[转]在nodejs使用Redis缓存和查询数据及Session持久化(Express)
本文转自:https://blog.csdn.net/wellway/article/details/76176760
在之前的这篇文章 在ExpressJS(NodeJS)中设置二级域名跨域共享Cookie 中提及将Session存放到Mongodb中,其中有很多讲解的不是很详细。
我们为什么要把Session存放到数据中,以及又为什么要在子域名间跨域共享Cookie呢?
Session与Cookie的关系
客户端与服务会使用一个Sessionid的Cookie值来进行客户端和服务器端会话的匹配,这个Cookie一般是服务器端读/写的,并在Http请求响应的Header中的Set-Cookie属性设置:
HTTP/1.1 200 OK
Server: nginx
Date: Wed, 14 Jan 2015 02:29:09 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Proxy-Connection: Keep-Alive
Connection: Keep-Alive
Content-Encoding: gzip
Set-Cookie: sessionid=i4w3axuzyj4nwwg75y6k5us2; path=/; domain=.ourjs.com; httponly
- path=/ 表示这个cookie是设置在根目录的。
- httponly 属性禁止客户端JavaScript的访问,防止当前会话(sessionid)被恶意的js脚本盗取
- domain=.ourjs.com 表示将sessionid存放到主域名下,各个二级域名域名均使用此Cookie (sessionid)
注* 中间代理人攻击,即是通过代理服务器(如无线路由)盗取你的会话Cookie(SessionID等),从而访冒你的身份。因此Google建议网站全部采用HTTPS协议,加密传输内容,并提高了纯HTTPS网站的权重。
使用数据库来集中管理session,存放Session内容,并在各个子域名跨域共享Cookies (SessionID),即可实现为每一个子域分配一个独立的node.js Web服务器,各个服务程序均可依据sessionid从数据库中寻找到同一Session,从而实现不同Web Server中的会话同步,从而实现一定程度上的负载均衡。
要想实现完全意义的负载均衡还需要将Web服务做到完全状态无关,不仅仅是Session,所有的中间缓存数据都要转移到与服务器无关的缓存层中,这正是Redis最善长的地方。
但是为什么存放在Redis中要比MongoDB中好呢?
将Session存放到MongoDB
在MongoDB中是这样存放Session的, 使用 connect-mongo 即用来将Express中的Session持久化到Mongodb的一个中间件,它也可以在connect上使用。
Express 4.x, 5.0 与 Connect 3.x配合使用:
var session = require('express-session');
var MongoStore = require('connect-mongo')(session);
app.use(session({
secret: 'foo',
store: new MongoStore(options)
}));
Express 2.x, 3.x 和 Connect 1.x, 2.x配合使用:
var MongoStore = require('connect-mongo')(express);
app.use(express.session({
secret: 'foo',
store: new MongoStore(options)
}));
对于 Connect 只需要将express替换成connect即可
MongoDB 是一个基于文档的数据库,所有数据是从磁盘上进行读写的。MongoDB善长的是对无模式JSON数据的查询。
而Redis是一个基于内存的键值数据库,它由C语言实现的,与Nginx/ NodeJS工作原理近似,同样以单线程异步的方式工作,先读写内存再异步同步到磁盘,读写速度上比MongoDB有巨大的提升。因此目前很多超高并发的网站/应用都使用Redis做缓存层,普遍认为其性能明显好于MemoryCache。当并发达到一定程度时,即可考虑使用Redis来缓存数据和持久化Session。
在NodeJS中使用Redis缓存数据
Redis (安装方法) 数据库采用极简的设计思想,最新版的源码包还不到2Mb。其在使用上也有别于一般的数据库。
node_redis
redis驱动程序多使用 node_redis 此模块可搭载官方的 hiredis C 语言库 - 同样是非阻塞的,比使用JavaScript内置的解释器性能稍好。可选择将hiredis 与 redis 一同安装。
npm install hiredis redis
如果 hiredis 安装成功, node_redis 会默认使用 hiredis, 否则会使用JavaScript的解释器。
Redis的一个Key不仅可以对应一个String类型的值,还支持hashes, lists, sets, sorted sets, bitmaps等。
比如存/取一组Hash值,Redis中有两个对应的命令
HMSET key field value [field value ...]、
为一个Key一次设置多个哈希键/值, 多用于JSON对象的写入(序列化的SESSION)。
HGETALL key
读取一个Key的所有 哈希键/值,多用于JSON对象读取
这两个命令即是在NodeJS中存取JSON对象的关键,
下面是node_reids中对应的例子:
var redis = require("redis"),
client = redis.createClient();
//写入JavaScript(JSON)对象
client.hmset('sessionid', { username: 'kris', password: 'password' }, function(err) {
console.log(err)
})
//读取JavaScript(JSON)对象
client.hgetall('sessionid', function(err, object) {
console.log(object)
})
Redis没有严格意义上的表名和字段名,以 Key-Value 键值对的方式存储,因此一般采用 schema:key 形式做为键值,其中
schema: 可理解为传统数据库中的表名
key: 可理解为表中的主键
因此使用redis存放你的session时,需要一个schema前辍, 比如这个key: sessionid:i4w3axuzyj4nwwg75y6k5us2
Redis 也仅能对Key进行检索, 尚不支持对Key所存放的Hash Key的检索。 如要检索到所有session,只需匹配 sessionid:* 即可,
client.keys('session:*', function (err, keys) {
console.log(keys)
})
有些第三方库会支持检索值中的Hash Key,但这不是一个原子性操作,redis本身并不提供。
因此在采用Redis缓存与检索数据时,要使用一些独特的数据类型,如集合(Sets)
> sadd myset 1 2 3 //添加 1 2 3到集合myset
(integer) 3
> smembers myset //列出集合的所有成员
1. 3
2. 1
3. 2
> sismember myset 30 //判断30是否存在
(integer) 0 //不存在
Redis集合不允许添加相同成员。多次添加同一元素到集合中最终只会包含一个元素。多个集合之间可以进行连接/交集这样的操作。从而实现类似传统数据库中索引、条件和连接查询的效果。
# 添加 3 个用户和信息
hmset user:1 user_name lee age 21
hmset user:2 user_name david age 25
hmset user:3 user_name chris age 25 # 维护age索引
sadd age:21 1
sadd age:25 2 3 # 维护name索引
sadd name:lee 1
sadd name:david 2
sadd name:chris 3 # 查找 age = 25 和 name = lee 的用户
sinter age:25 name:lee
-> 会返回一个空集合
将Session存放到Redis中
connect-reids 是一个 Redis 版的 session 存储器,使用node_redis作为驱动。借助它即可在Express中启用Redis来持久化你的Session.
安装
$ npm install connect-redis
在 Express 3.x 中还需要安装express-session
$ npm install express-session
参数
client 你可以复用现有的redis客户端对象, 由 redis.createClient() 创建
host Redis服务器名
port Redis服务器端口
socket Redis服务器的unix_socket
可选参数
ttl Redis session TTL 过期时间 (秒)
disableTTL 禁用设置的 TTL
db 使用第几个数据库
pass Redis数据库的密码
prefix 数据表前辍即schema, 默认为 "sess:"
使用
将express-session传给connect-redis来启用
var session = require('express-session');
var RedisStore = require('connect-redis')(session);
app.use(session({
store: new RedisStore(options),
secret: 'keyboard cat'
}));
检验
app.use(function (req, res, next) {
if (!req.session) {
return next(new Error('oh no')) // handle error
}
next() // otherwise continue
})
这样你的Session就转移到了Redis数据库,这样做的一个额外好处是,当你的Express服务器突然重启后,用户仍然可以使用当前Cookie中的SessionID从数据库中获取到他的会话状态,做到会话不丢失,在一定程度上提高网站的键壮性。
如果你的NodeJS网站上的所有缓存数据都转移到了Redis后,就可做到完全状态无关,按需扩展网站的规模。
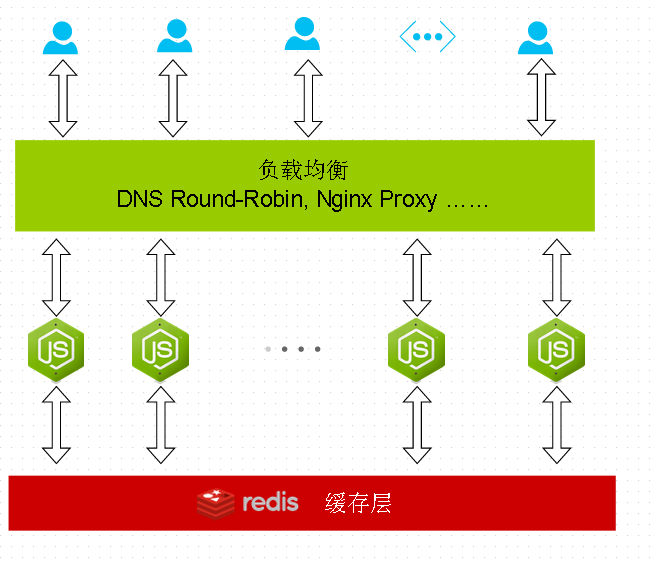
可水平扩展的NodeJS网站服务器集群(非 cluster模块 不同,它们是相互独立的,可分布在不同的物理服务器上),这样的架构,对于应对超大规模并发也是有好处的。
[转]在nodejs使用Redis缓存和查询数据及Session持久化(Express)的更多相关文章
- 在nodejs使用Redis缓存和查询数据及Session持久化(Express)
在nodejs使用Redis缓存和查询数据及Session持久化(Express) https://segmentfault.com/a/1190000002488971
- springboot中如何向redis缓存中存入数据
package com.hope;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jack ...
- 基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
目录 1 准备工作 2 具体实施 1 准备工作 什么是Redis? Redis:一个高性能的key-value数据库.支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使 ...
- 在NodeJS中使用Redis缓存数据
Redis数据库采用极简的设计思想,最新版的源码包还不到2Mb.其在使用上也有别于一般的数据库. node_redis redis驱动程序多使用 node_redis 此模块可搭载官方的 hiredi ...
- 本地缓存,Redis缓存,数据库DB查询(结合代码分析)
问题背景 为什么要使用缓存?本地缓存/Redis缓存/数据库查询优先级? 一.为什么要使用缓存 原因:CPU的速度远远高于磁盘IO的速度问题:很多信息存在数据库当中的,每次查询数据库就是一次IO操作所 ...
- 总结:如何使用redis缓存加索引处理数据库百万级并发
前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想.准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1000万条数据,可以参考我之前的文章插入数据, ...
- ssm+redis 如何更简洁的利用自定义注解+AOP实现redis缓存
基于 ssm + maven + redis 使用自定义注解 利用aop基于AspectJ方式 实现redis缓存 如何能更简洁的利用aop实现redis缓存,话不多说,上demo 需求: 数据查询时 ...
- spring aop搭建redis缓存
SpringAOP与Redis搭建缓存 近期项目查询数据库太慢,持久层也没有开启二级缓存,现希望采用Redis作为缓存.为了不改写原来代码,在此采用AOP+Redis实现. 目前由于项目需要,只需要做 ...
- 使用redis缓存加索引处理数据库百万级并发
使用redis缓存加索引处理数据库百万级并发 前言:事先说明:在实际应用中这种做法设计需要各位读者自己设计,本文只提供一种思想.准备工作:安装后本地数redis服务器,使用mysql数据库,事先插入1 ...
随机推荐
- shell脚本颜色输出(实例未编辑)
颜色输出通过echo 输出,需要加-e echo -e "\033[背景颜色;字体颜色\033[0m" 背景颜色 40 设置黑色背景 41 设置红色背景 42 设置绿色背景 43 ...
- Linux的内存机制(转载)
今天我们来谈谈Linux的内存机制. 首先我们理一下概念 一.什么是linux的内存机制? 我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成, ...
- 算法第四版jar包下载地址
算法第四版jar包下载地址:https://algs4.cs.princeton.edu/code/
- win32控制台程序 宽字符与短字符转化
由于vs各版本之间存在字符设置不兼容问题,特总结char与tchar的互相转换函数,如下,在之后的工程中可以使用. void TcharToChar(const TCHAR * tchar, char ...
- NodeJs在windows上安装配置测试
Node.js简介简单的说 Node.js 就是运行在服务端的 JavaScript.Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境.Node.js 使用了一个 ...
- API网关-Ocelot概述
这个框架的整体思路其实就是Redirect请求并且附带一个简易的负载均衡机制,完全搭建MVC Core项目下在Ocelot项目启动的时候需要配置所有的ReRoute集合,这里的每一个ReRoute可以 ...
- Spring Boot 2 - 初识与新工程的创建
Spring Boot的由来 相信大家都听说过Spring框架. Spring从诞生到现在一直是流行的J2EE开发框架. 随着Spring的发展,它的功能越来越强大,随之而来的缺点也越来越明显,以至于 ...
- Flask上下文
Flask的核心机制!关于请求处理流程和上下文 学习一样东西不能只停留在表面,我们要探索其中的细节,学习作者的编程思想,这样才能更进一步. 关于WSGI WSGI(全称Web Server Gatew ...
- jvm的垃圾回收和内存
垃圾回收: 对象的创建是我们程序员主导的,但是却没有与之相对应的delete方法来删除我们用完的对象,释放这些我们已经不需要再使用的对象的内存空间,gc:垃圾回收机制:指的就是JVM自带的一种释放无用 ...
- Java常用的经典排序算法:冒泡排序与选择排序
一.冒泡排序 冒泡排序(Bubble Sort)是一种交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为 ...