lucene 分词实现
一、概念认识
1、常用的Analyer
SimpleAnalyzer、StopAnalyzer、WhitespaceAnalyzer、StandardAnalyzer
2、TokenStream
分词器做好处理之后得到的一个流,这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元信息生成的流程

在这个流中所需要存储的数据

3、Tokenizer
主要负责接收字符流Reader,将Reader进行分词操作。有如下一些实现类

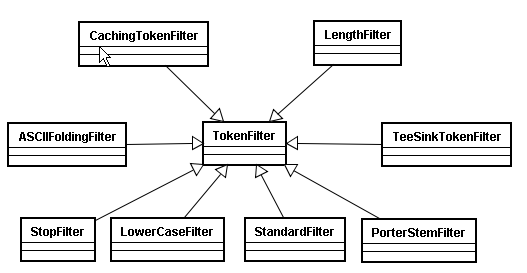
4、TokenFilter
将分词的语汇单元,进行各种各样过滤
5、内置常用分词器分词进行分词的差异
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void displayToken(String str,Analyzer a) { try { TokenStream stream = a.tokenStream("content",new StringReader(str)); //创建一个属性,这个属性会添加流中,随着这个TokenStream增加 CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class); while(stream.incrementToken()) { System.out.print("["+cta+"]"); } System.out.println(); } catch (IOException e) { e.printStackTrace(); } } |
|
1
2
3
4
5
6
7
8
9
|
public Map<String,Analyzer> toMap(String[] str,Analyzer ... analyzers){ Map<String,Analyzer> analyzerMap = new HashMap<String,Analyzer>(); int i =0; for(Analyzer a : analyzers){ analyzerMap.put(str[i], a); i++; } return analyzerMap; } |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Test public void test01() { String[] str ={"StandardAnalyzer","StopAnalyzer","SimpleAnalyzer","WhitespaceAnalyzer"}; Map<String,Analyzer> analyzerMap = new HashMap<String,Analyzer>(); Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35); Analyzer a2 = new StopAnalyzer(Version.LUCENE_35); Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35); Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35); analyzerMap = toMap(str,a1,a2,a3,a4); String txt = "this is my house,I am come from bilibili qiansongyi," + "My email is dumingjun@gmail.com,My QQ is 888168"; for(String analyzer : analyzerMap.keySet()){ System.out.println(analyzer); AnalyzerUtils.displayToken(txt, analyzerMap.get(analyzer)); System.out.println("=============================="); } } |

6、中文分词
|
1
2
3
4
5
6
7
8
9
|
public void toMap(String txt,Analyzer ... analyzers){ for(Analyzer a : analyzers){ int start = a.toString().lastIndexOf(".")+1; int end = a.toString().lastIndexOf("@")-1; System.out.println(a.toString().substring(start, end)); AnalyzerUtils.displayToken(txt, a); System.out.println("===================="); } } |
|
1
2
3
4
5
6
7
8
9
10
|
public void test02() { Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35); Analyzer a2 = new StopAnalyzer(Version.LUCENE_35); Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35); Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35); Analyzer a5 = new MMSegAnalyzer(new File("D:\\lucene\\mmseg4j\\data")); String txt = "我来自中国广东省广州市天河区的小白"; toMap(txt,a1,a2,a3,a4,a5); } |

7、位置增量、位置偏移量、分词单元、分词器的类型
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public static void displayAllTokenInfo(String str,Analyzer a) { try { TokenStream stream = a.tokenStream("content",new StringReader(str)); //位置增量的属性,存储语汇单元之间的距离 PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class); //每个语汇单元的位置偏移量 OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class); //存储每一个语汇单元的信息(分词单元信息) CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class); //使用的分词器的类型信息 TypeAttribute ta = stream.addAttribute(TypeAttribute.class); for(;stream.incrementToken();) { System.out.print(pia.getPositionIncrement()+":"); System.out.print(cta+"["+oa.startOffset()+"-"+oa.endOffset()+"]-->"+ta.type()+"\n"); } } catch (Exception e) { e.printStackTrace(); } } |

8、停用分词器
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class MyStopAnalyzer extends Analyzer { @SuppressWarnings("rawtypes") private Set stops; @SuppressWarnings("unchecked") public MyStopAnalyzer(String[]sws) { //会自动将字符串数组转换为Set stops = StopFilter.makeStopSet(Version.LUCENE_35, sws, true); //将原有的停用词加入到现在的停用词 stops.addAll(StopAnalyzer.ENGLISH_STOP_WORDS_SET); } public MyStopAnalyzer() { //获取原有的停用词 stops = StopAnalyzer.ENGLISH_STOP_WORDS_SET; } @Override public TokenStream tokenStream(String fieldName, Reader reader) { //为这个分词器设定过滤链和Tokenizer return new StopFilter(Version.LUCENE_35, new LowerCaseFilter(Version.LUCENE_35, new LetterTokenizer(Version.LUCENE_35,reader)), stops); }} |
|
1
2
3
4
5
6
7
8
|
@Test public void test04() { Analyzer a1 = new MyStopAnalyzer(new String[]{"I","you","hate"}); Analyzer a2 = new MyStopAnalyzer(); String txt = "how are you thank you I hate you"; AnalyzerUtils.displayToken(txt, a1); AnalyzerUtils.displayToken(txt, a2); } |

9、简单实现同义词索引
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class MySameAnalyzer extends Analyzer { private SamewordContext samewordContext; public MySameAnalyzer(SamewordContext swc) { samewordContext = swc; } @Override public TokenStream tokenStream(String fieldName, Reader reader) { Dictionary dic = Dictionary.getInstance("D:\\lucene\\mmseg4j\\data"); return new MySameTokenFilter( new MMSegTokenizer(new MaxWordSeg(dic), reader),samewordContext); }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public class MySameTokenFilter extends TokenFilter { private CharTermAttribute cta = null; private PositionIncrementAttribute pia = null; private AttributeSource.State current; private Stack<String> sames = null; private SamewordContext samewordContext; protected MySameTokenFilter(TokenStream input,SamewordContext samewordContext) { super(input); cta = this.addAttribute(CharTermAttribute.class); pia = this.addAttribute(PositionIncrementAttribute.class); sames = new Stack<String>(); this.samewordContext = samewordContext; } @Override public boolean incrementToken() throws IOException { if(sames.size()>0) { //将元素出栈,并且获取这个同义词 String str = sames.pop(); //还原状态 restoreState(current); cta.setEmpty(); cta.append(str); //设置位置0 pia.setPositionIncrement(0); return true; } if(!this.input.incrementToken()) return false; if(addSames(cta.toString())) { //如果有同义词将当前状态先保存 current = captureState(); } return true; } private boolean addSames(String name) { String[] sws = samewordContext.getSamewords(name); if(sws!=null) { for(String str:sws) { sames.push(str); } return true; } return false; } } |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public class SimpleSamewordContext2 implements SamewordContext { Map<String,String[]> maps = new HashMap<String,String[]>(); public SimpleSamewordContext2() { maps.put("中国",new String[]{"天朝","大陆"}); } @Override public String[] getSamewords(String name) { return maps.get(name); }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Test public void test05() { try { Analyzer a2 = new MySameAnalyzer(new SimpleSamewordContext2()); String txt = "我来自中国广东省广州市天河区的小白"; Directory dir = new RAMDirectory(); IndexWriter writer = new IndexWriter(dir,new IndexWriterConfig(Version.LUCENE_35, a2)); Document doc = new Document(); doc.add(new Field("content",txt,Field.Store.YES,Field.Index.ANALYZED)); writer.addDocument(doc); writer.close(); IndexSearcher searcher = new IndexSearcher(IndexReader.open(dir)); TopDocs tds = searcher.search(new TermQuery(new Term("content","咱")),10);// Document d = searcher.doc(tds.scoreDocs[0].doc);// System.out.println(d.get("content")); AnalyzerUtils.displayAllTokenInfo(txt, a2); } catch (CorruptIndexException e) { e.printStackTrace(); } catch (LockObtainFailedException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } |

lucene 分词实现的更多相关文章
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息 在此回复牛妞的关于程序中分词器的问题,其实可以直接很简单的在词库中配置就好了,Lucene中分词的所有信息我们都可以从 ...
- Hibernate Search集与lucene分词查询
lucene分词查询参考信息:https://blog.csdn.net/dm_vincent/article/details/40707857
- Lucene系列三:Lucene分词器详解、实现自己的一个分词器
一.Lucene分词器详解 1. Lucene-分词器API (1)org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分 ...
- WebGIS中兴趣点简单查询、基于Lucene分词查询的设计和实现
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 兴趣点查询是指:输入框中输入地名.人名等查询信息后,地图上可 ...
- lucene分词器与搜索
一.分词器 lucene针对不同的语言和虚伪提供了许多分词器,我们可以针对应用的不同的需求使用不同的分词器进行分词.我们需要注意的是在创建索引时使用的分词器与搜索时使用的分词器要保持一致.否则搜索的结 ...
- 全文索引(三)lucene 分词 Analyzer
分词: 将reader通过阅读对象Analyzer字处理,得到TokenStream处理流程被称为分割. 该解释可能是太晦涩.查看示例,这个东西是什么感性的认识. 样品:一段文本"this ...
- lucene分词多种方法
目前最新版本的lucene自身提供的StandardAnalyzer已经具备中文分词的功能,但是不一定能够满足大多数应用的需要.另外网友谈的比较多的中文分词器还有:CJKAnalyzerChinese ...
- Lucene分词详解
分词和查询都是以词项为基本单位,词项是词条化的结果.在Lucene中分词主要依靠Analyzer类解析实现.Analyzer类是一个抽象类,分词的具体规则是由子类实现的,所以对于不同的语言规则,要有不 ...
- 学习笔记(三)--Lucene分词器详解
Lucene-分词器API org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分词处理的TokenStream(分词处理 ...
随机推荐
- Ubuntu16.04安装vim插件YouCompleteMe
原文 1 下载 git clone --recursive git://github.com/Valloric/YouCompleteMe 如果执行该命令没报错, 就ok了. 但是中途有可能会断掉, ...
- Windows Server 2008 任务计划无法自动运行的解决办法
问题:编写的bat脚本,直接执行,成功:但是在任务管理器中配置该任务,运行不成功,结果显示为:0x1,系统环境为 Windows Server 2008. 分析:bat任务没有调用执行. 解决方案: ...
- noi 1.5 45:金币
描述 国王将金币作为工资,发放给忠诚的骑士.第一天,骑士收到一枚金币:之后两天(第二天和第三天)里,每天收到两枚金币:之后三天(第四.五.六天)里,每天收到三枚金币:之后四天(第七.八.九.十天)里, ...
- PO VO BO DTO POJO DAO(转)
2EE开发中大量的专业缩略语很是让人迷惑, 特别是对于刚毕业的新人来说更是摸不清头脑.若与公司大牛谈技术人家出口就是PO VO BO DTO POJO DAO 等,让新人们无比仰慕大牛. PO(bea ...
- swift基础:第一部分:基本数据类型及结构
首先谈点开心的:今天是周二,广州的天气格外明朗,早上上班的心情也不一样,最值得高兴事,很快到五一劳动节了,说到劳动节,放假是吧.你懂的.再来谈谈我上周的工作总结,上周可以说是黑轮压城城欲摧,甲光向日金 ...
- c#学习 流程控制语句
语句是啥? 语句就是程序的基本结构.程序是一个人,语句就是人的身体.而写程序的人就是上帝造人的过程. break在swich语句中很严谨 using System; public class Grad ...
- php 读取输出其他文件的方法
ob_start();iconv('utf-8','gb2312',readfile('1.html')); //直接输出文本内容echo '<hr>'; $data = file_get ...
- 在Ubuntu14.04_ROS_indigo上安装Kinect2驱动和bridge
小乌龟:大乌龟,你这两周干么呢? 大乌龟:在Ubuntu14.04 ROS_indigo上装Kinect2的驱动和bridge 小乌龟:就装个驱动有什么难的 大乌龟:你说的对小乌龟,这确实不是问题,但 ...
- java第六次作业
一个抽奖程序:用ArrayList类和random类 import java.awt.*; import javax.swing.*; import java.awt.event.; import j ...
- 精益化设计:把敏捷方法和Lean UX相结合
敏捷方法已经成为了主流.同时,Kindle和iPhone等设备取得的巨大成功也推动了体验设计的飞速发展.不过,如何把敏捷方法和UX设计结合起来,一直以来都是一个难题.文章将探讨如何把UX融入到最流行的 ...