过句柄对文件进行操作 关闭文件 open 方法 open()函数打开一个 ...
- linux shell cut 命令
cut命令 cut命令用于从文件或者标准输入中读取内容并截取每一行的特定部分并送到标准输出. 截取的方式有三种:一是按照字符位置,二是按照字节位置,三是使用一个分隔符将一行分割成多个field,并提取 ...
- C++语言实现-拓扑排序
1.拓扑排序的概念 对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则 ...
- ubuntu server 18.04 lts 终端中文显示为乱码的解决方案
.最近安装ubuntu server 18.04 lts版本发现系统自带的终端下无论是编辑中文,还是显示中文均出现乱码,还是老毛病, 今天无意中发现通过ssh,远程访问,在windows中安装开源的p ...
- 007.基于Docker的Etcd分布式部署
一 环境准备 1.1 基础环境 ntp配置:略 #建议配置ntp服务,保证时间一致性 etcd版本:v3.3.9 防火墙及SELinux:关闭防火墙和SELinux 名称 地址 主机名 备注 etcd ...
- 【原创】ABP源码分析
接口篇 IConventionalDependencyRegistra接口分析 待续.............. 模块篇 敬请期待...... 领域篇 敬请期待...... 消息篇 敬请期待..... ...
- Emit学习笔记
1,给字段设置值,并返回 static void Main(string[] args) { //给字段设置值,并返回 AssemblyName assemblyName = new Assembly ...