elasticsearch中 refresh 和flush区别【转】
elasticsearch中有两个比较重要的操作:refresh 和 flush
refresh操作
flush操作与translog
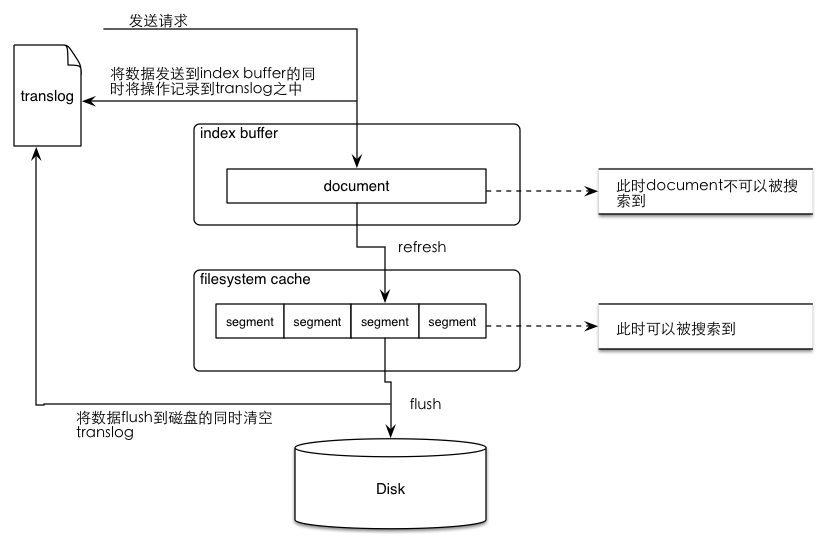
总结一下translog的功能:
再总结一下flush操作的时间点:
有关于translog和flush的一些配置项:
elasticsearch中 refresh 和flush区别【转】的更多相关文章
- elasticsearch中 refresh 和flush区别(转)
elasticsearch中有两个比较重要的操作:refresh 和 flush refresh操作 当我们向ES发送请求的时候,我们发现es貌似可以在我们发请求的同时进行搜索.而这个实时建索引并可以 ...
- elasticsearch中 refresh 和flush区别
elasticsearch中有两个比较重要的操作:refresh 和 flush refresh操作 当我们向ES发送请求的时候,我们发现es貌似可以在我们发请求的同时进行搜索.而这个实时建索引并可以 ...
- Elasticsearch:Elasticsearch中的refresh和flush操作指南
在今天的文章里,我们来主要介绍一下Elasticsearch的refresh及flush两种操作的区别.如果我们从字面的意思上讲,好像都是刷新的意思.但是在Elasticsearch中,这两种操作是有 ...
- 探究ElasticSearch中的线程池实现
探究ElasticSearch中的线程池实现 ElasticSearch里面各种操作都是基于线程池+回调实现的,所以这篇文章记录一下java.util.concurrent涉及线程池实现和Elasti ...
- ElasticSearch中的JVM性能调优
ElasticSearch中的JVM性能调优 前一段时间被人问了个问题:在使用ES的过程中有没有做过什么JVM调优措施? 在我搭建ES集群过程中,参照important-settings官方文档来的, ...
- Elasticsearch中最重要的文档CRUD要牢记
Elasticsearch文档CRUD要牢记 转载参考:https://juejin.im/post/5ddbf298e51d4523053c42e7 在Elasticsearch中,文档(docum ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- Elasticsearch中的相似度模型(原文:Similarity in Elasticsearch)
原文链接:https://www.elastic.co/blog/found-similarity-in-elasticsearch 原文 By Konrad Beiske 翻译 By 高家宝 译者按 ...
随机推荐
- 63:二叉搜索树的第k个结点
/** * 面试题63:二叉搜索树的第k个结点 * 给定一颗二叉搜索树,请找出其中的第k大的结点 * 例如, 5 / \ 3 7 /\ /\ 2 4 6 8 中,按结点数值大小顺序第三个结点的值为4. ...
- rdesktop方法(Linux to Windows)
我的配置: rdesktop -g 960x1080 -a 16 -u aura-bd -0 192.168.62.241 1. 准备工作: ubuntu端: sudo apt-get install ...
- 编辑你的数学公式——markdown中latex的使用
前言 最近开始使用起markdown来记学习笔记,因为经常有公式要写,就需要用到latex,到网上查来查去又不太方便,而且也很少能查到写的比较全的,就准备写下这篇文章. 插入数学公式 在markdow ...
- Golang vs PHP 之文件服务器
前面的话 作者为golang脑残粉,本篇内容可能会引起phper不适,请慎读! 前两天有同事遇到一个问题,需要一个能支持上传.下载功能的HTTP服务器做一个数据中心.我刚好弄过,于是答应帮他搭一个. ...
- Nuxt.js 如何在 asyncData中 请求数据 ,并将拿到的数据传给子组件
说明:同接口请求一样,也可以进行数据的处理:return 中 左侧的变量 可以直接拿到在页面上使用,也可以传递给子组件 下面再给出一段代码,方便觉得有用的.却又不想手敲的朋友们: async as ...
- jQuery File Upload 判断图片尺寸,限定图片宽高的办法
1.必须熟读jQuery File Upload 文档,在add方法中进行判断,如果不符合条件,就用 data.abort()方法取消上传动作. $("file").fileupl ...
- 多线程里面this.getName()和currentThread.getName()有什么区别
public class hello extends Thread { public hello(){ System.out.println("Thread.currentThread(). ...
- BZOJ4124 : [Baltic2015]Tug of war
建立二分图,首先如果存在度数为$0$的点,那么显然无解. 如果存在度数为$1$的点,那么这个点的匹配方案固定,可以通过拓扑排序去掉所有这种点. 那么现在剩下的点度数都至少为$2$,因为左右点数相等,且 ...
- Redis简单延时队列
Redis实现简单延队列, 利用zset有序的数据结构, score设置为延时的时间戳. 实现思路: 1.使用命令 [zrangebyscore keyName socreMin socreMax] ...
- 第二章 flex输入输出
flex程序默认总是从标准输入读取, 实际上,词法分析程序都从文件读取输入 flex总是通过名为yyin的文件句柄读取输入, 下面的例子,我们修改单词计数程序,使得它能从文件读取输入 /* even ...